
In today’s rapidly evolving artificial intelligence landscape, Retrieval-Augmented Generation (RAG) has emerged as a cornerstone technology that bridges the gap between static knowledge and dynamic generation capabilities. As organizations seek more reliable, accurate, and context-aware AI systems, understanding the various RAG implementation patterns has become crucial for developers, researchers, and business leaders alike. This article explores six essential RAG patterns that are defining the next generation of intelligent systems.
Understanding the RAG Revolution
Retrieval-Augmented Generation represents a paradigm shift in how AI systems access and utilize information. Traditional language models are limited to the knowledge embedded in their parameters during training, creating challenges with factual accuracy, knowledge freshness, and context-specific information. RAG addresses these limitations by enabling models to retrieve relevant information from external knowledge sources before generating responses.
The core principle behind RAG is elegant yet powerful: rather than expecting a language model to memorize all possible information, the system retrieves relevant documents or data points from a knowledge base and uses them to inform and enhance the generation process. This approach offers several significant advantages:
- Improved factual accuracy: By grounding responses in retrieved documents, RAG systems can provide more accurate information.
- Knowledge freshness: External knowledge bases can be updated continuously, ensuring the model has access to current information.
- Transparency: The retrieval process creates a clear source of information, making the system’s outputs more explainable.
- Domain adaptation: Organizations can customize their knowledge bases for specific domains without retraining entire models.
- Reduced hallucination: By anchoring generation in retrieved facts, models are less likely to fabricate information.
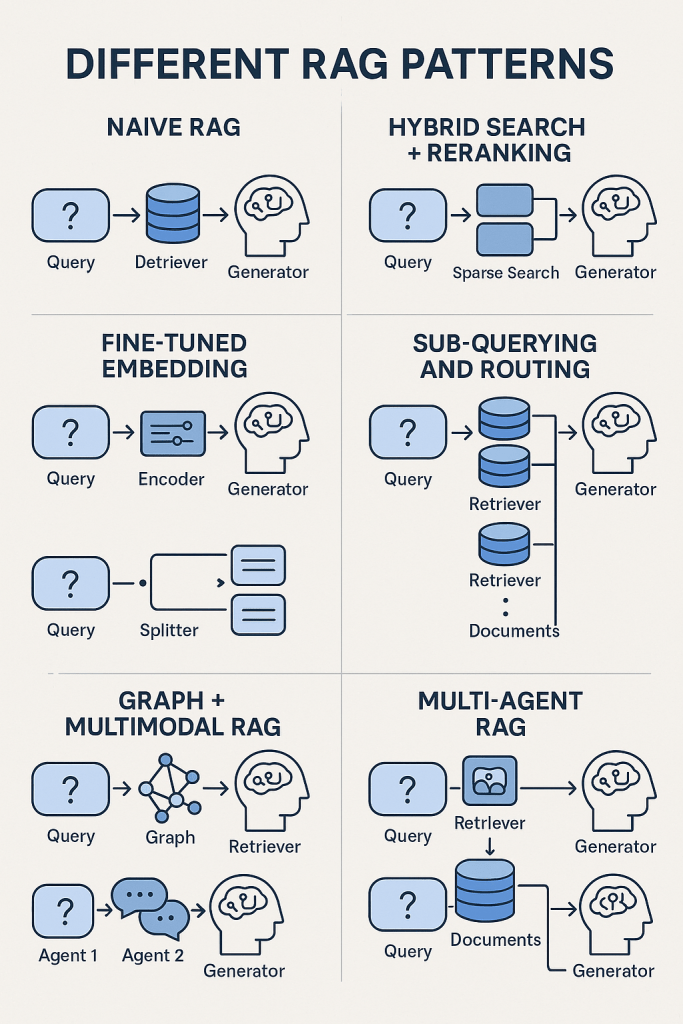
As this technology has matured, distinct implementation patterns have emerged, each with its own strengths and appropriate use cases. Let’s explore the six essential RAG patterns that are transforming AI systems today.
Naive RAG
The Foundation of RAG Implementation
Naive RAG represents the most straightforward implementation of the retrieval-augmented generation concept. In this pattern, the process follows a linear flow:
- The user submits a query or prompt.
- The system performs a similarity search against an indexed document collection.
- The most relevant documents are retrieved.
- These documents, along with the original query, are provided to the language model.
- The model generates a response informed by both the query and the retrieved context.
While conceptually simple, Naive RAG delivers significant improvements over basic language model approaches. The retrieval component functions as an augmented memory system, allowing the model to access information beyond its training data. This is particularly valuable for domain-specific applications where the model might not have been extensively trained on relevant content.
Implementation Considerations
For organizations implementing Naive RAG, several key considerations come into play:
- Indexing strategy: How documents are processed, chunked, and indexed significantly impacts retrieval quality.
- Embedding selection: The choice of embedding model determines how effectively semantic similarity can be measured.
- Prompt engineering: Constructing effective prompts that incorporate retrieved information is crucial for quality outputs.
- Retrieval parameters: Decisions around how many documents to retrieve and how to rank them affect both performance and accuracy.
Despite its simplicity, Naive RAG often serves as an excellent starting point for organizations beginning their RAG journey. Its straightforward implementation provides immediate benefits while establishing the foundation for more sophisticated approaches.
Limitations and Challenges
While powerful, Naive RAG has limitations that more advanced patterns address:
- The retrieval process may miss relevant information if semantic search fails to identify appropriate documents.
- There’s no mechanism to verify or re-rank the retrieved documents based on their actual relevance to the query.
- Complex queries that require information from multiple sources may not be handled optimally.
- The system lacks the ability to reformulate queries or explore different retrieval strategies.
Hybrid Search + Reranking
Enhancing Retrieval Quality
Hybrid Search + Reranking builds upon the Naive RAG pattern by implementing a more sophisticated retrieval strategy. This pattern recognizes that different search methods have complementary strengths and that initial retrieval results can be significantly improved through intelligent reranking.
The process typically follows these steps:
- The user submits a query.
- The system executes multiple search strategies in parallel:
- Semantic search using embedding similarities
- Keyword-based search for exact matches
- Additional specialized search methods as appropriate
- Results from these various search methods are combined.
- A reranking model evaluates and reorders the retrieved documents based on their relevance to the query.
- The top-ranked documents are passed to the language model along with the query.
- The model generates a comprehensive response based on this enhanced context.
The Power of Multiple Retrieval Methods
The hybrid approach addresses a fundamental challenge in information retrieval: different types of queries benefit from different retrieval strategies. For example:
- Semantic search excels at finding conceptually related content even when exact keywords are missing.
- Keyword search performs well for specific terms, names, or identifiers.
- Specialized searchers can handle structured data, temporal information, or numerical comparisons.
By combining these approaches, Hybrid Search significantly improves recall—the ability to find all relevant documents—while the reranking step enhances precision by ensuring the most relevant documents are prioritized.
Reranking: The Critical Differentiator
The reranking component represents one of the most impactful enhancements to basic RAG systems. Rerankers are typically designed to perform a more computationally intensive but accurate relevance assessment than the initial retrieval system. Modern rerankers often employ:
- Cross-attention between queries and documents rather than simple vector comparisons
- Consideration of document structure and position of relevant information
- Assessment of information density and content quality
- Evaluation of factual consistency with the query
Specialized reranking models like ColBERT, MonoT5, or custom fine-tuned transformers have demonstrated significant improvements in retrieval quality, directly translating to better generated outputs.
Implementation Challenges
While powerful, Hybrid Search + Reranking introduces additional complexity:
- Managing multiple search indices and keeping them synchronized
- Balancing the computational cost of reranking against performance requirements
- Effectively weighting and combining results from different search methods
- Tuning the system to account for different query types
Organizations implementing this pattern must carefully consider these trade-offs based on their specific requirements for accuracy, latency, and computational resources.
Fine-Tuned Embedding
Customizing the Semantic Space
The Fine-Tuned Embedding pattern focuses on enhancing the fundamental building block of retrieval: the embedding model. While general-purpose embedding models provide a solid foundation, domain-specific data often contains unique semantic relationships that generic models might not capture optimally.
This pattern involves:
- Collecting domain-specific data pairs (queries and relevant documents).
- Fine-tuning a pre-trained embedding model on these pairs.
- Using the fine-tuned embeddings to index the document collection.
- At query time, encoding the user input with the same fine-tuned model.
- Retrieving documents based on similarity in this customized embedding space.
- Providing the retrieved documents and query to the language model for response generation.
The Value of Domain Adaptation
Fine-tuned embeddings offer several significant advantages:
- Domain-specific semantic understanding: The model learns the unique vocabulary and relationships within a specific knowledge domain.
- Improved similarity matching: Fine-tuning can better distinguish between subtle differences that matter in particular contexts.
- Query-document alignment: Training on query-document pairs helps the model understand how user questions relate to document content.
- Reduced dimensionality challenges: Domain-specific embeddings can be more efficient at representing relevant concepts.
Organizations with specialized knowledge domains—like legal, medical, technical, or scientific fields—often find this pattern particularly valuable. The custom embedding space becomes a powerful asset for precision retrieval within that domain.
Implementation Approaches
Several methods exist for fine-tuning embedding models:
- Contrastive learning: Training the model to minimize distance between related query-document pairs while maximizing distance for unrelated pairs.
- Domain-adaptive pre-training: Further pre-training an embedding model on domain-specific corpus before fine-tuning.
- Supervised fine-tuning: Using explicit relevance labels to guide the embedding optimization.
- Distillation: Training a smaller, more efficient model to mimic the behavior of a larger, more powerful one.
Recent advances in embedding training techniques like HyDE (Hypothetical Document Embeddings) and MTEB (Massive Text Embedding Benchmark) have further enhanced the effectiveness of this approach.
Challenges and Considerations
The Fine-Tuned Embedding pattern requires:
- Sufficient domain-specific training data
- Computational resources for fine-tuning
- Processes for regularly updating and maintaining the custom models
- Evaluation frameworks to measure embedding quality in the specific domain
Despite these challenges, the significant improvements in retrieval quality often justify the investment for organizations with specialized information needs.
Sub-Querying and Routing
Decomposing Complex Questions
The Sub-Querying and Routing pattern acknowledges that many real-world queries are complex and multi-faceted, requiring information from different sources or knowledge domains. Rather than treating every query as a single unit, this pattern:
- Analyzes the user query to identify sub-questions or components.
- Generates multiple specialized sub-queries targeting specific aspects of the original question.
- Routes each sub-query to appropriate data sources or specialized retrievers.
- Collects and synthesizes information from these various sources.
- Provides the comprehensive context to the language model for response generation.
This approach is particularly valuable for questions that require synthesizing information across different domains or documents. For example, a query like “Compare the financial performance of renewable energy companies to oil companies in the context of recent climate legislation” might generate sub-queries about:
- Financial metrics for renewable energy companies
- Performance data for oil and gas companies
- Details about recent climate legislation
- Analysis of industry trends and regulatory impacts
Query Rewriting: The Intelligence Layer
The query rewriting component in this pattern serves as an intelligence layer that:
- Identifies implicit and explicit information needs
- Expands ambiguous queries with specific details
- Reformulates queries to match the retrieval system’s strengths
- Determines which data sources are most appropriate for each sub-query
Modern implementations often use language models themselves for this query decomposition step, applying techniques like:
- Few-shot learning with examples of effective query decomposition
- Chain-of-thought prompting to make the reasoning process explicit
- Self-critique and refinement of generated sub-queries
Data Source Diversity
The routing component of this pattern enables leveraging diverse data sources:
- Document collections with different structures or formats
- Specialized databases or knowledge graphs
- Structured data sources with query interfaces
- External APIs or services that provide complementary information
This diversity of sources enables more comprehensive information gathering than would be possible through a single retrieval mechanism.
Challenges in Implementation
Effectively implementing Sub-Querying and Routing requires addressing several challenges:
- Determining the appropriate level of query decomposition
- Maintaining context across sub-queries to avoid redundancy
- Resolving conflicts or inconsistencies in retrieved information
- Managing latency with multiple sequential or parallel retrieval operations
- Synthesizing information coherently in the final response
Despite these challenges, this pattern’s ability to handle complex, multi-faceted queries makes it increasingly essential for advanced RAG systems.
Graph + Multimodal RAG
Beyond Text: Enriching Context with Relationships and Multiple Modalities
The Graph + Multimodal RAG pattern represents a significant evolution that addresses two key limitations of traditional RAG approaches:
- Standard document retrieval fails to capture explicit relationships between entities and concepts
- Text-only retrieval misses valuable information encoded in images, audio, video, and other formats
This pattern integrates:
- Knowledge graphs that represent entities and their relationships
- Multimodal content including images, diagrams, audio, and video
- Specialized encoders for different content types
- Unified retrieval mechanisms that can traverse both structured and unstructured data
Knowledge Graph Integration
Knowledge graphs provide crucial advantages in a RAG system:
- Entity-centric representation: Information is organized around entities (people, organizations, products, concepts) rather than documents.
- Explicit relationships: Connections between entities are clearly defined, enabling relationship-based retrieval.
- Hierarchical structures: Taxonomies and ontologies can represent conceptual hierarchies.
- Inference capabilities: Graph traversal can discover implicit connections not explicitly stated in any single document.
When a query is received, the system can identify relevant entities, traverse their connections, and retrieve associated content from multiple sources. This approach is particularly powerful for questions involving relationships, comparisons, or tracing connections between concepts.
Multimodal Understanding
The multimodal component enables working with diverse content types:
- Images and diagrams: Visual information often communicates concepts more effectively than text alone.
- Audio and video: Transcripts, speaker information, and temporal metadata add rich context.
- Structured data: Tables, charts, and datasets contain valuable quantitative information.
- Specialized formats: Domain-specific formats like chemical structures, genomic sequences, or CAD models.
Multimodal encoders transform these diverse formats into compatible representations that can be retrieved alongside text content. When generating responses, the language model can reference this multimodal context, creating more comprehensive and informative outputs.
Implementation Approaches
Organizations implementing this pattern typically:
- Develop or adapt specialized encoders for each content type
- Create mechanisms to extract and represent relationships between entities
- Implement unified retrieval systems that can work across modalities
- Enhance prompt engineering to effectively utilize diverse content types
- Design response formats that can reference or incorporate multimodal information
Recent advances in multimodal language models have made this pattern increasingly accessible, as these models can naturally process and generate content that references multiple modalities.
Challenges and Considerations
The Graph + Multimodal RAG pattern presents several implementation challenges:
- Creating and maintaining knowledge graphs requires significant investment
- Handling different modalities requires specialized processing pipelines
- Unifying retrieval across diverse representations is technically complex
- Determining how to present multimodal context in prompts
- Managing the increased computational requirements
Despite these challenges, the rich contextual understanding enabled by this pattern makes it valuable for applications requiring deep domain understanding and comprehensive information synthesis.
Multi-Agent RAG
Distributed Intelligence for Complex Information Tasks
The Multi-Agent RAG pattern represents the most sophisticated approach to retrieval-augmented generation, leveraging multiple specialized agents that work together to process queries, retrieve information, and generate responses. This pattern embraces the concept of “agentic RAG,” where components have autonomous capabilities and collaborate toward a common goal.
The typical architecture includes:
- Query Planning Agent: Analyzes the user’s question and develops a strategy for answering it.
- Retrieval Agent: Specializes in finding and evaluating relevant information sources.
- Generator Agent: Creates comprehensive responses based on retrieved information.
- Response Judge: Evaluates response quality and provides feedback for improvement.
These agents communicate and coordinate, often in multiple rounds, to refine both the retrieval process and the generated response.
The Power of Specialization and Collaboration
The multi-agent approach offers several significant advantages:
- Specialized expertise: Each agent can focus on optimizing a specific part of the process.
- Iterative refinement: Agents can provide feedback to each other to improve results.
- Transparent workflow: The system’s “thinking process” becomes visible through agent interactions.
- Adaptability: Different agent configurations can be deployed based on query complexity.
This approach is particularly valuable for complex information needs that require strategic planning, multiple retrieval strategies, and careful synthesis of diverse information.
Implementation Approaches
Organizations implementing Multi-Agent RAG typically:
- Define clear responsibilities and interfaces for each agent
- Develop communication protocols between agents
- Create mechanisms for feedback and refinement
- Implement orchestration systems to manage the overall workflow
- Design evaluation metrics for both individual agents and the system as a whole
Recent developments in agent frameworks and orchestration tools have made this pattern more accessible, though it still represents the cutting edge of RAG implementation.
Challenges and Considerations
The Multi-Agent RAG pattern introduces several important challenges:
- Significantly greater implementation complexity
- Increased computational requirements
- More complex debugging and troubleshooting
- Potential for increased latency with multiple interaction rounds
- Need for careful system design to ensure agent alignment
Despite these challenges, Multi-Agent RAG represents the frontier of retrieval-augmented generation, enabling systems that can handle extraordinarily complex information needs with human-like strategic thinking and collaboration.
The Future of RAG: Convergence and Customization
As RAG systems continue to evolve, we’re seeing two parallel trends:
- Pattern convergence: Organizations increasingly combine elements from multiple patterns to create hybrid approaches tailored to their specific needs.
- Vertical specialization: RAG systems are being optimized for specific domains like legal, medical, financial, and scientific applications.
Several emerging developments are shaping the future of RAG:
Self-Improving Systems
Modern RAG implementations are increasingly incorporating feedback loops that enable continuous improvement:
- Tracking which retrieved documents lead to helpful responses
- Identifying queries where retrieval fails to provide relevant information
- Automatically generating synthetic training data for embedding fine-tuning
- Learning optimal prompt formats based on user interactions
These self-improving mechanisms allow RAG systems to become increasingly effective over time without constant manual tuning.
Context Compression and Distillation
As retrieval systems become more comprehensive, they often retrieve more information than can be effectively processed within model context windows. Advanced RAG systems are adopting sophisticated approaches to context management:
- Adaptive retrieval that adjusts the amount of context based on query complexity
- Context distillation techniques that extract and summarize key information
- Hierarchical context representation with progressive levels of detail
- Long-context models that can process extended retrieval results
These techniques help bridge the gap between the vast amounts of potentially relevant information and the practical limitations of model processing.
Evaluation and Benchmarking
As RAG systems grow more complex, evaluation becomes increasingly important. The field is developing more sophisticated metrics beyond traditional precision and recall:
- Faithfulness: Assessing whether responses accurately reflect retrieved information
- Comprehensiveness: Evaluating if all relevant information has been incorporated
- Consistency: Checking for contradictions within responses
- Attribution quality: Measuring how well the system cites sources
- Efficiency: Balancing quality improvements against computational costs
Standardized benchmarks like RAGAS (Retrieval Augmented Generation Assessment) are emerging to facilitate consistent evaluation across different RAG implementations.
Conclusion: Choosing the Right RAG Pattern
The six RAG patterns described in this article—Naive RAG, Hybrid Search + Reranking, Fine-Tuned Embedding, Sub-Querying and Routing, Graph + Multimodal RAG, and Multi-Agent RAG—represent a spectrum of approaches with increasing sophistication and capabilities.
For organizations considering RAG implementation, several factors should guide pattern selection:
- Complexity of information needs: Simple factual queries may be well-served by Naive RAG, while complex analytical questions might require Multi-Agent approaches.
- Domain specificity: Highly specialized domains often benefit from Fine-Tuned Embeddings or Graph-based approaches.
- Available resources: More advanced patterns generally require greater computational resources and implementation effort.
- Latency requirements: Complex patterns with multiple processing steps may introduce additional latency.
- Scale of knowledge base: Larger or more diverse knowledge bases often require more sophisticated retrieval strategies.
Many organizations find value in starting with simpler patterns and progressively adopting more advanced techniques as they build expertise and identify specific limitations in their current implementations.
The rise of agentic RAG represents a fundamental shift in how AI systems interact with information—moving from passive knowledge consumers to active information seekers and synthesizers. As these technologies continue to evolve, they promise to dramatically enhance our ability to access, understand, and utilize the ever-expanding universe of human knowledge.
By understanding these essential RAG patterns, organizations can make informed choices about how to implement retrieval-augmented generation in ways that best serve their specific information needs and user requirements. The future belongs to systems that can seamlessly integrate the vast stores of human knowledge with the generative capabilities of advanced language models—and RAG is the bridge that makes this integration possible.
Discover more from SkillWisor
Subscribe to get the latest posts sent to your email.
