
In the rapidly evolving landscape of artificial intelligence and machine learning, two roles stand out as central to the process of extracting value from data and building intelligent applications: the Data Scientist and the Machine Learning Engineer. While both professions are highly sought after and operate within the same overarching domain, the specific nature of their work, their core responsibilities, and the primary skill sets they leverage are distinct. This distinction, though sometimes blurred in practice, is crucial for understanding the mechanics of a successful data science and machine learning workflow and for individuals aspiring to enter these fields.
The confusion between these roles is understandable. Both work with data, both utilize algorithms, and both aim to create solutions that enable machines to learn and make decisions. In many organizations, particularly startups or those just beginning their AI journey, a single individual might indeed perform tasks that technically fall under both umbrellas. However, as machine learning initiatives grow in complexity, scale, and importance, the need for specialized expertise becomes paramount, leading to a clearer delineation of responsibilities between Data Scientists and Machine Learning Engineers.
This article aims to provide a comprehensive clarification of these two critical roles. We will delve into the typical day-to-day activities, the essential skills, and the primary focus areas for both Data Scientists and ML Engineers. By highlighting their distinct contributions and the points where their work intersects, we hope to offer a clearer picture of the machine learning lifecycle and help individuals understand which path might align best with their interests and capabilities. Understanding this difference is not just about job titles; it’s about recognizing the different phases and requirements involved in transforming raw data into impactful, production-ready AI solutions.
The Data Scientist: The Explorer, Analyst, and Model Architect
The Data Scientist is often at the forefront of the discovery phase in a data-driven project. Their role is deeply rooted in understanding the data, identifying patterns, formulating hypotheses, and building the initial analytical models that can reveal insights or predict future outcomes. They are the bridge between raw information and actionable knowledge, often working closely with business stakeholders to translate real-world problems into questions that can be answered using data and statistical or machine learning techniques.
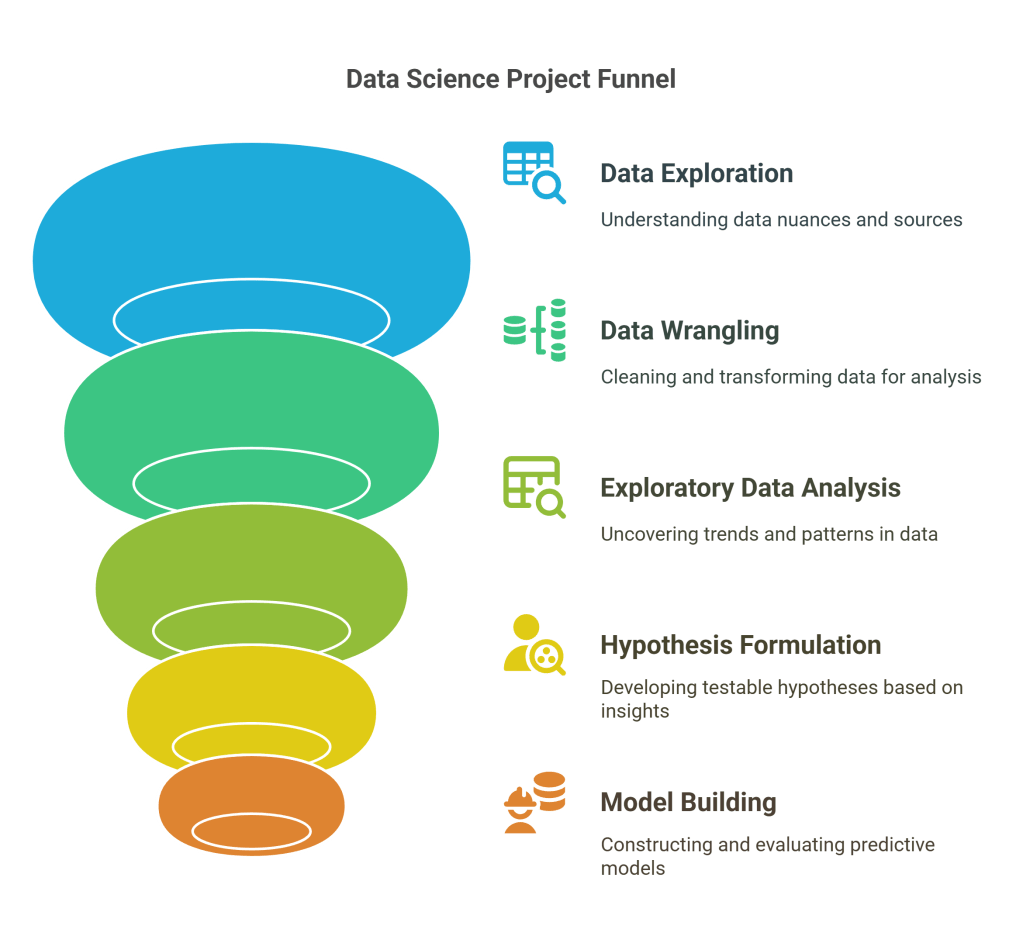
A Data Scientist’s work typically begins with a problem or an opportunity identified by the business. Their first step is rarely writing production code; it’s about exploration. This involves collaborating with domain experts to truly grasp the nuances of the business problem. They then dive into data, which is often messy, incomplete, and scattered across various sources. A significant portion of a Data Scientist’s time is dedicated to data cleaning, transformation, and preprocessing – a vital, albeit sometimes tedious, step known as “data wrangling.” This ensures the data is in a usable format for analysis and modeling.
Once the data is clean, the Data Scientist engages in extensive exploratory data analysis (EDA). Using statistical methods, data visualization tools, and scripting languages like Python or R, they look for trends, correlations, outliers, and distributions. This phase is crucial for understanding the data’s characteristics, identifying potential features for modeling, and gaining initial insights into the problem. They are essentially interrogating the data, asking questions to uncover hidden patterns and relationships.
Based on their findings from EDA and their understanding of the problem, the Data Scientist formulates hypotheses. For example, if the problem is customer churn, a hypothesis might be: “Customers who have interacted with customer support multiple times in the last month are more likely to churn.” They then use statistical tests or build preliminary models to validate or refute these hypotheses.
Model building is a core responsibility. Data Scientists select appropriate machine learning algorithms (e.g., linear regression, logistic regression, decision trees, clustering algorithms) based on the problem type (regression, classification, clustering, etc.) and the characteristics of the data. They split the data into training and testing sets, train the chosen models, tune hyperparameters to optimize performance, and evaluate the models using relevant metrics (accuracy, precision, recall, F1-score, RMSE, etc.). This process is often iterative, involving trying multiple algorithms and refining the approach based on evaluation results. Their goal here is to build a model that performs well on the task and provides meaningful insights.
Beyond just building models, Data Scientists are responsible for interpreting the results. What do the model’s coefficients mean? Which features are most important for the prediction? What are the limitations of the model? Translating these technical findings into understandable language for non-technical stakeholders is a critical skill. Data Scientists often create compelling visualizations and presentations to communicate their insights, model performance, and recommendations, helping the business make informed decisions based on the data.
Their deliverables at this stage are typically insights, reports, interactive dashboards, Jupyter Notebooks containing the analysis and model code, and prototype models. These outputs serve as the foundation for potential production-level implementation, but the Data Scientist’s primary focus is on the analytical depth, the validity of the findings, and the performance of the model in a controlled evaluation environment, rather than its scalability or integration into complex software systems. They are the explorers who chart the territory and build the initial blueprints for data-driven solutions.
The Machine Learning Engineer: The Architect of Production Systems
The Machine Learning Engineer takes the validated models and analytical insights developed by the Data Scientist and transforms them into robust, scalable, and reliable production systems. While the Data Scientist focuses on the ‘what’ and ‘why’ of the model and data, the ML Engineer focuses on the ‘how’ of making that model work effectively and efficiently in a real-world operational environment. They are essentially specialized software engineers with a deep understanding of machine learning concepts and the unique challenges involved in deploying and managing ML models at scale.
The ML Engineer’s work typically begins when the Data Scientist has developed a prototype model that shows promise and has been deemed valuable for deployment. The ML Engineer’s first task might be to refactor the Data Scientist’s prototype code, making it more production-ready – adhering to software engineering best practices like modularity, testability, and performance optimization. While Data Scientists might work primarily in interactive environments like Jupyter Notebooks, ML Engineers work with integrated development environments (IDEs) and focus on building production-grade code.
A core responsibility of the ML Engineer is building and maintaining the data pipelines that feed the production models. Unlike the data cleaning done by a Data Scientist for a specific analysis, production pipelines need to be automated, scalable, reliable, and handle streaming or batch data ingestion continuously. This involves using tools and technologies for data ETL (Extract, Transform, Load), working with databases (both relational and NoSQL), and leveraging big data processing frameworks like Apache Spark or Flink if dealing with large volumes of data.
Model deployment is a central task. ML Engineers are responsible for integrating the trained model into existing applications, websites, or services. This might involve creating APIs (Application Programming Interfaces) that allow other parts of the system to interact with the model for making predictions (inference). They need to consider factors like latency (how quickly the model responds), throughput (how many requests it can handle), and resource utilization. Deploying models often involves using technologies like Docker for containerization and Kubernetes for orchestration, especially in cloud environments (AWS, Google Cloud, Azure).

The field of MLOps (Machine Learning Operations) is heavily within the ML Engineer’s domain. MLOps encompasses the practices and tools for managing the entire machine learning lifecycle in production. This includes setting up systems for:
- Model Monitoring: Tracking model performance in the production environment to detect issues like concept drift (when the relationship between features and the target variable changes over time) or data drift (when the characteristics of the input data change).
- Model Retraining: Establishing automated pipelines for regularly retraining models on new data to maintain accuracy.
- Model Versioning: Managing different versions of models and experiments.
- Automated Deployment: Implementing CI/CD (Continuous Integration/Continuous Deployment) pipelines specifically for machine learning models.

Subscribe to continue reading
Subscribe to get access to the rest of this post and other subscriber-only content.
