

Introduction
In today’s data-driven world, organizations across industries are leveraging massive amounts of information to gain competitive advantages, optimize operations, and create innovative products and services. This explosion of data has created tremendous demand for professionals who can collect, process, analyze, and derive value from data assets. However, the rapid evolution of data-related fields has led to overlapping job titles and confusion about the distinct responsibilities of various data professionals.
This comprehensive guide aims to clarify the differences between seven key data-related roles: Data Analysts, Data Scientists, Business Analysts, Data Engineers, Machine Learning Engineers, AI Engineers, and Generative AI Engineers. We’ll explore each role in depth, highlighting their unique responsibilities, required skill sets, typical workflows, educational backgrounds, career paths, and industry demand.
Whether you’re a student considering a career in data, a professional looking to pivot into this field, or an organization planning to build a data team, understanding these distinctions will help you navigate the complex landscape of data careers with confidence and clarity.
Table of Contents
- The Modern Data Ecosystem: An Overview
- Data Analyst: The Business Insights Specialist
- Data Scientist: The Advanced Analytics Expert
- Business Analyst: The Business-Technology Translator
- Data Engineer: The Data Infrastructure Builder
- Machine Learning Engineer: The Model Deployment Specialist
- AI Engineer: The Intelligent Systems Builder
- Generative AI Engineer: The Creative AI Specialist
- Side-by-Side Comparison of Data Roles
- Career Paths and Transitions Between Roles
- Educational Requirements and Learning Paths
- Industry Demand and Salary Expectations
- Choosing the Right Data Career Path For You
- The Future of Data Careers: Emerging Trends
- Conclusion
The Modern Data Ecosystem: An Overview
The data ecosystem has evolved significantly over the past decade, transforming from simple databases and basic analytics to complex distributed systems handling petabytes of structured and unstructured data. This evolution has necessitated specialization within data-related roles to address different aspects of the data lifecycle.
A modern data stack typically includes:
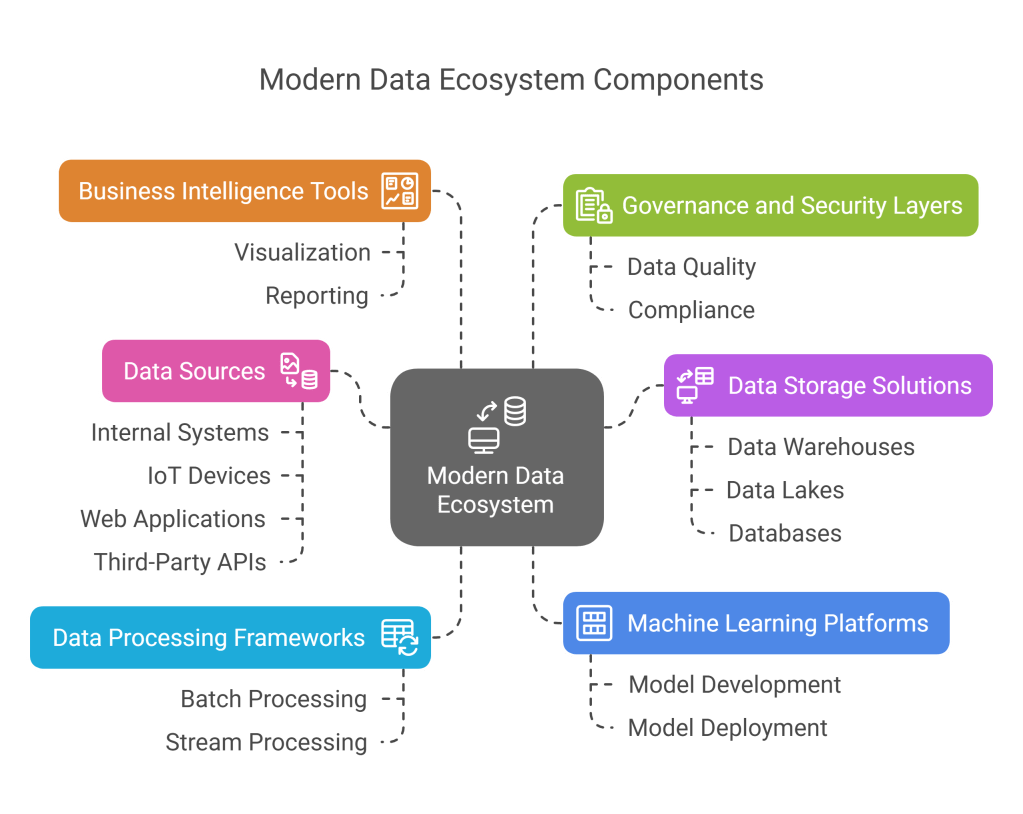
- Data sources: Internal systems, IoT devices, web applications, third-party APIs
- Data storage solutions: Data warehouses, data lakes, databases
- Data processing frameworks: Batch and stream processing tools
- Machine learning platforms: For developing and deploying predictive models
- Business intelligence tools: For visualization and reporting
- Governance and security layers: To maintain data quality and compliance
Each component requires specific expertise, and the professionals we’ll discuss are responsible for different parts of this ecosystem. Understanding how these roles fit into the broader data landscape is crucial for appreciating their distinct contributions.
Data Analyst: The Business Insights Specialist
Role Definition
Data Analysts transform raw data into meaningful business insights through collection, cleaning, analysis, and visualization. They focus on descriptive and diagnostic analytics, answering questions about what happened and why it happened based on historical data.
Required Skills
- Technical Skills: SQL, Excel, basic programming (Python/R), statistical analysis, data visualization tools (Tableau, Power BI)
- Statistical Knowledge: Descriptive statistics, hypothesis testing, correlation analysis
- Domain Knowledge: Understanding of business processes and metrics
- Soft Skills: Data storytelling, problem-solving, attention to detail
Detailed Day-to-Day Workflow
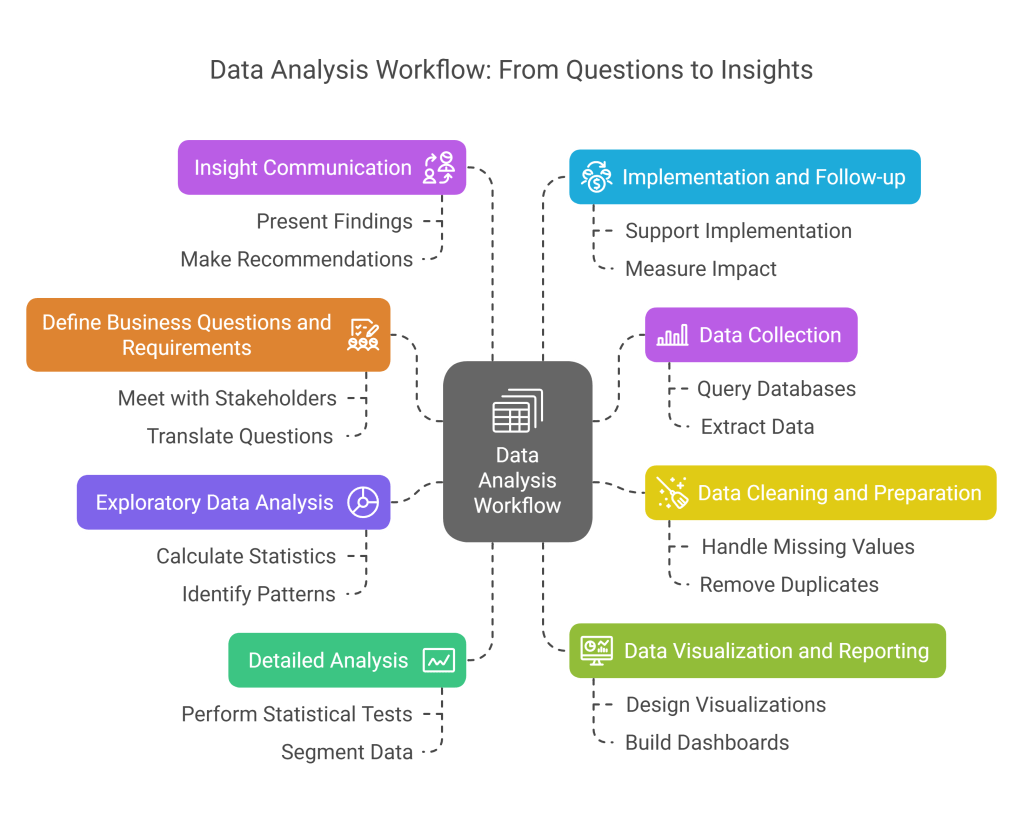
- Define Business Questions and Requirements
- Meet with stakeholders to understand their information needs
- Translate business questions into analytical problems
- Define key metrics and success criteria
- Identify relevant data sources
- Data Collection
- Query databases using SQL
- Extract data from business systems
- Import data from external sources
- Create data collection mechanisms when needed
- Data Cleaning and Preparation
- Identify and handle missing values
- Remove duplicates and outliers
- Standardize formats and units
- Create derived variables when necessary
- Merge datasets from different sources
- Exploratory Data Analysis
- Calculate summary statistics
- Identify patterns and trends
- Detect anomalies or unusual patterns
- Generate initial hypotheses
- Create exploratory visualizations
- Detailed Analysis
- Perform statistical tests
- Apply analytical techniques appropriate to the problem
- Segment data to uncover deeper insights
- Identify correlations and potential causal relationships
- Track key performance indicators over time
- Data Visualization and Reporting
- Design clear and compelling visualizations
- Build interactive dashboards
- Create automated reports
- Ensure visualizations tell a coherent story
- Annotate charts with key insights
- Insight Communication
- Present findings to stakeholders
- Translate technical findings into business language
- Make data-driven recommendations
- Document assumptions and methodologies
- Address questions and iterate based on feedback
- Implementation and Follow-up
- Support implementation of recommendations
- Establish monitoring mechanisms
- Measure impact of actions taken
- Refine analysis based on outcomes
Example Scenario
A retail company’s marketing team wants to understand customer purchasing patterns.
The Data Analyst:
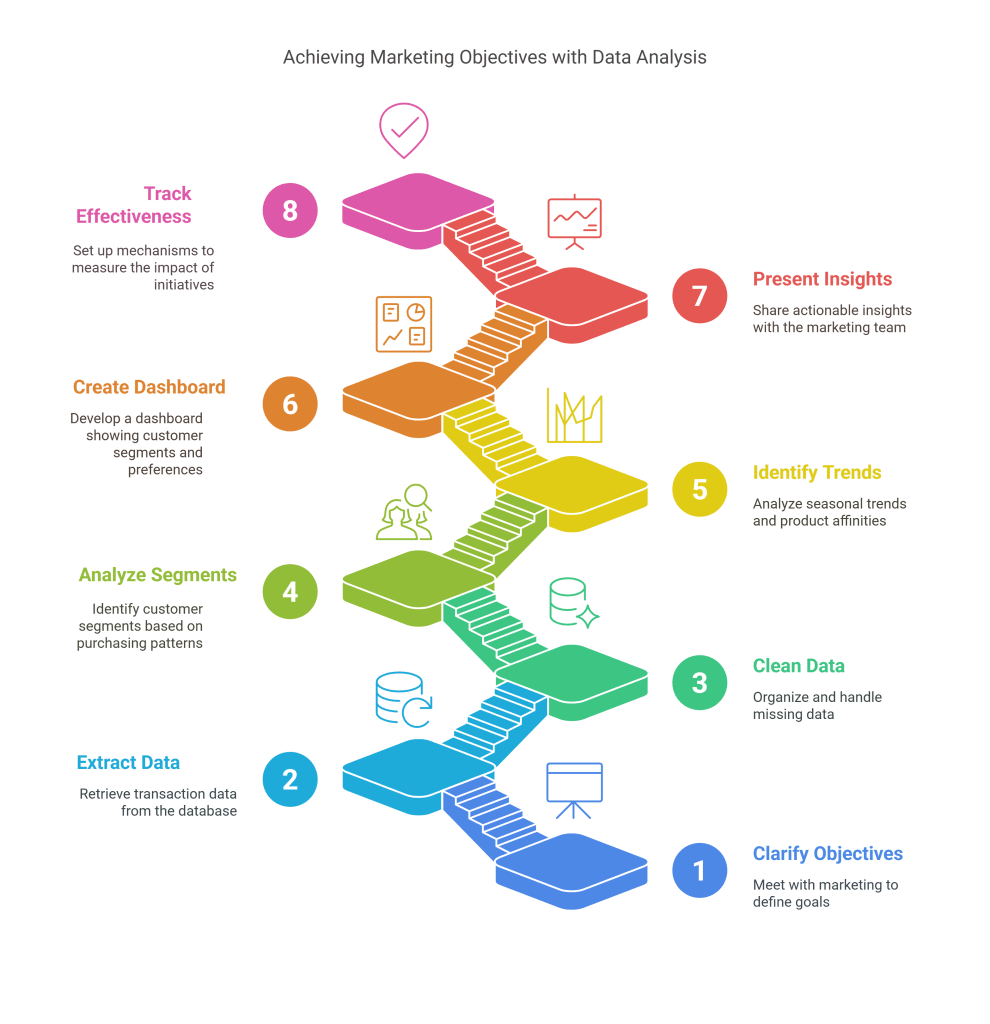
- Meets with marketing to clarify objectives (increasing repeat purchases)
- Extracts transaction data from the company’s database using SQL
- Cleans and organizes the data, handling missing information
- Conducts exploratory analysis to identify segments of customers based on purchasing frequency and average order value
- Analyzes seasonal trends and product affinities
- Creates a dashboard showing customer segments, their purchasing patterns, and product preferences
- Presents actionable insights to the marketing team with recommendations for targeted promotions
- Sets up tracking mechanisms to measure the effectiveness of the new marketing initiatives
Tools and Technologies

Data Scientist: The Advanced Analytics Expert
Role Definition
Data Scientists combine statistical analysis, programming, and domain expertise to extract insights from complex data and build predictive models. They focus on predictive and prescriptive analytics, forecasting future outcomes and recommending actions.
Required Skills
- Programming: Advanced Python/R, SQL
- Statistics and Mathematics: Probability, inferential statistics, linear algebra, calculus
- Machine Learning: Supervised and unsupervised learning algorithms, model evaluation
- Data Manipulation: Advanced data wrangling and feature engineering
- Big Data Technologies: Spark, Hadoop (basic understanding)
- Domain Expertise: Industry-specific knowledge
- Soft Skills: Critical thinking, research mindset, business acumen
Detailed Day-to-Day Workflow

- Problem Framing
- Collaborate with stakeholders to define business challenges
- Translate business problems into data science questions
- Assess feasibility and potential impact
- Define success metrics
- Plan analytical approach
- Data Acquisition and Understanding
- Identify required data sources
- Determine data quality and availability
- Extract data from databases, APIs, and other sources
- Perform initial exploratory data analysis
- Assess data limitations and biases
- Data Preparation and Feature Engineering
- Clean and preprocess data (handle missing values, outliers)
- Transform variables (normalization, encoding)
- Create derived features that enhance predictive power
- Perform dimensionality reduction if needed
- Split data into training, validation, and test sets
- Model Development
- Select appropriate algorithms based on the problem
- Train initial models with baseline performance
- Tune hyperparameters to optimize performance
- Implement cross-validation to prevent overfitting
- Evaluate models using appropriate metrics
- Iterate on model architecture and features
- Model Validation and Selection
- Test models on holdout data
- Compare performance across different algorithms
- Assess model robustness and generalization
- Analyze feature importance and model interpretability
- Select final model based on performance and business requirements
- Communication and Visualization
- Create visualizations to explain modeling results
- Prepare technical documentation of methodologies
- Translate complex findings into business insights
- Present results to technical and non-technical stakeholders
- Address questions and concerns
- Model Deployment Planning
- Collaborate with ML Engineers on deployment strategy
- Develop simplified versions for initial deployment
- Define monitoring metrics and thresholds
- Document model limitations and assumptions
- Create maintenance and updating procedures
- Continuous Improvement
- Monitor model performance over time
- Update models as new data becomes available
- Research and implement new methodologies
- Incorporate feedback into improved models
- Address model drift and changing business conditions
Example Scenario
An e-commerce company wants to reduce customer churn. The Data Scientist:

- Works with stakeholders to define “churn” and establish project goals
- Gathers historical customer data, including purchase history, website activity, and support interactions
- Cleans the data and creates features indicating engagement, satisfaction, and purchase patterns
- Develops multiple predictive models (logistic regression, random forest, gradient boosting) to identify customers likely to churn
- Evaluates models using precision, recall, and business impact
- Selects the most effective model and analyzes which factors most strongly predict churn
- Presents findings to management, highlighting key churn indicators and potential intervention points
- Works with ML Engineers to implement the model in production, continuously monitoring its performance
Tools and Technologies

- Programming languages: Python (NumPy, Pandas, Scikit-learn), R
- Machine learning frameworks: TensorFlow, PyTorch, scikit-learn
- Statistical tools: Statsmodels, SAS
- Big data processing: Spark, Hadoop
- Visualization: Matplotlib, Seaborn, ggplot2, Plotly
- Development environments: Jupyter Notebooks, RStudio
- Version control: Git, GitHub
Business Analyst: The Business-Technology Translator
Role Definition
Business Analysts bridge the gap between business stakeholders and technology teams, translating business needs into technical requirements and ensuring that technical solutions address business problems effectively.
Required Skills
- Business Domain Knowledge: Deep understanding of business processes and industry
- Requirements Analysis: Gathering and documenting business requirements
- Data Analysis: Basic statistical analysis and data interpretation
- Process Modeling: Flowcharts, UML, BPMN
- Project Management: Scope management, scheduling, risk assessment
- Technical Understanding: Sufficient knowledge to communicate with technical teams
- Soft Skills: Communication, facilitation, stakeholder management, problem-solving
Detailed Day-to-Day Workflow
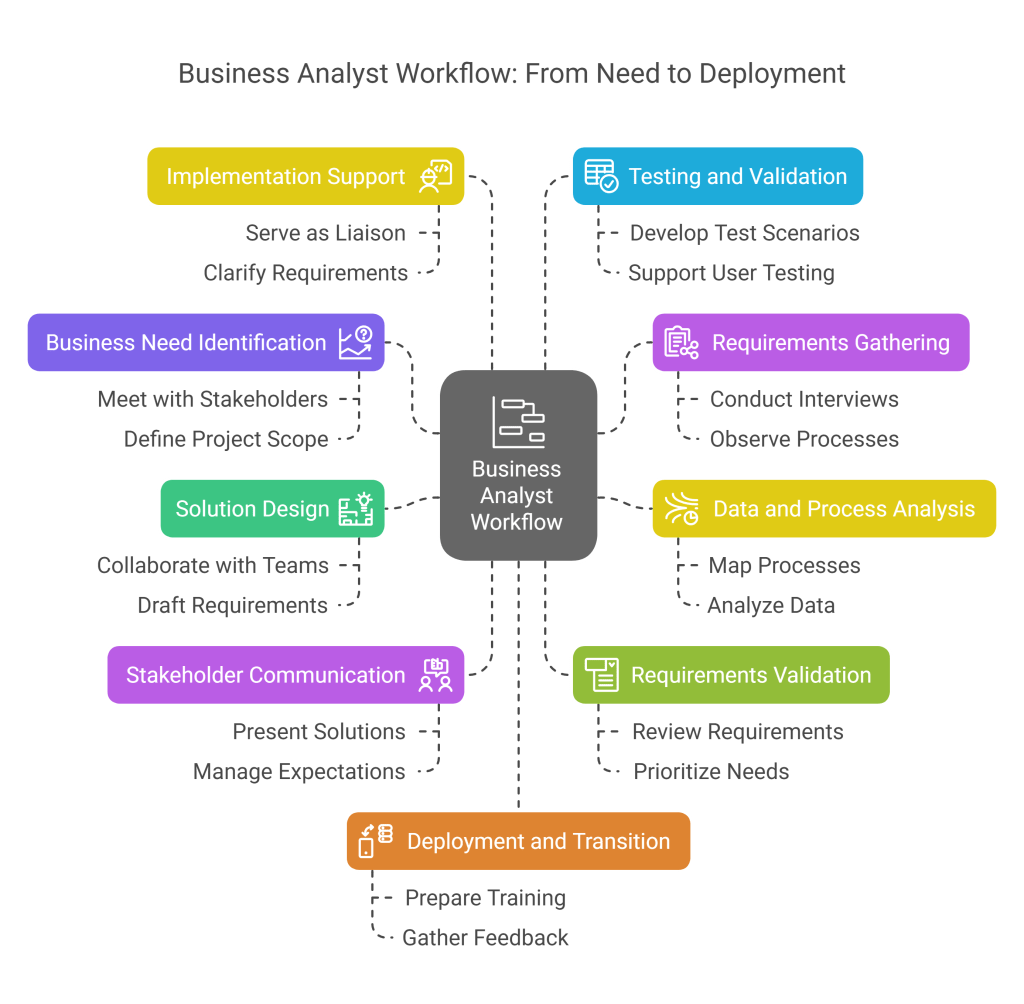
- Business Need Identification
- Meet with stakeholders to identify business problems or opportunities
- Define project scope and objectives
- Identify key stakeholders and their interests
- Document current state processes
- Establish project success criteria
- Requirements Gathering
- Conduct interviews and workshops with stakeholders
- Observe current processes and workflows
- Review existing documentation and systems
- Identify business rules and constraints
- Document functional and non-functional requirements
- Data and Process Analysis
- Map current processes using flowcharts or process diagrams
- Identify inefficiencies and pain points
- Analyze available data to understand the problem
- Identify potential causes of issues
- Benchmark against industry standards
- Solution Design
- Collaborate with technical teams to define potential solutions
- Develop process models for future state
- Draft business requirements documents (BRD)
- Create user stories or use cases
- Define acceptance criteria for solutions
- Stakeholder Communication
- Present proposed solutions to stakeholders
- Facilitate decision-making discussions
- Manage expectations regarding timelines and deliverables
- Document decisions and action items
- Ensure alignment between business and technical teams
- Requirements Validation
- Review requirements with stakeholders for accuracy
- Prioritize requirements based on business value
- Resolve conflicts between different stakeholder needs
- Refine requirements based on feedback
- Obtain formal sign-off on requirements
- Implementation Support
- Serve as liaison between business and development teams
- Clarify requirements for developers
- Review prototypes and demos
- Track development progress against requirements
- Manage scope changes and requirement updates
- Testing and Validation
- Develop test scenarios based on requirements
- Support user acceptance testing
- Validate that implemented solutions meet business needs
- Document defects and work with teams to resolve them
- Verify that acceptance criteria are met
- Deployment and Transition
- Prepare training materials and documentation
- Support change management activities
- Assist in transitioning to new processes
- Gather feedback from users post-implementation
- Evaluate project success against initial criteria
Example Scenario
A financial services company wants to streamline their loan approval process. The Business Analyst:
- Meets with loan officers, underwriters, and managers to understand current challenges
- Documents the current loan approval workflow, identifying bottlenecks
- Analyzes approval timelines and rejection reasons from historical data
- Creates detailed requirements for a new digital loan processing system
- Works with IT to develop user stories and acceptance criteria
- Facilitates meetings between business stakeholders and developers to ensure mutual understanding
- Reviews system prototypes and gathers feedback
- Supports testing and validation of the new system
- Helps develop training materials and monitors system adoption after launch
Tools and Technologies
- Business process modeling: Lucidchart, Microsoft Visio, BPMN tools
- Requirements management: JIRA, Trello, Azure DevOps
- Documentation: Confluence, SharePoint, Microsoft Office Suite
- Data analysis: Excel, SQL, Power BI (basic)
- Project management: Microsoft Project, Asana, Monday.com
- Collaboration: Microsoft Teams, Slack, Zoom
Data Engineer: The Data Infrastructure Builder
Role Definition
Data Engineers design, build, and maintain the infrastructure and systems that enable the collection, storage, and retrieval of data. They focus on creating scalable, reliable, and efficient data pipelines that transform raw data into formats suitable for analysis.
Required Skills
- Programming: Python, Java, Scala
- Database Systems: SQL and NoSQL databases
- Big Data Technologies: Hadoop ecosystem, Spark, Kafka
- Data Warehousing: Snowflake, BigQuery, Redshift
- ETL/ELT Processes: Data pipeline development
- Cloud Platforms: AWS, GCP, Azure
- DevOps Practices: CI/CD, infrastructure as code
- Data Modeling: Schema design, normalization concepts
Detailed Day-to-Day Workflow

- Requirements Analysis
- Meet with data consumers (analysts, scientists, business users)
- Understand data needs, volume, velocity, and variety
- Identify data sources and their characteristics
- Define SLAs for data freshness, availability, and quality
- Document technical requirements
- Data Architecture Design
- Design data storage architecture (data warehouse, data lake)
- Define schema and data models
- Plan for scalability and future growth
- Determine appropriate technologies and tools
- Create architecture diagrams and documentation
- Data Ingestion Pipeline Development
- Create connectors to source systems
- Develop batch or streaming data pipelines
- Implement error handling and logging
- Build monitoring for data flows
- Set up incremental loading mechanisms
- Data Transformation Development
- Create transformation logic (ETL/ELT processes)
- Implement data cleansing routines
- Build data enrichment processes
- Optimize transformation jobs for performance
- Ensure data consistency across systems
- Infrastructure Management
- Configure and maintain database systems
- Set up big data processing clusters
- Implement security measures and access controls
- Optimize resource allocation and utilization
- Manage cloud infrastructure costs
- Data Quality Assurance
- Implement data validation rules
- Create automated quality checks
- Set up alerting for data quality issues
- Develop remediation processes for bad data
- Document data lineage and metadata
- Performance Optimization
- Monitor pipeline performance metrics
- Identify and resolve bottlenecks
- Implement caching strategies
- Optimize queries and processing jobs
- Scale resources based on workload
- Collaboration and Documentation
- Work with cross-functional teams
- Document data pipelines and architecture
- Create and maintain technical documentation
- Transfer knowledge to team members
- Provide support for dependent systems
Example Scenario
A retail company needs to consolidate data from multiple sources for analytics. The Data Engineer:
- Meets with analysts and business teams to understand reporting needs
- Identifies relevant data sources (point-of-sale systems, inventory management, e-commerce platform, CRM)
- Designs a cloud-based data warehouse architecture with appropriate schemas
- Develops ETL pipelines to extract data from source systems and load it into the data warehouse
- Implements data quality checks to ensure accuracy and completeness
- Sets up incremental updates to maintain near real-time data
- Creates optimized views and tables for analytical queries
- Implements monitoring and alerting for pipeline failures
- Documents the entire system for other team members
Tools and Technologies

- ETL/ELT tools: Apache Airflow, AWS Glue, Informatica
- Big data processing: Apache Spark, Hadoop, Apache Flink
- Databases: PostgreSQL, MongoDB, Cassandra, MySQL
- Data warehousing: Snowflake, Amazon Redshift, Google BigQuery
- Stream processing: Apache Kafka, Amazon Kinesis
- Cloud platforms: AWS (S3, EC2, EMR), Google Cloud Platform, Microsoft Azure
- Infrastructure as code: Terraform, CloudFormation
- Containerization: Docker, Kubernetes
- Version control: Git, GitHub
Machine Learning Engineer: The Model Deployment Specialist
Role Definition
Machine Learning Engineers focus on taking machine learning models from development to production. They bridge the gap between data science and software engineering, building systems that can deploy, scale, and monitor machine learning models in real-world applications.
Required Skills
- Programming: Advanced Python, Java or Scala
- Software Engineering: System design, microservices architecture
- DevOps: CI/CD pipelines, containerization, orchestration
- Machine Learning: Understanding of ML algorithms and frameworks
- MLOps: Model versioning, monitoring, and management
- Cloud Services: ML-specific cloud services (SageMaker, Vertex AI)
- Performance Optimization: Model serving and scaling techniques
Detailed Day-to-Day Workflow
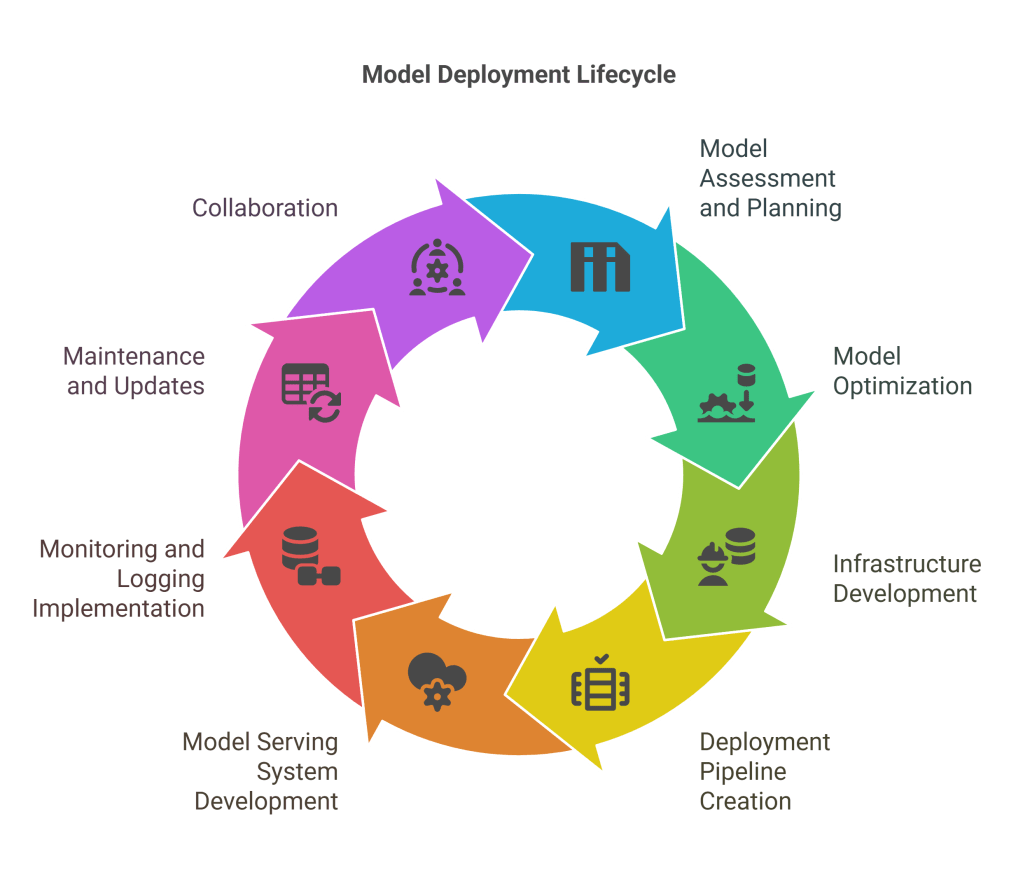
- Model Assessment and Planning
- Review models developed by data scientists
- Evaluate computational requirements
- Identify deployment constraints and challenges
- Define performance and reliability requirements
- Plan deployment architecture and strategy
- Model Optimization
- Refactor research code for production
- Optimize model performance (speed, memory usage)
- Implement model compression techniques if needed
- Convert models to optimized formats (ONNX, TensorRT)
- Benchmark different optimization approaches
- Infrastructure Development
- Set up model serving infrastructure
- Create containerized environments for models
- Develop APIs for model interaction
- Implement load balancing and auto-scaling
- Set up model registry and version control
- Deployment Pipeline Creation
- Build CI/CD pipelines for model deployment
- Implement automated testing for models
- Create rollback mechanisms
- Set up blue/green deployment strategies
- Develop deployment documentation
- Model Serving System Development
- Build prediction services and endpoints
- Implement request batching for efficiency
- Set up caching mechanisms
- Optimize request/response patterns
- Create client libraries if needed
- Monitoring and Logging Implementation
- Develop monitoring dashboards for model performance
- Implement logging for predictions
- Create alerting systems for model degradation
- Set up A/B testing infrastructure
- Develop performance reporting tools
- Maintenance and Updates
- Create model update procedures
- Implement shadow deployment for testing
- Manage model lifecycle and deprecation
- Handle backward compatibility issues
- Update documentation with each release
- Collaboration
- Work with data scientists on model improvements
- Coordinate with software engineers on integration
- Communicate with DevOps on infrastructure needs
- Report to product managers on capabilities and limitations
- Train team members on model deployment practices
Example Scenario
A financial company wants to deploy a fraud detection model in their transaction processing system. The Machine Learning Engineer:
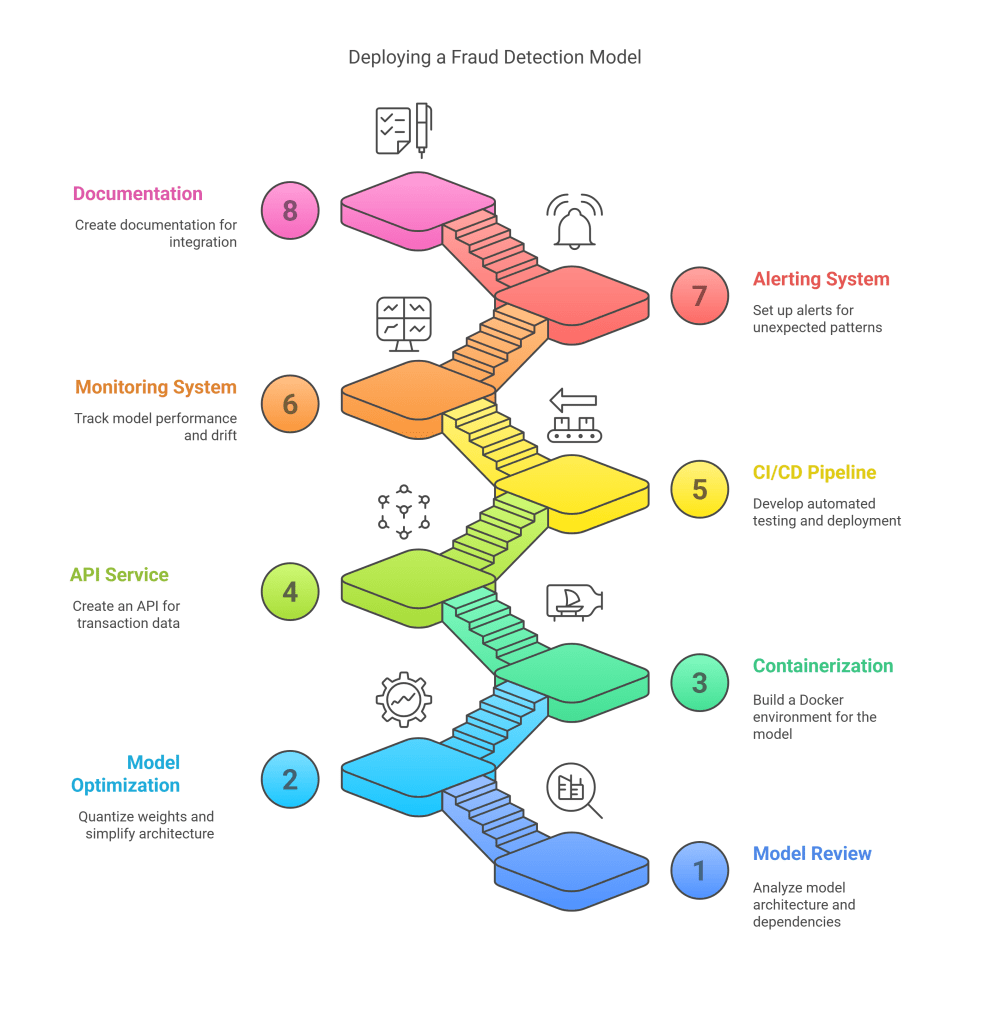
- Reviews the model built by data scientists, analyzing its architecture and dependencies
- Optimizes the model for low-latency inference by quantizing weights and simplifying architecture
- Builds a containerized environment for the model using Docker
- Creates an API service that accepts transaction data and returns fraud probability scores
- Develops a CI/CD pipeline that automatically tests and deploys model updates
- Implements a monitoring system that tracks model performance and drift
- Sets up alerting for unexpected prediction patterns or performance degradation
- Creates documentation for other engineers on how to integrate with the model service
Tools and Technologies
- ML frameworks: TensorFlow Serving, PyTorch, ONNX Runtime
- Model serving: TensorFlow Serving, Triton Inference Server, TorchServe
- Container orchestration: Kubernetes, Docker Swarm
- CI/CD tools: Jenkins, GitHub Actions, GitLab CI
- Model monitoring: Prometheus, Grafana, custom dashboards
- MLOps platforms: MLflow, Kubeflow, Seldon Core
- Cloud services: AWS SageMaker, Google Vertex AI, Azure Machine Learning
- Feature stores: Feast, Tecton, Hopsworks
AI Engineer: The Intelligent Systems Builder
Role Definition
AI Engineers design and implement intelligent systems that incorporate machine learning, deep learning, natural language processing, computer vision, and other AI technologies. They focus on building end-to-end AI applications that solve complex problems and provide business value.
Required Skills
- Programming: Python, JavaScript/TypeScript, C++
- Machine Learning: Deep learning frameworks, reinforcement learning
- AI Technologies: NLP, computer vision, speech recognition
- Software Engineering: System design, API development
- Cloud AI Services: Cognitive services, AI platforms
- Ethics and Responsible AI: Bias detection, fairness metrics
- Domain Expertise: Industry-specific knowledge
Detailed Day-to-Day Workflow

- Problem Understanding and Scoping
- Meet with stakeholders to understand business needs
- Define AI use cases and success criteria
- Assess technical feasibility
- Identify ethical considerations and constraints
- Create project roadmap and milestones
- Data Assessment and Preparation
- Evaluate available data sources and quality
- Identify data gaps and collection needs
- Plan data preprocessing pipeline
- Address data privacy and security requirements
- Collaborate with data engineers on data access
- AI System Architecture Design
- Design overall system architecture
- Select appropriate AI technologies and frameworks
- Plan integration with existing systems
- Define API contracts and data flows
- Create technical specifications and diagrams
- Model Development and Integration
- Develop or adapt AI models for specific use cases
- Train models with appropriate datasets
- Fine-tune models for performance and accuracy
- Integrate models with application logic
- Build connectors to data sources and downstream systems
- AI System Implementation
- Develop user interfaces for AI system interaction
- Implement business logic around AI components
- Create feedback mechanisms for model improvement
- Build data pipelines for continuous learning
- Develop explainability features for model decisions
- Testing and Validation
- Create test datasets and benchmarks
- Implement unit and integration tests
- Conduct adversarial testing for robustness
- Evaluate fairness across different user groups
- Perform end-to-end system testing
- Deployment and Integration
- Deploy AI system to production environment
- Integrate with enterprise systems
- Set up monitoring and logging
- Implement gradual rollout strategies
- Create user documentation and training materials
- Continuous Improvement
- Monitor system performance and user feedback
- Analyze failure cases and edge scenarios
- Update models with new data
- Implement feature enhancements
- Research and incorporate new AI techniques
Example Scenario
A healthcare provider wants to improve patient diagnosis through an AI assistant for physicians. The AI Engineer:

- Works with medical staff to understand diagnostic challenges and requirements
- Evaluates available medical data and ensures HIPAA compliance
- Designs a system architecture that integrates with electronic health records
- Develops and fine-tunes medical NLP models using anonymized patient records
- Creates an interface that allows doctors to query patient symptoms and receive potential diagnoses with supporting evidence
- Implements explanation features that clarify how the system reached its conclusions
- Tests the system with medical professionals using diverse patient scenarios
- Deploys the system with careful monitoring and continuous learning capabilities
Tools and Technologies

- Deep learning frameworks: TensorFlow, PyTorch, JAX
- NLP libraries: Hugging Face Transformers, spaCy, NLTK
- Computer vision: OpenCV, YOLO, detectron2
- Speech processing: Wav2Vec, Whisper, Kaldi
- Cloud AI services: AWS AI Services, Google Cloud AI, Azure Cognitive Services
- Development frameworks: FastAPI, Flask, React
- Explainable AI tools: SHAP, LIME, TensorBoard
- Responsible AI: Fairlearn, AI Fairness 360
Generative AI Engineer: The Creative AI Specialist
Role Definition
Generative AI Engineers specialize in developing systems that can create new content, such as text, images, audio, video, and code. They focus on large language models, diffusion models, generative adversarial networks, and other techniques that enable computers to generate human-like creative outputs.
Required Skills
- Programming: Advanced Python, JavaScript
- Deep Learning: Focus on generative models (LLMs, GANs, VAEs, diffusion models)
- Prompt Engineering: Designing effective prompts for LLMs
- Fine-tuning Techniques: Adapting foundation models
- Software Engineering: API development, system integration
- Ethics and Safety: Content filtering, output validation
- Creative Domain Knowledge: Understanding of content creation principles
Detailed Day-to-Day Workflow

- Use Case Definition and Scoping
- Identify generative AI applications for business needs
- Define creative and functional requirements
- Establish content quality and safety guidelines
- Set performance benchmarks and acceptance criteria
- Assess technical feasibility and constraints
- Model Selection and Adaptation
- Evaluate foundation models for specific use cases
- Select appropriate generative architectures
- Plan model adaptation strategy (fine-tuning, RAG)
- Assess computational requirements and limitations
- Create proof-of-concept demonstrations
- Data Collection and Preparation
- Identify training and fine-tuning data needs
- Curate domain-specific datasets
- Clean and preprocess data for training
- Create evaluation datasets
- Address copyright and licensing concerns
- Model Development and Fine-tuning
- Implement model architecture and components
- Fine-tune foundation models on specific domains
- Develop prompt templates and optimization
- Build retrieval systems for context enhancement
- Implement content filtering and safety measures
- Generation Pipeline Development
- Create end-to-end content generation pipelines
- Implement pre-processing and post-processing steps
- Develop parameter control interfaces
- Build caching and optimization mechanisms
- Create feedback collection systems
- Quality Assurance and Safety
- Implement automated content quality checks
- Create harm detection and prevention systems
- Test for biases and problematic outputs
- Develop human-in-the-loop review processes
- Create guardrails for inappropriate content
- System Integration and Deployment
- Build APIs for generative capabilities
- Integrate with content management systems
- Implement user interfaces for content generation
- Deploy models with appropriate scaling infrastructure
- Set up monitoring for usage and performance
- Continuous Improvement
- Collect and analyze user feedback
- Monitor content quality and safety incidents
- Update models with new techniques and data
- Optimize for cost and performance
- Research emerging generative AI capabilities
Example Scenario
A marketing agency wants to develop a system that generates personalized ad copy for different customer segments. The Generative AI Engineer:
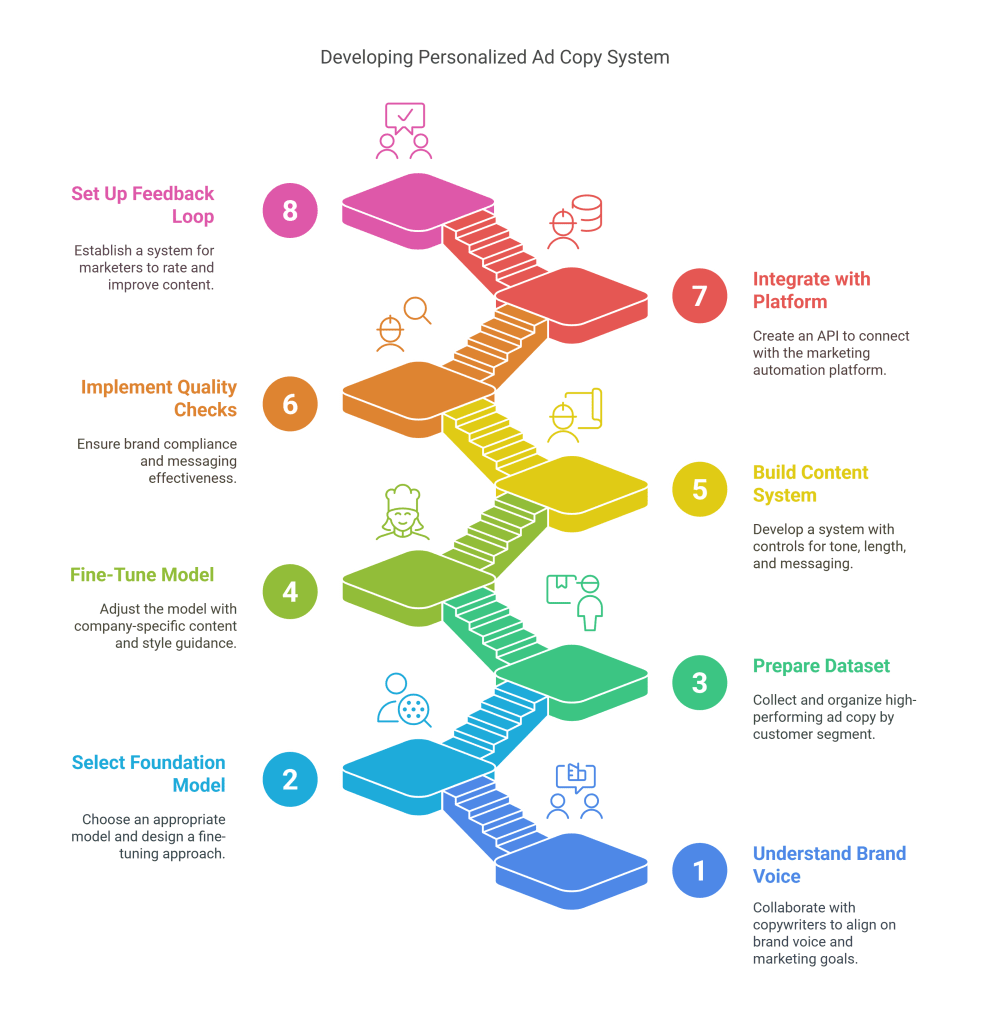
- Works with copywriters to understand brand voice, marketing goals, and target audience segments
- Selects an appropriate foundation model and designs a fine-tuning approach
- Collects and prepares a dataset of high-performing ad copy organized by customer segment
- Fine-tunes the model on company-specific content with guidance on tone and style
- Builds a content generation system with controls for tone, length, and key messaging
- Implements quality checks to ensure brand compliance and messaging effectiveness
- Creates an API that integrates with the company’s marketing automation platform
- Sets up a feedback loop where marketers can rate and improve generated content
Tools and Technologies
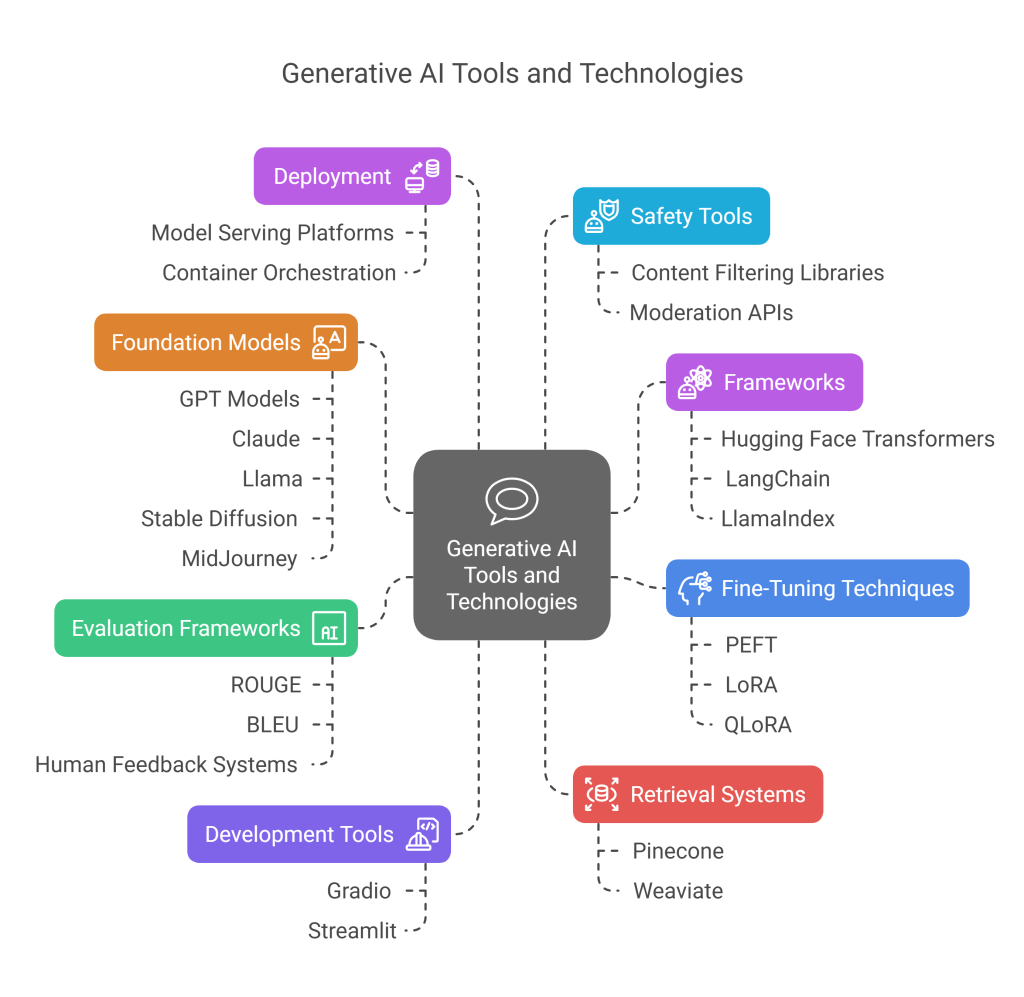
- Foundation models: GPT models, Claude, Llama, Stable Diffusion, MidJourney
- Frameworks: Hugging Face Transformers, LangChain, LlamaIndex
- Development tools: Gradio, Streamlit for prototyping
- Fine-tuning techniques: PEFT, LoRA, QLoRA
- Retrieval systems: Vector databases (e.g., Pinecone, Weaviate)
- Evaluation frameworks: ROUGE, BLEU, human feedback systems
- Deployment: Model serving platforms, container orchestration
- Safety tools: Content filtering libraries, moderation APIs
Side-by-Side Comparison of Data Roles
Understanding the key differences between these data roles helps organizations build balanced teams and helps individuals choose career paths that match their skills and interests.
Primary Focus

- Data Analyst: Descriptive and diagnostic analytics; answering “what happened and why”
- Data Scientist: Predictive and prescriptive analytics; building models to forecast future outcomes
- Business Analyst: Business process optimization and requirements definition
- Data Engineer: Data infrastructure and pipeline development
- ML Engineer: Deploying and scaling machine learning models in production
- AI Engineer: Building end-to-end intelligent applications and systems
- Generative AI Engineer: Creating systems that generate new content autonomously
Technical Skill Level Required
- Programming Proficiency:
- Low to Medium: Business Analyst
- Medium: Data Analyst
- High: Data Scientist, Data Engineer, ML Engineer, AI Engineer, Generative AI Engineer
- Statistics and Math:
- Low: Business Analyst
- Medium: Data Analyst, Data Engineer
- High: Data Scientist, ML Engineer, AI Engineer, Generative AI Engineer
- Software Engineering:
- Low: Business Analyst, Data Analyst
- Medium: Data Scientist
- High: Data Engineer, ML Engineer, AI Engineer, Generative AI Engineer
Position in the Data Value Chain
- Data Analyst: Downstream consumer of processed data
- Data Scientist: Middle of the chain, consuming processed data and creating models
- Business Analyst: At the beginning (requirements) and end (implementation) of projects
- Data Engineer: Upstream, creating data infrastructure for others to use
- ML Engineer: Middle to downstream, deploying models created by data scientists
- AI Engineer: End-to-end involvement across the value chain
- Generative AI Engineer: Specialized focus on content creation capabilities
Business vs. Technical Orientation
- More Business-Oriented: Business Analyst, Data Analyst
- Balanced: Data Scientist, AI Engineer, Generative AI Engineer
- More Technical: Data Engineer, ML Engineer
Time Horizon of Work
- Retrospective (Past-Focused): Data Analyst, Business Analyst
- Predictive (Future-Focused): Data Scientist, ML Engineer
- Infrastructure (Present-Focused): Data Engineer
- Application (Present and Future): AI Engineer, Generative AI Engineer
Career Paths and Transitions Between Roles
The data field offers various career progression paths, and professionals often transition between roles as they develop new skills or interests change.
Common Career Progression Paths

- Data Analysis Track:
- Entry: Junior Data Analyst
- Mid-level: Data Analyst → Senior Data Analyst
- Advanced: Analytics Manager → Director of Analytics → Chief Analytics Officer
- Data Science Track:
- Entry: Junior Data Scientist
- Mid-level: Data Scientist → Senior Data Scientist
- Advanced: Lead Data Scientist → Director of Data Science → Chief Data Scientist
- Engineering Track:
- Entry: Junior Data Engineer
- Mid-level: Data Engineer → Senior Data Engineer
- Advanced: Data Engineering Manager → Director of Data Infrastructure → Chief Data Officer
- Machine Learning Track:
- Entry: Junior ML Engineer
- Mid-level: ML Engineer → Senior ML Engineer
- Advanced: ML Architect → Director of ML → Chief AI Officer
- Business Analysis Track:
- Entry: Junior Business Analyst
- Mid-level: Business Analyst → Senior Business Analyst
- Advanced: Business Systems Analyst → Business Architecture Manager → Chief Business Architect
- AI Engineering Track:
- Entry: Junior AI Engineer
- Mid-level: AI Engineer → Senior AI Engineer
- Advanced: AI Architect → Director of AI → Chief AI Officer
- Generative AI Track:
- Entry: Generative AI Developer
- Mid-level: Generative AI Engineer → Senior Generative AI Engineer
- Advanced: Generative AI Architect → Director of Generative AI
Common Transition Paths
Many professionals transition between these roles as their careers evolve. Some common transition patterns include:
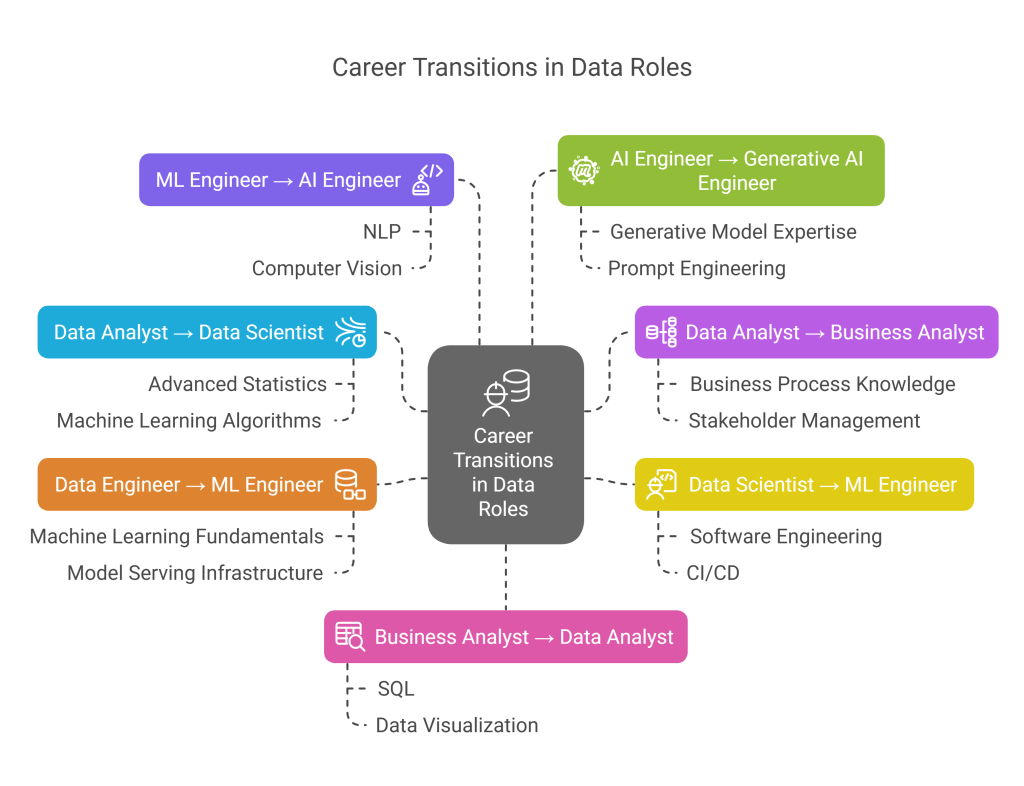
- Data Analyst → Data Scientist
- Required skill development: Advanced statistics, machine learning algorithms, deeper programming skills
- Transition difficulty: Moderate to high (requires significant mathematical foundation)
- Time frame: Typically 1-2 years with focused upskilling
- Data Analyst → Business Analyst
- Required skill development: Business process knowledge, requirements gathering, stakeholder management
- Transition difficulty: Low to moderate (leverages existing data skills with business focus)
- Time frame: 6-12 months
- Data Scientist → ML Engineer
- Required skill development: Software engineering best practices, CI/CD, system design, deployment
- Transition difficulty: Moderate (requires stronger engineering background)
- Time frame: 6-12 months with programming background
- Data Engineer → ML Engineer
- Required skill development: Machine learning fundamentals, model serving infrastructure
- Transition difficulty: Moderate (strong technical foundation helps)
- Time frame: 9-18 months
- ML Engineer → AI Engineer
- Required skill development: Broader AI technologies (NLP, computer vision), application development
- Transition difficulty: Low to moderate (builds on ML engineering foundation)
- Time frame: 6-12 months
- AI Engineer → Generative AI Engineer
- Required skill development: Generative model expertise, foundation model fine-tuning, prompt engineering
- Transition difficulty: Low (specialized extension of AI engineering)
- Time frame: 3-9 months
- Business Analyst → Data Analyst
- Required skill development: SQL, statistical analysis, data visualization
- Transition difficulty: Moderate (requires more technical skills)
- Time frame: 6-12 months
T-Shaped Skills Development
For long-term career growth in data fields, developing “T-shaped” skills is increasingly important:
- Vertical bar (depth): Deep expertise in one primary role
- Horizontal bar (breadth): Working knowledge of adjacent roles
For example, a Data Scientist with deep statistical and modeling expertise (vertical) who also understands data engineering concepts and business analysis (horizontal) will be more effective and have more career opportunities.
The most successful data professionals develop both:
- Technical excellence in their core domain
- Business understanding to connect their work to organizational value
- Communication skills to translate between technical and non-technical stakeholders
Educational Requirements and Learning Paths
The educational requirements for data roles vary considerably, with some positions accessible through self-directed learning and others typically requiring advanced degrees.
Formal Education Requirements
- Data Analyst
- Minimum: Bachelor’s degree in statistics, mathematics, economics, or related field
- Preferred: Bachelor’s degree plus relevant certifications (e.g., Microsoft Power BI, Tableau)
- Alternative paths: Bootcamps focused on data analytics, self-learning with portfolio projects
- Business Analyst
- Minimum: Bachelor’s degree in business, finance, IT, or related field
- Preferred: Bachelor’s degree plus certifications (e.g., IIBA certifications, Agile certifications)
- Alternative paths: Internal transfers from business operations roles with domain knowledge
- Data Engineer
- Minimum: Bachelor’s degree in computer science, software engineering, or related field
- Preferred: Bachelor’s or Master’s in computer science with database specialization
- Alternative paths: Software engineers transitioning with self-study in data technologies
- Data Scientist
- Minimum: Bachelor’s degree in statistics, mathematics, computer science, or related field
- Preferred: Master’s or Ph.D. in data science, machine learning, statistics, or computational field
- Alternative paths: Intensive bootcamps plus significant self-study and project portfolio
- Machine Learning Engineer
- Minimum: Bachelor’s degree in computer science or related technical field
- Preferred: Master’s in computer science with machine learning focus
- Alternative paths: Software engineers with ML specialization through extended self-study
- AI Engineer
- Minimum: Bachelor’s degree in computer science, cognitive science, or related field
- Preferred: Master’s or Ph.D. in AI, ML, computer science, or related field
- Alternative paths: Software engineers with AI specialization and strong portfolio
- Generative AI Engineer
- Minimum: Bachelor’s degree in computer science or related field
- Preferred: Master’s or Ph.D. with focus on generative models or NLP
- Alternative paths: AI engineers with specialized training in generative techniques
Self-Learning Paths
For those pursuing self-directed learning, here are recommended sequences:
Path to Data Analyst
- Foundations: Excel advanced functions, basic statistics, business metrics
- Technical Skills: SQL fundamentals and advanced queries
- Visualization: Tableau or Power BI
- Programming: Basic Python with Pandas and NumPy
- Projects: Build a portfolio analyzing public datasets
- Optional: Basic A/B testing, experimental design
Path to Data Scientist
- Prerequisites: Linear algebra, calculus, probability, statistics
- Programming: Python or R with data science libraries
- Machine Learning: Supervised and unsupervised learning algorithms
- Deep Learning: Neural networks fundamentals
- Specialized Areas: NLP, computer vision, time series (based on interest)
- Projects: Kaggle competitions, research replication, original projects
Path to Data Engineer
- Programming: Python, Java, or Scala
- Databases: SQL and NoSQL databases
- Big Data: Hadoop ecosystem, Spark, distributed computing
- Cloud: AWS/GCP/Azure data services
- DevOps: Docker, Kubernetes, CI/CD pipelines
- Projects: Building data pipelines, ETL systems
Path to ML Engineer
- Software Engineering: System design, APIs, testing
- MLOps: Model deployment, monitoring, versioning
- Production ML: Serving infrastructure, scaling considerations
- Cloud ML Services: AWS SageMaker, Google Vertex AI, etc.
- Projects: End-to-end ML system deployment
Path to AI Engineer
- ML Engineering Foundations: From above
- Deep Learning Frameworks: TensorFlow, PyTorch in depth
- AI Technologies: NLP, computer vision, speech recognition
- Application Development: Building user-facing AI applications
- Projects: End-to-end AI applications with user interfaces
Path to Generative AI Engineer
- AI Engineering Foundations: From above
- Foundation Models: Understanding LLMs, diffusion models, etc.
- Prompt Engineering: Advanced prompting techniques
- Fine-tuning: Adaptation of foundation models
- Retrieval-Augmented Generation: Vector databases, semantic search
- Projects: Building practical generative AI applications
Key Resources for Learning
Online Courses and Platforms:
- Coursera: Data Science specializations from universities
- edX: Technical courses from leading institutions
- Udacity: Nanodegree programs in data science and ML
- DataCamp: Interactive data science learning
- Fast.ai: Practical deep learning courses
- Hugging Face: Courses on NLP and generative AI
Books:
- “Python for Data Analysis” by Wes McKinney
- “The Data Warehouse Toolkit” by Ralph Kimball
- “Designing Data-Intensive Applications” by Martin Kleppmann
- “Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow” by Aurélien Géron
- “Building Machine Learning Powered Applications” by Emmanuel Ameisen
- “Deep Learning” by Ian Goodfellow, Yoshua Bengio, and Aaron Courville
Communities and Forums:
- Stack Overflow: Technical questions
- Kaggle: Competitions and notebooks
- GitHub: Open-source projects
- Reddit communities: r/datascience, r/machinelearning
- Discord/Slack communities: PyTorch, TensorFlow, Hugging Face
- Industry meetups and conferences
Industry Demand and Salary Expectations
The data field continues to experience strong growth, though demand varies by role and industry. Understanding current market conditions helps professionals make informed career decisions.
Current Demand by Role (2025)
- Data Engineer
- Demand Level: Very High
- Growth Trend: Steady increase
- Key Industries: Technology, finance, healthcare, retail
- Market Notes: Critical shortage of qualified data engineers as organizations build robust data infrastructure
- Generative AI Engineer
- Demand Level: Very High
- Growth Trend: Rapid increase
- Key Industries: Technology, media, marketing, e-commerce
- Market Notes: Explosive growth following mainstream adoption of generative AI technologies
- Machine Learning Engineer
- Demand Level: High
- Growth Trend: Steady increase
- Key Industries: Technology, finance, healthcare, automotive
- Market Notes: Strong demand as companies move from experimentation to production ML
- AI Engineer
- Demand Level: High
- Growth Trend: Steady increase
- Key Industries: Technology, healthcare, finance, manufacturing
- Market Notes: Growing demand for end-to-end AI application development
- Data Scientist
- Demand Level: Moderate to High
- Growth Trend: Stabilizing after years of rapid growth
- Key Industries: Technology, finance, healthcare, retail
- Market Notes: Market becoming more selective, favoring specialists and those with strong technical backgrounds
- Data Analyst
- Demand Level: Moderate to High
- Growth Trend: Steady
- Key Industries: Across all sectors
- Market Notes: Consistent demand; entry-level positions increasingly require stronger technical skills
- Business Analyst
- Demand Level: Moderate
- Growth Trend: Stable
- Key Industries: Finance, healthcare, retail, manufacturing
- Market Notes: Stable demand with emphasis on digital transformation skills
Salary Ranges by Role and Experience (U.S. Based, 2025)
Note: Salary ranges vary significantly by location, industry, company size, and individual skill level. The following represents typical ranges for U.S.-based professionals.
Data Analyst
- Entry-level: $60,000 – $80,000
- Mid-level: $80,000 – $110,000
- Senior-level: $110,000 – $140,000
- Lead/Manager: $130,000 – $180,000
Business Analyst
- Entry-level: $65,000 – $85,000
- Mid-level: $85,000 – $115,000
- Senior-level: $115,000 – $145,000
- Lead/Manager: $140,000 – $190,000
Data Engineer
- Entry-level: $80,000 – $110,000
- Mid-level: $110,000 – $150,000
- Senior-level: $150,000 – $200,000
- Lead/Architect: $180,000 – $250,000
Data Scientist
- Entry-level: $85,000 – $115,000
- Mid-level: $115,000 – $160,000
- Senior-level: $160,000 – $210,000
- Lead/Manager: $200,000 – $275,000
Machine Learning Engineer
- Entry-level: $90,000 – $125,000
- Mid-level: $125,000 – $175,000
- Senior-level: $175,000 – $225,000
- Lead/Architect: $220,000 – $300,000
AI Engineer
- Entry-level: $95,000 – $130,000
- Mid-level: $130,000 – $180,000
- Senior-level: $180,000 – $240,000
- Lead/Architect: $230,000 – $320,000
Generative AI Engineer
- Entry-level: $100,000 – $140,000
- Mid-level: $140,000 – $190,000
- Senior-level: $190,000 – $250,000
- Lead/Architect: $240,000 – $350,000
Factors Influencing Compensation
- Educational Background
- Advanced degrees (MS, PhD) typically command higher salaries
- Prestigious university degrees often lead to higher starting offers
- Geographic Location
- Highest: San Francisco, New York, Seattle
- High: Boston, Los Angeles, Washington DC
- Moderate: Chicago, Austin, Denver
- Growing remote options are changing geographic compensation models
- Industry Sector
- Highest paying: Finance, technology, pharmaceuticals
- Moderate paying: Retail, healthcare, manufacturing
- Lower paying: Education, non-profit, government
- Company Size and Type
- FAANG and top tech companies offer premium compensation
- Startups often offer lower base salaries but equity potential
- Established non-tech companies typically offer moderate salaries with better work-life balance
- Specialized Skills
- Expertise in high-demand areas (LLMs, reinforcement learning)
- Specialized domain knowledge (healthcare AI, financial modeling)
- Full-stack capabilities across the data pipeline
Non-Salary Compensation and Benefits
- Equity: Particularly important in startups and tech companies
- Bonuses: Performance-based, signing, and retention bonuses are common
- Remote Work: Increasingly standard across most data roles
- Continuing Education: Learning stipends and conference attendance
- Computing Resources: Access to high-performance computing infrastructure
- Work-Life Balance: Varying significantly by company and role
Choosing the Right Data Career Path For You
Selecting the right data career path requires careful consideration of your interests, strengths, and long-term goals. Here’s a framework to help you make that decision.
Self-Assessment Questionnaire
Answer these questions honestly to determine which data role might be the best fit:
- Technical vs. Business Orientation
- Do you prefer solving technical challenges or addressing business problems?
- Are you more interested in how things work or why they matter?
- Do you enjoy communicating with non-technical stakeholders?
- Depth vs. Breadth
- Do you prefer becoming an expert in one area or having knowledge across many domains?
- Are you interested in specializing deeply or maintaining flexibility?
- Building vs. Analyzing
- Do you enjoy creating systems and infrastructure?
- Or do you prefer exploring existing data and finding patterns?
- Mathematics Affinity
- How comfortable are you with advanced mathematics and statistics?
- Do you enjoy theoretical concepts or practical applications?
- Programming Interest
- How much do you enjoy writing code?
- What level of software engineering interests you?
- Creativity vs. Structure
- Do you prefer well-defined problems or open-ended challenges?
- Are you more comfortable with creative solutions or established methodologies?
- Short-term vs. Long-term Impact
- Are you motivated by quick wins and immediate insights?
- Or do you prefer working on systems with long-term impact?
Recommended Roles Based on Personal Preferences
If you prioritize business impact and communication:
- Business Analyst
- Data Analyst
- AI Engineer (customer-facing applications)
If you enjoy mathematics and research:
- Data Scientist
- Research-focused AI Engineer
- Specialized ML Engineer
If you love building systems and infrastructure:
- Data Engineer
- DevOps-focused ML Engineer
- Systems-oriented AI Engineer
If you’re interested in cutting-edge applications:
- Generative AI Engineer
- Research-focused AI Engineer
- Specialized Data Scientist
If you value work-life balance and stability:
- Data Analyst (established industries)
- Business Analyst
- Data Engineer (enterprise settings)
If you seek maximum compensation potential:
- Generative AI Engineer
- ML Engineer with specialized expertise
- Data Engineer with cloud architecture skills
Entry Points for Career Changers
From Software Engineering:
- Best transitions: Data Engineer → ML Engineer → AI Engineer
- Leverage: Software development skills, system design knowledge
- Focus on: Data structures, ML fundamentals, specialized frameworks
From Statistics/Mathematics:
- Best transitions: Data Scientist → ML Engineer → AI Engineer
- Leverage: Statistical knowledge, analytical thinking
- Focus on: Programming skills, production deployment, engineering best practices
From Business/Domain Expertise:
- Best transitions: Business Analyst → Data Analyst → Data Scientist
- Leverage: Domain knowledge, stakeholder communication
- Focus on: Technical skills, SQL, programming, analytical methods
From Creative Fields:
- Best transitions: Data Visualization Specialist → Data Analyst → Generative AI Engineer
- Leverage: Design thinking, user experience understanding
- Focus on: Technical foundations, programming, AI principles
Trial Projects to Discover Your Fit
Before committing to a career path, consider completing projects that simulate the work:
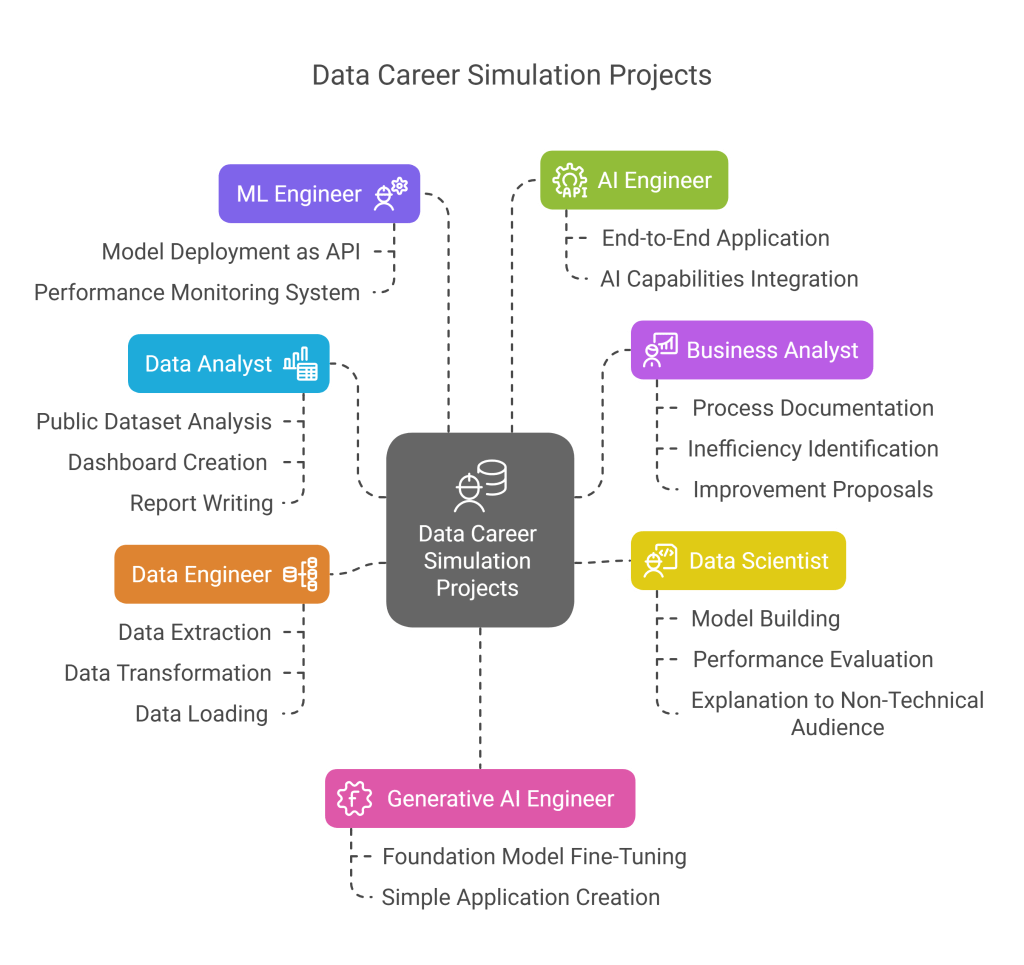
Data Analyst: Analyze a public dataset, create dashboards, and write a report with recommendations.
Business Analyst: Document a business process, identify inefficiencies, and propose improvements with cost-benefit analysis.
Data Scientist: Build a predictive model, evaluate its performance, and explain findings to non-technical audience.
Data Engineer: Create a data pipeline that extracts, transforms, and loads data from one source to another.
ML Engineer: Deploy a trained model as an API and build a system to monitor its performance.
AI Engineer: Build an end-to-end application that incorporates AI capabilities to solve a specific problem.
Generative AI Engineer: Fine-tune a foundation model on a specific domain and create a simple application using it.
The Future of Data Careers: Emerging Trends
The data landscape continues to evolve rapidly. Understanding emerging trends helps professionals prepare for future opportunities and challenges.
Key Trends Reshaping Data Careers
- Democratization of AI and Analytics
- Impact on roles: Increasing need for data professionals to focus on higher-value tasks
- New opportunities: Specialists who can customize and optimize automated tools
- Threatened positions: Entry-level roles focused on repetitive analytics
- Adaptation strategy: Develop skills in customizing and extending AI tools rather than competing with them
- Rise of Domain Specialization
- Impact on roles: Growing demand for data professionals with industry-specific knowledge
- Emerging roles: Healthcare AI Engineer, Financial Data Scientist, Retail Analytics Specialist
- Career implications: Domain expertise becoming as valuable as technical skills
- Adaptation strategy: Cultivate deep knowledge in a specific industry alongside technical capabilities
- MLOps and AIOps Maturity
- Impact on roles: Greater emphasis on operational excellence for AI systems
- Emerging roles: ML Reliability Engineer, AI Operations Specialist
- Career implications: Convergence of data science and DevOps practices
- Adaptation strategy: Develop automation, monitoring, and reliability engineering skills
- Ethical AI and Responsible Data Practice
- Impact on roles: New requirements for addressing bias, fairness, and transparency
- Emerging roles: AI Ethics Specialist, Responsible AI Engineer
- Career implications: Ethics becoming a technical requirement, not just a philosophical concern
- Adaptation strategy: Develop expertise in fairness metrics, explainable AI, and privacy-preserving techniques
- Foundation Models Reshaping the Stack
- Impact on roles: Shift from building models to customizing and deploying foundation models
- Emerging roles: Prompt Engineer, Model Fine-tuning Specialist
- Career implications: Changing skill requirements from model building to model adaptation
- Adaptation strategy: Master techniques for effectively working with large pre-trained models
- Low-Code/No-Code Tools Proliferation
- Impact on roles: Automation of basic data tasks and democratization of analytics capabilities
- Emerging roles: Low-Code Data Solution Architect, Citizen Data Scientist Enabler
- Career implications: Focus shifting to designing automated systems rather than manual implementation
- Adaptation strategy: Become expert in configuring and extending low-code platforms
- Real-time Analytics and Processing
- Impact on roles: Growing demand for skills in streaming data and real-time decision systems
- Emerging roles: Real-time Analytics Engineer, Streaming Data Architect
- Career implications: Shift from batch processing to continuous data processing paradigms
- Adaptation strategy: Develop expertise in stream processing technologies and event-driven architectures
Emerging Hybrid Roles
As the field matures, new hybrid roles are emerging at the intersections of traditional positions:
- DataOps Engineer
- Combination of: Data Engineer + DevOps Engineer
- Focus: Automating and optimizing data infrastructure
- Key skills: Infrastructure as code, CI/CD for data pipelines, observability
- Decision Intelligence Engineer
- Combination of: Data Scientist + Business Analyst
- Focus: Building systems that translate data into optimal decisions
- Key skills: Causal inference, decision theory, business process optimization
- Data Product Manager
- Combination of: Product Manager + Data Analyst
- Focus: Developing data-driven products and features
- Key skills: Product development, data storytelling, user experience
- ML Platform Engineer
- Combination of: ML Engineer + Platform Engineer
- Focus: Building internal platforms for ML development
- Key skills: API design, platform development, ML engineering
- AI UX Designer
- Combination of: UX Designer + AI Engineer
- Focus: Creating intuitive interfaces for AI systems
- Key skills: Interaction design, AI capabilities understanding, user psychology
Future-Proofing Your Data Career
To remain competitive in the evolving data landscape:
- Continuous Learning
- Follow research papers in your field
- Allocate time weekly for learning new tools and techniques
- Participate in competitions and challenges
- Build T-Shaped Expertise
- Develop deep expertise in one area
- Maintain working knowledge of adjacent fields
- Understand the end-to-end data lifecycle
- Cultivate Domain Knowledge
- Become an expert in a specific industry or business function
- Learn the language and metrics of that domain
- Understand domain-specific data challenges
- Develop Complementary Skills
- Business acumen and ROI quantification
- Project management and leadership
- Effective communication and stakeholder management
- Create a Personal Brand
- Share knowledge through blogs, talks, or open-source contributions
- Build a portfolio of impactful projects
- Network with professionals across the data ecosystem
Conclusion
The data ecosystem has evolved into a rich and diverse landscape of specialized roles, each with distinct responsibilities, skill requirements, and career trajectories. Understanding these differences is crucial for both individuals planning their careers and organizations building effective data teams.
Key Takeaways
- Role Clarity Matters
- Each data role serves a specific purpose in the data value chain
- Specialized expertise yields better results than generic “data person” expectations
- Clear role definitions help avoid misaligned expectations and frustrations
- The Right Role Depends on Your Strengths
- Technical depth vs. business breadth
- Building systems vs. extracting insights
- Mathematics affinity vs. engineering mindset
- Select a path that plays to your natural strengths
- Skills Are Transferable
- Core data competencies apply across multiple roles
- Transitioning between related roles is increasingly common
- T-shaped skill development creates flexibility
- Continuous Evolution is Necessary
- The data field changes rapidly with new technologies and approaches
- Lifelong learning is essential for long-term career success
- Domain expertise provides stability amid technical changes
- Value Comes From Business Impact
- Technical excellence alone is insufficient
- The most successful data professionals connect their work to business outcomes
- Communication skills amplify the impact of technical capabilities
Whether you’re a Data Analyst turning raw numbers into actionable insights, a Data Scientist building predictive models, a Business Analyst optimizing processes, a Data Engineer creating robust data infrastructure, an ML Engineer deploying models at scale, an AI Engineer building intelligent applications, or a Generative AI Engineer creating content-generating systems, your role is essential in helping organizations harness the power of data.
By understanding the unique contributions of each role and developing your skills accordingly, you can build a rewarding career in this dynamic and rapidly evolving field. The future belongs to those who can adapt to changing technologies while maintaining focus on delivering value through data.
FAQ
Q: Which data role is best for beginners without technical backgrounds? A: Business Analyst or Data Analyst roles typically have the lowest technical barriers to entry, though both still require analytical thinking and some technical skills that can be developed through focused learning.
Q: Do I need an advanced degree to become a Data Scientist? A: While many Data Scientists have Master’s or PhD degrees, it’s increasingly possible to enter the field through bootcamps and self-study, particularly if you build a strong portfolio demonstrating relevant skills and complete projects showing your capabilities.
Q: Which role has the best long-term career prospects? A: Data Engineer and ML Engineer roles currently show strong demand and growth potential due to the critical need for data infrastructure and operationalized AI. However, all specialized data roles with continuous skill development offer excellent prospects.
Q: How do I transition from a non-data role into data careers? A: Start by identifying transferable skills from your current role, then develop fundamental data skills through courses and projects. Consider transitioning through hybrid roles that
Discover more from SkillWisor
Subscribe to get the latest posts sent to your email.
