

The landscape of artificial intelligence has been profoundly reshaped by the advent of Large Language Models (LLMs). These models, characterized by their massive scale, intricate architectures, and training on colossal datasets, have demonstrated unprecedented capabilities in understanding, generating, and manipulating human language. From sophisticated chatbots and content creation tools to powerful code assistants and research aids, LLMs are rapidly integrating into various facets of technology and society. However, the sheer size and computational demands of state-of-the-art LLMs present significant challenges. Training these models requires vast computational resources, immense amounts of data, and considerable time and energy. Furthermore, deploying such large models for inference, especially in resource-constrained environments like mobile devices or embedded systems, remains a non-trivial task due to high latency and memory requirements.
These challenges have spurred research into more efficient methods for developing and deploying powerful language models. One particularly promising avenue involves leveraging the knowledge embedded within large, pre-trained LLMs to train smaller, more efficient models. This approach, often framed within the paradigm of knowledge distillation, allows the “student” model to learn from the “teacher” model’s expertise, potentially achieving performance comparable to the teacher while being significantly smaller and faster. This article delves into several key techniques for training LLMs using the guidance of other LLMs, exploring their mechanisms, advantages, disadvantages, and potential impact.
The Motivation Behind Teacher-Student Training
Why would one use a large, already powerful LLM to train another, presumably smaller, LLM? The primary motivations stem from the desire to overcome the limitations associated with deploying and utilizing massive models.

Firstly, model size and computational cost are major factors. Larger models require more memory and processing power for both training and inference. By training a smaller student model to mimic the behavior of a larger teacher, it becomes possible to deploy capable language models on less powerful hardware, making AI more accessible and reducing operational costs.
Secondly, inference speed is crucial for real-time applications. A smaller model typically has fewer parameters and requires fewer computations per inference, leading to lower latency. This is vital for applications like conversational AI, real-time translation, or any scenario where quick responses are necessary.
Thirdly, data efficiency can be improved. While training the initial large teacher model requires enormous datasets, training a student model through distillation can often be achieved with less data or by using the teacher’s outputs as a form of enriched data. The teacher effectively acts as a data annotator and knowledge provider.
Finally, specialization and fine-tuning can be made more efficient. A large teacher model possesses broad knowledge. A smaller student model can be distilled from this teacher and then fine-tuned on a specific task or domain, potentially achieving high performance on that niche while remaining compact. The distillation process provides a strong initialization for the student model, accelerating the fine-tuning process.
In essence, using a teacher LLM to train a student LLM is a strategy to democratize access to advanced language capabilities by creating more efficient, deployable models that inherit the knowledge of their larger counterparts.
Understanding Knowledge Distillation
At its core, knowledge distillation is a model compression technique where a smaller model (the student) is trained to reproduce the behavior of a larger, more complex model (the teacher). The key idea is to transfer the “knowledge” from the teacher to the student. This knowledge is not just the final predicted output (the “hard label”), but also the nuances of the teacher’s internal decision-making process, often captured in the probability distribution over possible outputs (the “soft labels”).
Consider a classification task. A teacher model might predict that for a given input, the probability of it belonging to class A is 90%, class B is 8%, and class C is 2%. The hard label would simply be class A. However, the soft labels (90%, 8%, 2%) provide much richer information. They indicate that while the model is confident about class A, it also sees some similarity or possibility of the input belonging to class B. Training a student model to match these soft probabilities allows it to learn these subtle relationships and uncertainties, leading to potentially better generalization than simply training it on the hard labels alone.
In the context of LLMs, the “output” is typically the probability distribution over the vocabulary for the next token. The teacher LLM, given a sequence of tokens, produces a probability distribution over all possible next tokens in its vocabulary. The student LLM is then trained to mimic this distribution.
There are several ways to implement knowledge distillation for LLMs, broadly categorized by how the teacher’s output is used to guide the student’s training. We will focus on three prominent techniques: Soft-Label Distillation, Hard-Label Distillation, and Co-Distillation.
Technique 1: Soft-Label Distillation
Soft-label distillation is arguably the most common and often the most effective form of knowledge distillation. It leverages the full probability distribution produced by the teacher model as the training target for the student model.

Mechanism:
- Input Corpus: A dataset (which can be the original training data for the teacher or a new, unlabeled dataset) is fed as input to both the pre-trained teacher LLM and the student LLM.
- Teacher Output (Soft Labels): For each input sequence, the teacher LLM generates a probability distribution over its entire vocabulary for the next token. These are the “soft labels.” To make these probabilities “softer” (i.e., to increase the entropy of the distribution and reveal more information about less likely but still possible outcomes), a temperature parameter is often introduced in the softmax function. A higher temperature produces a softer distribution, while a temperature of 1 is the standard softmax.
- Student Output: The student LLM also generates a probability distribution over its vocabulary for the next token.
- Loss Function: The student model is trained to minimize the difference between its predicted probability distribution and the teacher’s soft probability distribution. The most common loss function for this purpose is the Kullback-Leibler (KL) divergence. KL divergence measures how one probability distribution diverges from a second, expected probability distribution. In this case, the student’s distribution is trained to converge towards the teacher’s distribution. Additionally, a standard cross-entropy loss using the true hard labels (if available) is often included, typically as a weighted sum with the KL divergence loss.
The total loss function for soft-label distillation can be expressed as:
Ltotal=α∗LKD(Pteacher∣∣Pstudent)+(1−α)∗LCE(ytrue,Pstudent)
Where:
- Ltotal is the total loss.
- LKD is the KL divergence between the teacher’s probability distribution (Pteacher) and the student’s probability distribution (Pstudent).
- LCE is the cross-entropy loss between the true hard label (ytrue) and the student’s probability distribution (Pstudent).
- α is a weighting parameter (between 0 and 1) that balances the contribution of the distillation loss and the standard supervised loss.
The temperature parameter (T) is applied to the softmax outputs of both the teacher and the student before calculating the KL divergence:
Pi=∑jexp(zj/T)exp(zi/T)
Where zi are the logits (raw outputs before softmax) for class i. The same temperature T is used for both teacher and student during training. For inference, the temperature is typically set back to 1 for the student model.
Advantages:
- Rich Information Transfer: Soft labels convey more information than hard labels, including the teacher’s confidence and the relationships between different possible outputs. This can lead to a student model that generalizes better and is more robust.
- Improved Generalization: By learning from the teacher’s nuanced probability distribution, the student can learn to handle ambiguous cases and generalize more effectively to unseen data.
- Robustness: The student model can potentially inherit some of the teacher’s robustness to noisy or adversarial inputs.
Disadvantages:
- Requires Teacher Probabilities: This method requires access to the full softmax probability distribution of the teacher model, which might not always be feasible or computationally cheap, especially if the teacher is a proprietary model accessed only through an API that provides only hard predictions.
- Hyperparameter Tuning: The temperature parameter (T) and the weighting parameter (α) need to be carefully tuned, which can add complexity to the training process.
Applications:
Soft-label distillation is widely used to train smaller, faster versions of large language models for deployment on edge devices, mobile phones, or in applications where low latency is critical. It’s also used to improve the performance of smaller models on specific downstream tasks by distilling knowledge from a large model pre-trained on a broader range of data.
Technique 2: Hard-Label Distillation
Hard-label distillation, also known as teacher-student training with hard targets, is a simpler form of distillation where the student model is trained to directly predict the final output (the hard label) of the teacher model.

Mechanism:
- Input Corpus: A dataset is fed as input to the pre-trained teacher LLM.
- Teacher Output (Hard Labels): For each input sequence, the teacher LLM performs inference and outputs its final predicted token (the token with the highest probability). This is treated as the “ground truth” or “hard label” for the student model.
- Student Output: The student LLM processes the same input sequence and generates its own prediction for the next token.
- Loss Function: The student model is trained using a standard cross-entropy loss function, comparing its predicted probability distribution for the next token against the one-hot encoded hard label provided by the teacher.
The loss function for hard-label distillation is simply:
Ltotal=LCE(yteacher,Pstudent)
Where:
- Ltotal is the total loss.
- LCE is the cross-entropy loss between the teacher’s hard label (yteacher, represented as a one-hot vector) and the student’s probability distribution (Pstudent).
Advantages:
- Simplicity: Hard-label distillation is conceptually simpler and easier to implement compared to soft-label distillation. It only requires the final predicted output of the teacher model.
- Lower Computational Cost (Teacher-side): If accessing the teacher’s full probability distribution is computationally expensive, obtaining only the hard prediction is cheaper.
- Compatibility with APIs: If the teacher model is only accessible via an API that returns only the top prediction, hard-label distillation is a viable option.
Disadvantages:
- Loss of Information: This method discards the rich information contained in the teacher’s full probability distribution. The student only learns to mimic the teacher’s final decision, not the nuances and uncertainties behind it.
- Potential for Error Propagation: If the teacher model makes mistakes, the student model will learn to replicate those mistakes, potentially amplifying them.
- Less Effective for Complex Tasks: For tasks where there isn’t a single clear “correct” answer or where the relationships between different outputs are important, hard-label distillation may be less effective than soft-label distillation.
Applications:
Hard-label distillation can be useful as a baseline distillation method or when computational constraints or API limitations prevent access to the teacher’s soft probabilities. It can be effective for tasks where the teacher’s hard predictions are highly accurate and sufficient as training signals. It can also be used in conjunction with other techniques.
Technique 3: Co-Distillation
Co-distillation, also known as mutual distillation or peer teaching, is a technique where multiple models (typically two, but can be more) are trained simultaneously, and each model acts as a teacher for the others. Unlike traditional distillation where a fixed, pre-trained teacher guides a student, in co-distillation, the models learn from each other collaboratively.
Mechanism:
- Input Corpus: A dataset is fed as input to both (or all) models being trained.
- Mutual Teaching: For each input sequence, each model generates its output (either soft probabilities or hard labels). Each model’s output is then used as a training signal for the other model(s).
- Loss Function: The training objective for each model includes a term that encourages it to match the output of the other model(s). If using soft-label co-distillation, the loss for model A would include a KL divergence term minimizing the difference between A’s output distribution and B’s output distribution, and vice versa. If using hard-label co-distillation, the loss for model A would include a cross-entropy term based on B’s hard prediction, and vice versa. Often, a standard supervised loss based on true labels (if available) is also included.
For two models, A and B, using soft-label co-distillation with true labels:
LA=α∗LKD(PB∣∣PA)+(1−α)∗LCE(ytrue,PA)
LB=α∗LKD(PA∣∣PB)+(1−α)∗LCE(ytrue,PB)
The total loss for the system is the sum of the individual model losses: Ltotal=LA+LB.
The models can start from scratch or be pre-trained to some extent. The key is the simultaneous training and the mutual exchange of knowledge.
Advantages:
- Improved Performance: Co-distillation can lead to improved performance for all participating models compared to training them individually, as they learn from each other’s strengths and potentially correct each other’s weaknesses.
- No Need for a Strong Pre-trained Teacher: This technique does not require a single, highly performant pre-trained teacher model. It can be used to improve a set of models starting from similar initial states.
- Encourages Collaboration and Diversity: The mutual learning process can encourage the models to explore different aspects of the data and potentially develop more diverse and robust representations.
Disadvantages:
- Complex Training Setup: Training multiple models simultaneously with mutual teaching objectives is more complex to set up and manage than training a single student model with a fixed teacher.
- Convergence Challenges: Ensuring stable and effective convergence for multiple interacting models can be challenging and may require careful tuning of learning rates and other hyperparameters.
- Computational Cost: Training multiple models concurrently requires more computational resources than training a single student model.
Applications:
Co-distillation can be used to improve the performance of an ensemble of models, to train multiple models for different purposes (e.g., models optimized for different hardware platforms) that can learn from each other, or in scenarios where a strong pre-trained teacher is not readily available. It’s a promising area of research for collaborative learning among neural networks.
Comparison and Hybrid Approaches
Each of these distillation techniques offers distinct advantages and disadvantages. The choice of technique depends on several factors, including the availability of a pre-trained teacher model, computational resources, the desired performance characteristics of the student model, and the nature of the task.
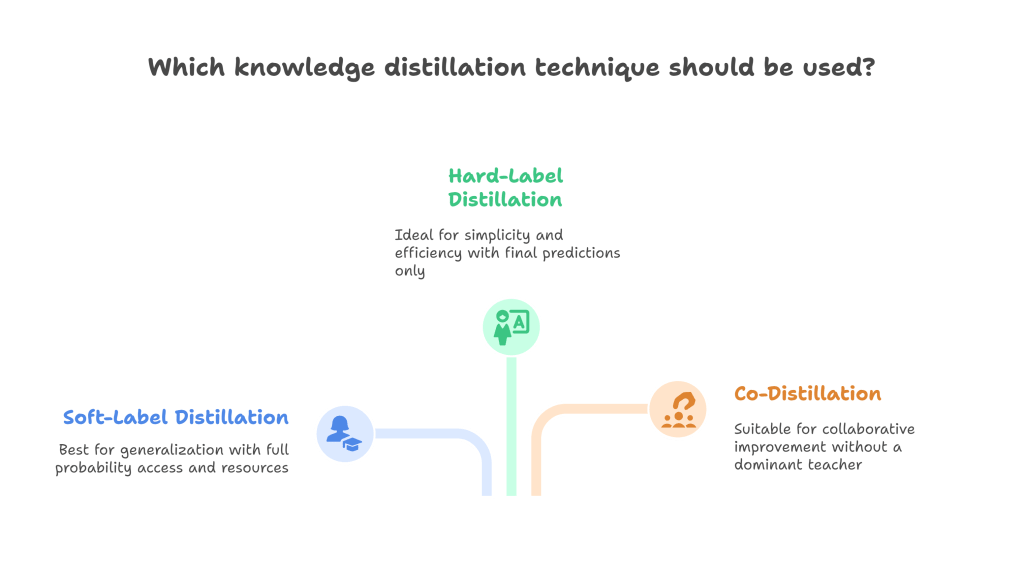
- Soft-Label Distillation is generally preferred when access to the teacher’s full probability distribution is available and computational resources allow. It tends to produce student models with better generalization capabilities.
- Hard-Label Distillation is a simpler alternative when only the teacher’s final predictions are available or when computational efficiency during distillation is paramount. However, it may result in a student model that is less robust and doesn’t capture the full complexity of the teacher’s knowledge.
- Co-Distillation is suitable when improving a set of models collaboratively is the goal or when a single dominant teacher model is not available. It’s more complex to implement but can lead to synergistic improvements.
It’s also possible and often beneficial to combine these techniques or integrate distillation with other training methods. For example, one could use a hybrid loss function that includes both KL divergence (for soft targets) and cross-entropy (for hard targets). Another approach is to combine distillation with techniques like pruning or quantization to further reduce the student model’s size and computational footprint. Distillation can also be used as part of a multi-stage training process, where a model is first distilled from a larger teacher and then fine-tuned on a specific task.
Challenges and Considerations
Implementing and effectively utilizing these LLM training techniques comes with several practical challenges:
- Teacher Model Selection: Choosing the right teacher model is crucial. The teacher should be sufficiently powerful and knowledgeable in the relevant domain to provide a valuable learning signal to the student.
- Dataset Selection: The input corpus used for distillation should be representative of the data the student model is expected to handle during inference. The size and quality of this dataset can significantly impact the student’s performance.
- Hyperparameter Tuning: Distillation introduces new hyperparameters, such as the temperature (T) in soft distillation and the loss weighting parameter (α), which require careful tuning to achieve optimal results.
- Computational Resources: While the goal is often to train a smaller model, the distillation process itself still requires computational resources, especially if the teacher model is large and inference needs to be performed on a large dataset. Co-distillation, in particular, can be computationally intensive.
- Evaluation Metrics: Evaluating the performance of the student model is essential. Beyond standard metrics like perplexity or task-specific accuracy, it’s important to assess whether the student has successfully captured the desired behaviors and capabilities of the teacher.
- Knowledge Gap: There is an inherent knowledge gap between a large teacher and a smaller student. The student model, due to its limited capacity, may not be able to fully replicate all the nuances and complexities of the teacher’s behavior.
Addressing these challenges requires careful experimental design, robust infrastructure, and a deep understanding of both the teacher and student models.
Applications and Future Directions
The techniques of training LLMs using other LLMs are finding increasing application in various domains:
- Model Compression and Deployment: Distillation is a primary method for creating smaller, faster LLMs suitable for deployment on edge devices, mobile applications, and in scenarios where low latency and limited resources are critical.
- Transfer Learning and Fine-tuning: Distillation can provide a strong starting point for training models on specific downstream tasks, allowing them to achieve high performance even with limited task-specific data.
- Improving Model Robustness: By learning from a robust teacher, the student model can potentially inherit some level of resilience to adversarial attacks or noisy inputs.
- Creating Specialized Models: Distillation can be used to train smaller models specialized in particular domains or tasks, leveraging the broad knowledge of a large general-purpose teacher.
Future research in this area is likely to focus on:
- Improving Distillation Efficiency: Developing more efficient distillation algorithms that require less data or computation.
- Exploring New Distillation Signals: Investigating whether signals beyond the final output probabilities (e.g., intermediate layer activations, attention weights) can be effectively used for distillation.
- Multi-Teacher and Multi-Student Distillation: Exploring distillation from multiple teacher models or training multiple student models collaboratively.
- Adaptive Distillation: Developing methods where the distillation process adapts based on the student’s learning progress or the characteristics of the input data.
- Theoretical Understanding: Gaining a deeper theoretical understanding of why distillation works and how to optimize the knowledge transfer process.
Conclusion
Training Large Language Models using other Large Language Models through techniques like soft-label distillation, hard-label distillation, and co-distillation has emerged as a powerful paradigm for creating more efficient, deployable, and specialized language models. These methods allow smaller “student” models to inherit the complex knowledge and capabilities of larger “teacher” models, mitigating the significant computational and deployment challenges associated with state-of-the-art LLMs.
Soft-label distillation, by leveraging the teacher’s full probability distribution, offers a rich learning signal leading to potentially better generalization. Hard-label distillation, while simpler, provides a baseline approach when soft targets are unavailable. Co-distillation enables collaborative learning among models, potentially improving the performance of a group.
While challenges related to hyperparameter tuning, data requirements, and computational costs persist, ongoing research and practical applications continue to refine and expand the utility of these techniques. As LLMs become increasingly integral to technology, the ability to efficiently transfer their knowledge to more accessible and specialized models will be crucial for democratizing AI and unlocking its full potential across a wider range of applications and devices. The continued exploration and development of these advanced training methods are vital steps in this direction, promising a future where powerful language AI is not confined to massive data centers but is readily available and adaptable to diverse needs and environments.
Discover more from SkillWisor
Subscribe to get the latest posts sent to your email.
