

In recent years, Large Language Models (LLMs) have revolutionized the field of artificial intelligence, enabling unprecedented capabilities in natural language understanding and generation. While most users interact with these powerful models through cloud-based APIs, there’s growing interest in running these sophisticated AI systems directly on personal devices. This comprehensive guide explores the intricate processes involved in running LLMs locally, from initialization to output generation.
Introduction: The Rising Demand for Local LLMs
The ability to run LLMs locally offers several compelling advantages: enhanced privacy, reduced latency, offline functionality, and cost savings. However, deploying these complex systems on consumer hardware presents significant technical challenges due to their computational demands. Understanding how these models operate locally provides valuable insights for developers, enthusiasts, and organizations looking to leverage AI capabilities without cloud dependencies.
The End-to-End Process of Running LLMs Locally
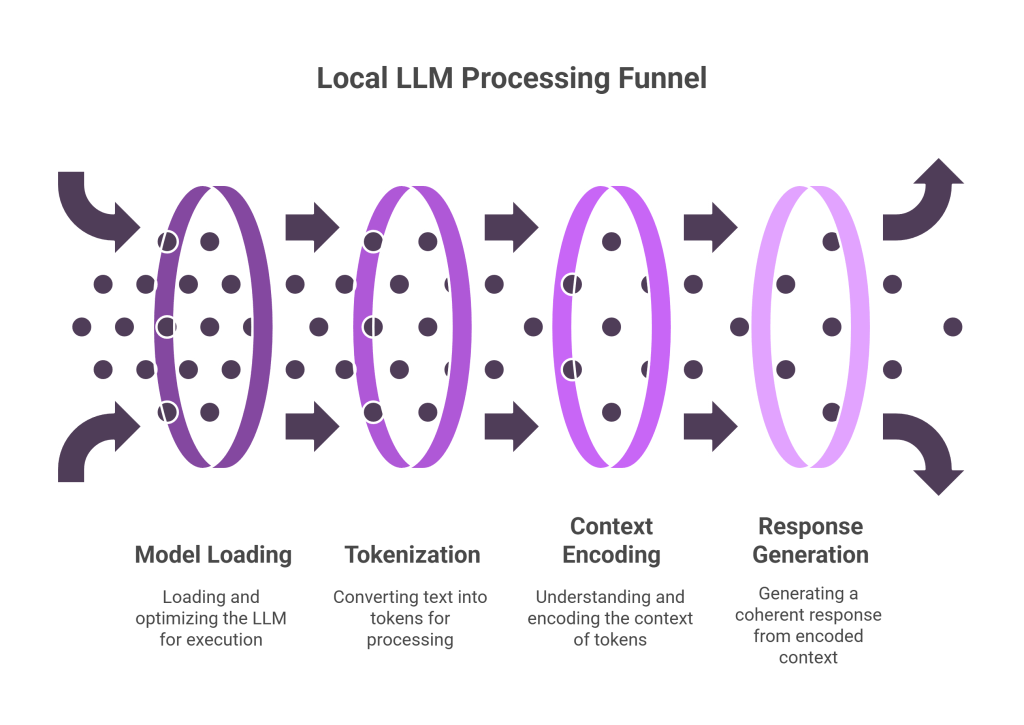
Running an LLM locally involves six critical stages that transform a user query into a coherent response. Let’s explore each phase in detail.
1. User Query: The Starting Point
The process begins when a user submits a query or prompt to the local LLM application. This query could be a question, instruction, or conversation starter that the model must interpret and respond to appropriately. The user interface captures this input and passes it to the model processing pipeline.
Key considerations at this stage include:
- Input validation and preprocessing
- Character encoding handling
- Session management for conversational contexts
- Integration with the local application’s user interface
2. Load & Optimize: Preparing the Model for Execution
Before processing any inputs, the LLM must be loaded into memory and optimized for the specific hardware configuration. This complex stage involves several critical steps:
Loading the Model
The system loads the pre-trained model weights from storage into memory. For modern LLMs, these weights can range from hundreds of megabytes to dozens of gigabytes, depending on the model size. Loading involves:
- Reading model architecture specifications
- Loading parameter weights
- Initializing the computational graph
Mapping Model to Devices
Once loaded, the model must be mapped to available computational devices, such as:
- CPU cores
- GPU VRAM (if available)
- Specialized neural processing units (if available)
- RAM allocation
The system analyzes hardware capabilities and distributes the model accordingly, potentially splitting layers across different computational resources for optimal performance.
Quantization
To reduce memory requirements and accelerate inference, many local LLM implementations employ quantization techniques:
- Reducing numerical precision (e.g., from FP32 to INT8)
- Applying post-training quantization algorithms
- Using specialized quantization schemes like GPTQ or GGML formats
Quantization can reduce memory requirements by 2-4x while maintaining reasonable performance, making larger models viable on consumer hardware.
Buffer Allocation
The final preparation step involves allocating memory buffers for:
- Intermediate activations during inference
- Attention mechanism computations
- Token generation workspace
- Context management
Efficient buffer allocation is critical for performance, as it minimizes memory fragmentation and reduces unnecessary data transfers between different memory hierarchies.
3. Process Input: Transforming Text to Tokens
With the model ready for computation, the system must transform the raw text input into a format the model can process.
Raw Text Input
The system takes the user’s natural language query and prepares it for tokenization.
Tokenization
Tokenization converts the raw text into discrete tokens according to the model’s specific vocabulary:
- Splitting text into words, subwords, or characters
- Applying byte-pair encoding (BPE) or similar algorithms
- Converting tokens to their corresponding numerical IDs
- Handling special tokens (e.g., [START], [END], [PAD])
Modern tokenizers might produce different numbers of tokens for the same text length, depending on the frequency and patterns of language used.
Token Positions
The system assigns position information to each token:
- Sequential position IDs (1, 2, 3, …)
- Position encoding information for the transformer architecture
- Special positioning for different segments in multi-segment inputs
Position information is crucial for transformer-based LLMs as they lack inherent sequential processing capabilities.
Creating Embeddings
Each token ID is then converted to a high-dimensional vector (embedding):
- Looking up embeddings from the model’s embedding table
- Combining with positional encodings
- Preparing the initial input representation for the transformer layers
These embeddings typically have dimensions ranging from 768 to 4096 or more, depending on the model size.
4. Context Encoding: The Heart of Understanding
Context encoding is where the model applies its intelligence to understand the input and prepare for response generation.
Processing All Input Tokens
The system processes all input tokens through the model’s layers:
- Input embeddings flow through multiple transformer layers
- Each layer refines the representation based on learned patterns
- Attention mechanisms capture relationships between tokens
- Feed-forward networks transform these representations
This step is computationally intensive and typically accounts for a significant portion of the processing time.
Multi-Head Self-Attention
The self-attention mechanism is a defining feature of transformer-based LLMs:
- Multiple attention heads provide different “perspectives” on the input
- Each token attends to all other tokens with varying weights
- This captures complex relationships like syntax, semantics, and references
- The mechanism enables the model to understand context across arbitrary distances
In local implementations, attention computations are often optimized through techniques like flash attention or memory-efficient attention algorithms.
Generate Key-Value (KV) Pairs
As tokens pass through the model:
- Key and value vectors are generated for each token at each layer
- These KV pairs represent the processed information about each token
- They capture the contextual meaning and relationships between tokens
Store in KV Cache
To avoid redundant computations during generation:
- The system stores KV pairs in a dedicated cache
- This cache grows as more tokens are processed
- It serves as the model’s “memory” of the conversation or context
The KV cache size is proportional to:
- Context length × number of layers × embedding dimension
- This can quickly grow to gigabytes of memory for long contexts
5. Decode Phase: Generating the Response
With the input fully processed, the model enters the decoding phase to generate a response.
Embed Latest Token & Create Query
The system prepares to generate each new token:
- Initially, a special token (like [EOS] or [START_RESPONSE]) is embedded
- For subsequent tokens, the last generated token is embedded
- This embedding is used to create a query vector
Attend to KV Cache
The query vector interacts with the stored KV cache:
- Attention mechanisms compute relevance scores between the query and all cached keys
- This determines which parts of the context are most relevant for generating the next token
- The system combines the relevant values based on attention weights
Compute Logits
The model produces probability distributions over the vocabulary:
- The final layer transforms the attended representations into logits
- These logits represent unnormalized probabilities for each token in the vocabulary
- Typically involves a large matrix multiplication operation (vocab_size × embedding_dim)
Sampling
To select the next token:
- The system applies a softmax function to convert logits to probabilities
- Various sampling strategies may be employed:
- Temperature scaling to control randomness
- Top-k filtering to consider only the k most likely tokens
- Top-p (nucleus) sampling to dynamically filter the probability mass
- Beam search for exploring multiple possible continuations
Is Generation Finished?
After each token, the system checks if generation should continue:
- Detecting special end tokens
- Reaching maximum specified length
- Meeting other stopping criteria (e.g., specific phrases)
Detokenize
As tokens are generated, they are converted back to text:
- Mapping token IDs back to their text representations
- Handling subword merging and special cases
- Applying any post-processing rules
Accumulating Output
The system builds the response incrementally:
- Concatenating generated tokens into coherent text
- Managing formatting and presentation
- Streaming to the user interface when available
6. Logging & Monitoring: Ensuring Performance and Reliability
Throughout the entire process, the local LLM system maintains various metrics and logs:
Record Latencies per Kernel
The system tracks performance metrics for different operations:
- Token processing times
- Attention computation latencies
- Matrix multiplication speeds
- Generation time per token
These metrics help identify bottlenecks and optimization opportunities.
Memory Utilization Metrics
Memory management is critical for local deployments:
- Tracking peak memory usage
- Monitoring memory allocation patterns
- Detecting potential memory leaks
- Managing cache sizes adaptively
Throughput per Token-sec
Overall system performance is measured in tokens per second:
- Prefill throughput (processing the initial prompt)
- Generation throughput (producing new tokens)
- Efficiency under different workloads and context lengths
Error & Exception Handling
Robust error handling ensures system stability:
- Graceful handling of out-of-memory situations
- Recovery from computational errors
- Fallback strategies for exceptional cases
- User-friendly error messages
Technical Challenges and Optimizations for Local LLM Deployment
Running LLMs locally presents several technical challenges that require specialized optimizations:
Memory Constraints
Consumer devices typically have limited RAM compared to server environments:
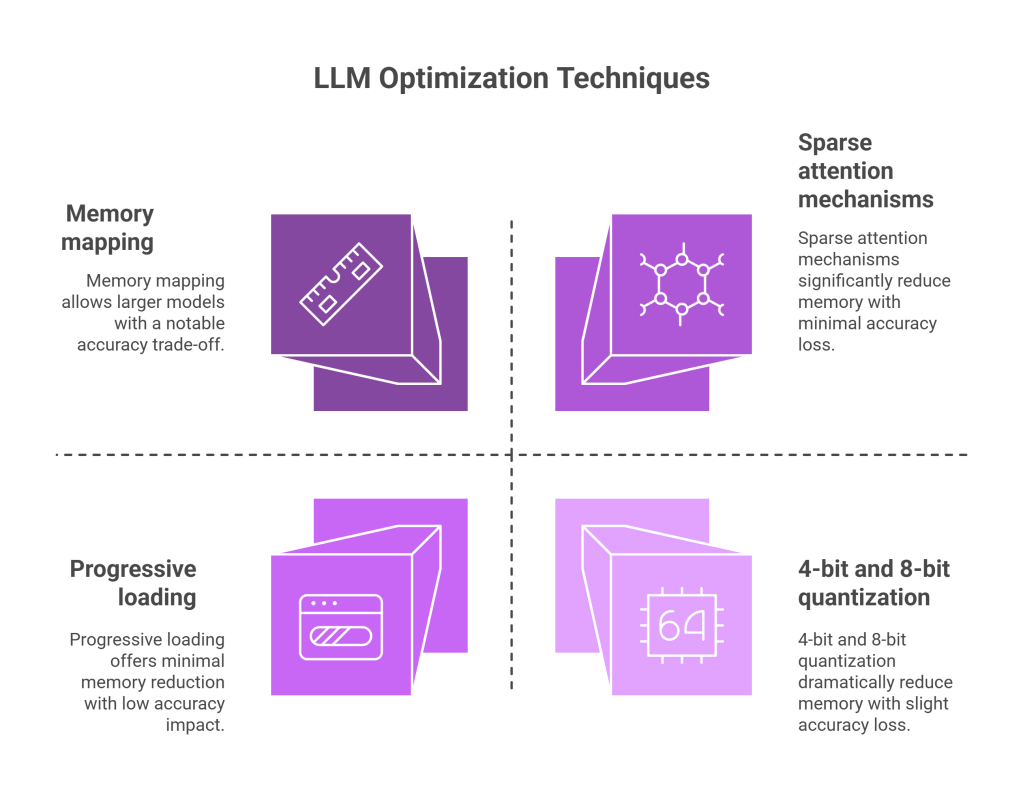
- 4-bit and 8-bit quantization: Trading slight accuracy for dramatically reduced memory footprint
- Sparse attention mechanisms: Reducing memory requirements by computing attention selectively
- Progressive loading: Loading model parts on-demand rather than all at once
- Memory mapping: Using disk space as extended memory for larger models
Computational Efficiency
Local devices often lack the computational power of data centers:
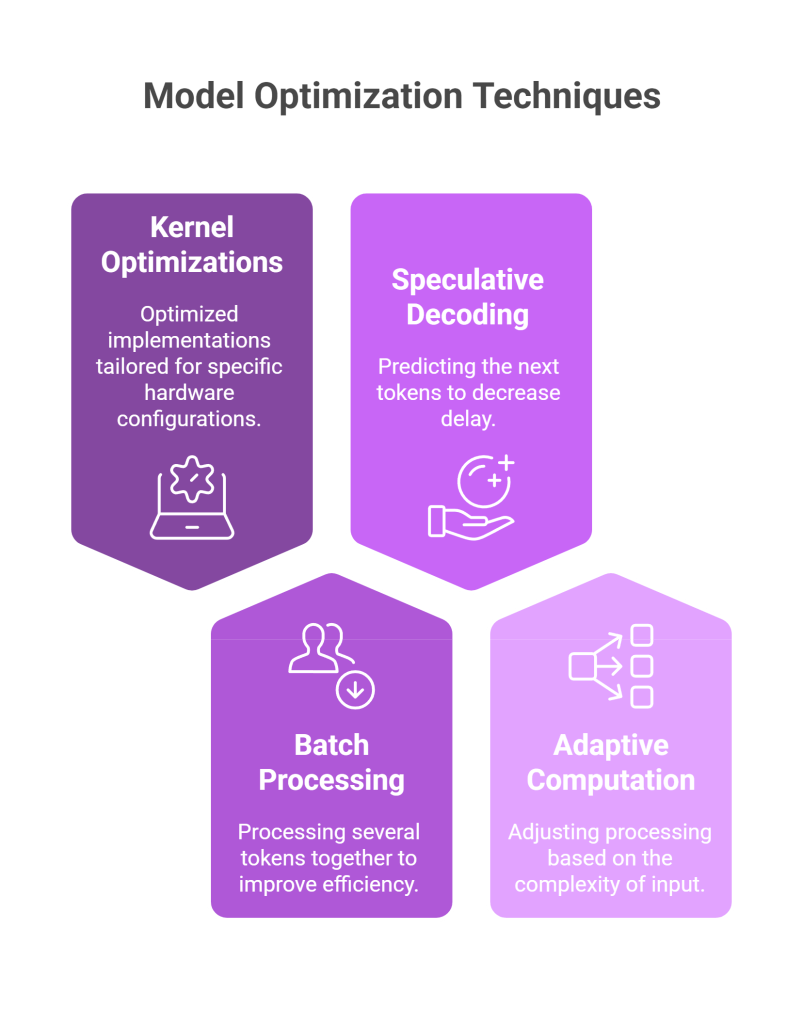
- Kernel optimizations: Hand-tuned implementations for specific hardware
- Batch processing: Processing multiple tokens simultaneously when possible
- Speculative decoding: Predicting likely next tokens to reduce latency
- Adaptive computation: Varying computational effort based on input complexity
Power and Thermal Management
Mobile and laptop devices must consider power consumption:
- Dynamic frequency scaling: Adjusting computational speed based on thermal conditions
- Workload scheduling: Distributing intensive computations to avoid thermal throttling
- Low-power modes: Offering energy-efficient inference options for battery-powered devices
User Experience Considerations
Local deployment must maintain responsive user experience:
- Progressive rendering: Showing partial results as tokens are generated
- Background loading: Initializing models without blocking user interaction
- Hybrid approaches: Combining local computation with optional cloud backup
- Intelligent scheduling: Prioritizing interactive tasks over background processing
Applications of Local LLMs
The ability to run LLMs locally enables numerous applications across various domains:
Privacy-Sensitive Use Cases
- Healthcare and legal assistance: Processing sensitive information without external data sharing
- Personal productivity tools: Managing private documents and communications
- Enterprise data analysis: Working with confidential business information
Offline Capabilities
- Field operations: AI assistance in remote locations without connectivity
- Disaster response: Maintaining AI capabilities during infrastructure disruptions
- Travel applications: Language translation and assistance regardless of connectivity
Embedded Systems
- Smart home devices: Adding contextual intelligence to IoT ecosystems
- Automotive systems: In-vehicle assistance without continuous cloud connectivity
- Industrial automation: Local intelligence for manufacturing and monitoring
Educational Applications
- Learning tools: Accessible AI assistance for educational environments
- Development environments: Code completion and assistance for programmers
- Research applications: Customizable AI models for academic projects
The Future of Local LLMs
The landscape of local LLM deployment continues to evolve rapidly:
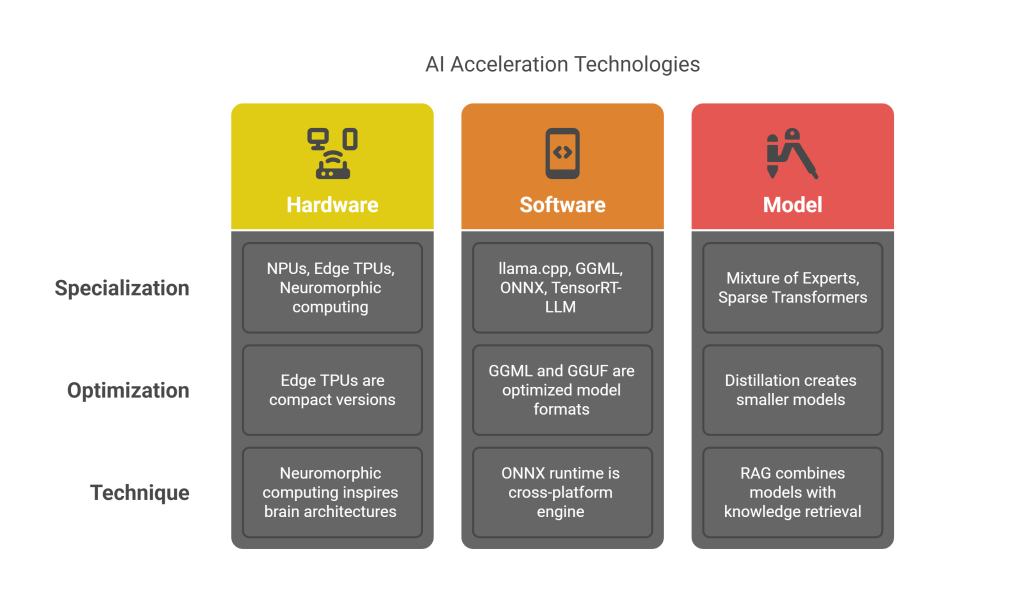
Hardware Acceleration
Dedicated hardware for AI acceleration is becoming more common:
- Neural Processing Units (NPUs): Specialized AI accelerators in consumer devices
- Edge TPUs and similar: Compact versions of data center AI accelerators
- Neuromorphic computing: Brain-inspired architectures optimized for neural networks
Software Frameworks
Specialized frameworks for local deployment are maturing:
- llama.cpp: High-performance C++ inference for various LLM architectures
- GGML and GGUF: Optimized model formats for local deployment
- ONNX Runtime: Cross-platform, high-performance engine for model inference
- TensorRT-LLM: NVIDIA’s optimized framework for LLM inference
Model Innovations
Research continues to make models more efficient:
- Mixture of Experts (MoE): Activating only relevant parts of the model for each input
- Sparse Transformers: Reducing computational complexity through sparse attention patterns
- Distillation techniques: Creating smaller models that retain capabilities of larger ones
- Retrieval-Augmented Generation (RAG): Combining smaller models with efficient knowledge retrieval
Conclusion: Democratizing AI Through Local Deployment
The ability to run LLMs locally represents a significant step toward democratizing access to advanced AI capabilities. As hardware continues to improve and software optimizations advance, we can expect increasingly powerful models to become available for local deployment.
Local LLMs offer a compelling vision of AI that respects user privacy, operates reliably regardless of connectivity, and puts computational intelligence directly in the hands of users. Understanding the complex processes involved in making these systems work efficiently on consumer hardware provides valuable insights for developers, researchers, and enthusiasts looking to leverage these technologies.
As the field continues to evolve, the balance between model capability, computational efficiency, and accessibility will drive innovation, potentially reshaping how we interact with AI in our daily lives. The technical challenges of local deployment have sparked creative solutions that benefit the entire AI ecosystem, making advanced language models more accessible and useful than ever before.
Discover more from SkillWisor
Subscribe to get the latest posts sent to your email.
