

Selecting the right machine learning algorithm can make or break your project. With dozens of algorithms available, each with unique strengths and weaknesses, choosing the optimal approach often feels overwhelming. This comprehensive guide provides a structured framework to help you navigate algorithm selection systematically, ensuring you pick the best tool for your specific problem.
Understanding the Foundation: Problem Types Drive Algorithm Choice
The first step in algorithm selection is clearly defining your problem type. Machine learning problems generally fall into six main categories, each with distinct characteristics and optimal algorithmic approaches.
Classification Problems: Predicting Discrete Categories
Classification involves predicting discrete categories or classes from input data. Whether you’re building a spam detector, medical diagnosis system, or customer segmentation model, the right classification algorithm depends on your specific requirements.

Logistic Regression serves as an excellent starting point for most classification problems. Its simplicity and speed make it ideal for establishing baselines and understanding feature relationships. The algorithm provides interpretable coefficients, allowing you to understand which features most influence predictions. Use logistic regression when you need quick results, transparent decision-making processes, or when working with linearly separable data.
Decision Trees excel when interpretability is paramount. These algorithms create clear, human-readable rules that stakeholders can easily understand and validate. They naturally handle non-linear relationships and mixed data types without requiring extensive preprocessing. Decision trees work particularly well for business rule extraction, regulatory compliance scenarios, or when you need to explain decisions to non-technical audiences.
Random Forest algorithms combine multiple decision trees to create powerful ensemble models. They typically deliver superior performance compared to single trees while maintaining reasonable interpretability. Random forests handle overfitting well and provide feature importance scores, making them excellent for exploratory data analysis and production systems where you need both accuracy and insights.
XGBoost and LightGBM represent the gold standard for many machine learning competitions and high-performance applications. These gradient boosting algorithms iteratively improve predictions by learning from previous mistakes. They consistently deliver state-of-the-art results across diverse domains but require careful hyperparameter tuning and more computational resources.
Support Vector Machines (SVM) shine in high-dimensional spaces where the number of features exceeds the number of samples. They’re particularly effective for text classification, bioinformatics, and image recognition tasks. SVMs work well with sparse data and can handle non-linear relationships through kernel tricks.
K-Nearest Neighbors (KNN) offers a simple, non-parametric approach that makes no assumptions about data distribution. While conceptually straightforward and effective for many problems, KNN becomes computationally expensive with large datasets and suffers from the curse of dimensionality.
Regression Problems: Predicting Continuous Values
Regression algorithms predict continuous numerical values, from house prices to stock returns to temperature forecasts
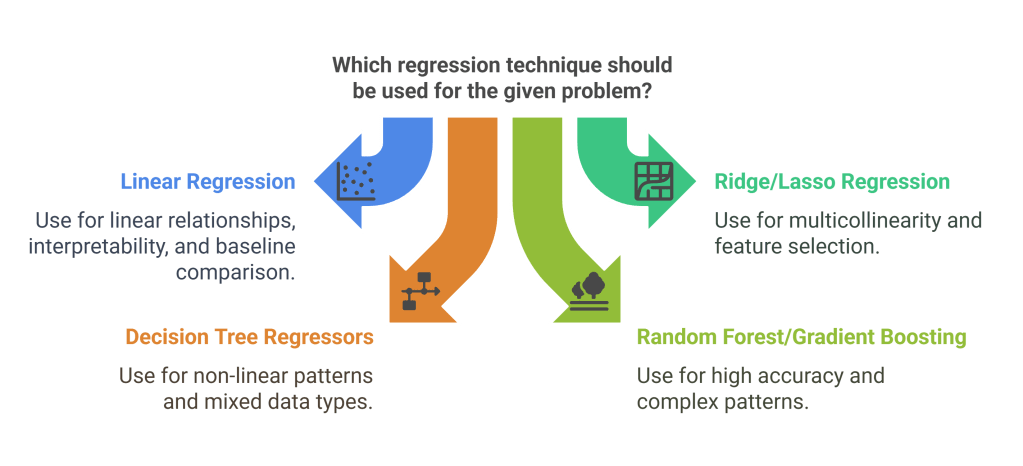
Linear Regression provides the foundation for understanding relationships between variables. Its interpretability and mathematical simplicity make it invaluable for hypothesis testing and understanding feature impacts. Use linear regression when relationships appear linear, when you need transparent models, or as a baseline for comparison.
Ridge and Lasso Regression extend linear regression with regularization techniques to combat overfitting. Ridge regression shrinks coefficients toward zero while maintaining all features, whereas Lasso can eliminate features entirely by setting coefficients to zero. These techniques prove essential when dealing with multicollinearity or when you need automatic feature selection.
Decision Tree Regressors capture complex non-linear patterns in data without assuming specific functional forms. They handle mixed data types naturally and provide clear decision paths. However, single trees often overfit, making ensemble methods more practical for production use.
Random Forest and Gradient Boosting Regressors typically deliver superior performance by combining multiple models. These ensemble methods reduce overfitting while capturing complex patterns in data. They’re often the go-to choice for regression problems where accuracy matters more than interpretability.
Clustering: Discovering Hidden Patterns
Clustering algorithms group similar data points without labeled examples, revealing hidden structures in your data.
K-Means clustering works best when clusters are roughly spherical and similar in size. It’s computationally efficient and scales well to large datasets. However, you must specify the number of clusters beforehand, and the algorithm struggles with non-spherical cluster shapes or varying cluster densities.
DBSCAN excels at finding clusters of arbitrary shapes and automatically determines the number of clusters. It’s particularly effective at identifying outliers and works well with varying cluster densities. DBSCAN requires careful parameter tuning but doesn’t assume specific cluster shapes.
Hierarchical Clustering builds a tree of clusters, allowing you to explore clustering at different granularities. It’s particularly useful for understanding data structure and doesn’t require specifying cluster numbers upfront. However, it’s computationally expensive for large datasets.
Dimensionality Reduction: Simplifying Complex Data
High-dimensional data often contains redundant information and suffers from the curse of dimensionality. Dimensionality reduction techniques help by preserving essential information while reducing computational complexity.
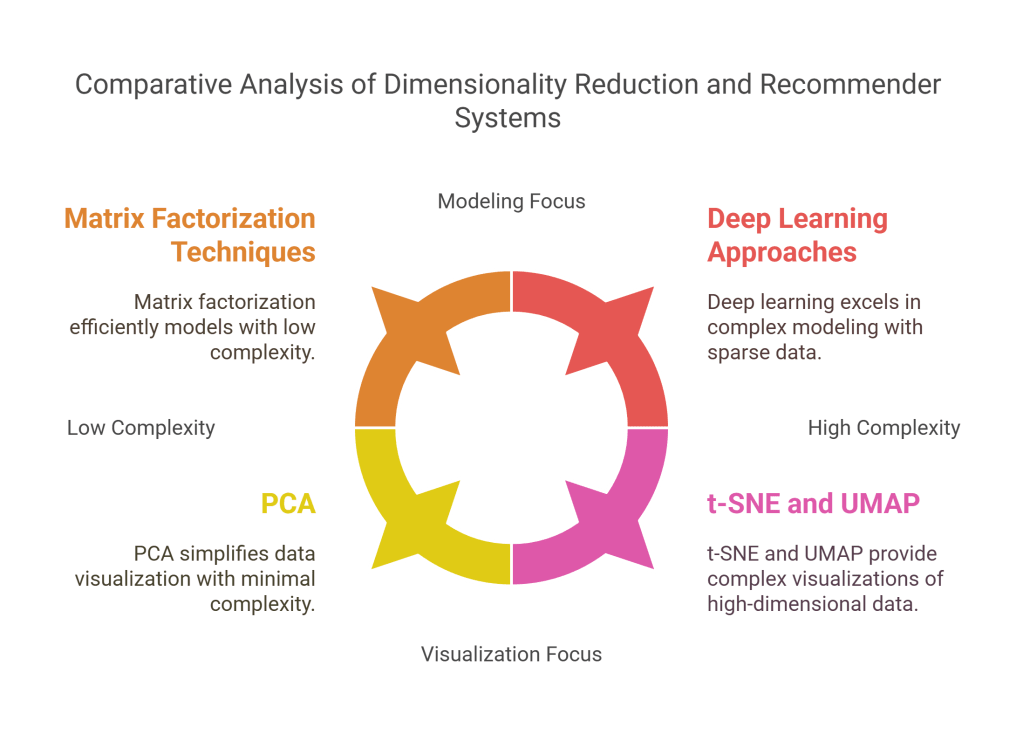
Principal Component Analysis (PCA) reduces dimensionality while preserving maximum variance in the data. It’s excellent for data compression, noise reduction, and visualization. PCA works best with continuous variables and linear relationships but may struggle with non-linear patterns.
t-SNE and UMAP excel at creating 2D or 3D visualizations of high-dimensional data. These techniques preserve local neighborhoods and reveal cluster structures that might be hidden in high-dimensional space. However, they’re primarily designed for visualization rather than modeling and can be computationally intensive.
Recommender Systems: Personalizing User Experiences
Recommender systems predict user preferences and suggest relevant items, from movies to products to content.
Collaborative Filtering leverages user-item interactions to make recommendations. It identifies users with similar preferences or items with similar characteristics. This approach works well when you have substantial interaction data but struggles with new users or items (the cold start problem).
Matrix Factorization techniques like Singular Value Decomposition (SVD) decompose user-item interaction matrices into latent factors representing underlying preferences. These methods handle sparse data well and can capture complex user-item relationships.
Deep Learning approaches using neural networks excel when dealing with complex, sparse data and can incorporate multiple types of information (user profiles, item features, contextual data). They’re particularly effective for content-based filtering and handling cold start problems.
Deep Learning: Tackling Complex, Unstructured Data
Neural networks and deep learning algorithms excel with large datasets containing unstructured information like images, text, audio, or complex patterns.
Deep learning becomes the preferred choice when dealing with:
- Large datasets where traditional algorithms plateau in performance
- Unstructured data like images, natural language, or audio
- Complex patterns that require multiple layers of abstraction
- End-to-end learning where manual feature engineering is impractical
However, deep learning requires substantial computational resources, large amounts of training data, and careful architecture design. It’s often overkill for structured tabular data where traditional algorithms perform equally well with less complexity.
Practical Decision Framework
When facing algorithm selection, follow this systematic approach:
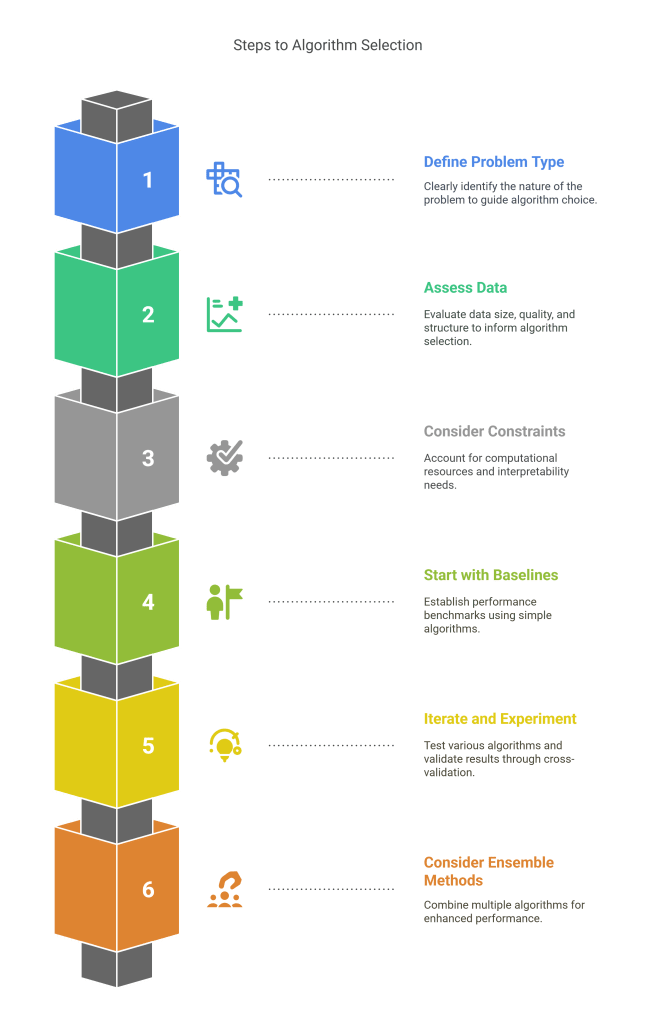
- Define your problem type clearly – Classification, regression, clustering, dimensionality reduction, recommendation, or deep learning
- Assess your data characteristics – Size, dimensionality, quality, structure, and available labels
- Consider your constraints – Interpretability requirements, computational resources, training time, and deployment environment
- Start with simple baselines – Establish performance benchmarks with straightforward algorithms
- Iterate and experiment – Test multiple approaches and use cross-validation for robust evaluation
- Consider ensemble methods – Combine multiple algorithms for improved performance
Key Considerations for Algorithm Selection
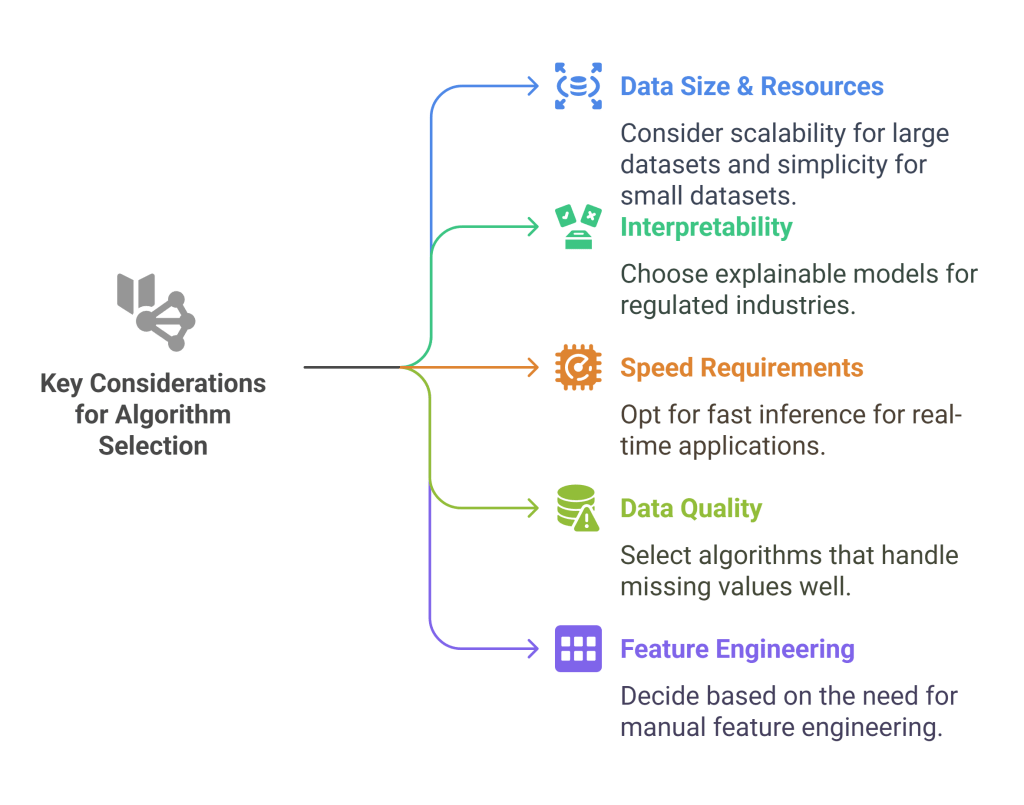
Data Size and Computational Resources: Large datasets may require scalable algorithms like gradient boosting or deep learning, while smaller datasets might benefit from simpler approaches that avoid overfitting.
Interpretability Requirements: Regulated industries or critical applications often require explainable models, favoring decision trees, linear models, or other interpretable algorithms over black-box approaches.
Training and Inference Speed: Real-time applications need fast inference, while batch processing systems can tolerate slower but more accurate algorithms.
Data Quality and Preprocessing: Some algorithms handle missing values and mixed data types better than others. Consider preprocessing requirements when selecting algorithms.
Feature Engineering Needs: Some algorithms require extensive feature engineering, while others (particularly deep learning) can learn features automatically.
Conclusion
Algorithm selection is both an art and a science. While this framework provides structured guidance, the best approach often involves experimentation and iteration. Start with simple baselines, understand your data thoroughly, and gradually explore more complex algorithms as needed. Remember that the most sophisticated algorithm isn’t always the best choice – sometimes a simple, well-understood model that stakeholders trust delivers more value than a complex but opaque solution.
The key to successful machine learning projects lies not just in algorithm selection, but in understanding your problem deeply, preparing your data carefully, and choosing algorithms that balance performance with practical constraints. Use this guide as a starting point, but always validate your choices through rigorous experimentation and evaluation.
Discover more from SkillWisor
Subscribe to get the latest posts sent to your email.
