

Machine Learning (ML) is no longer a futuristic concept; it’s an integral part of our present, shaping industries from healthcare and finance to entertainment and transportation. In 2025, the field continues its explosive growth, driven by advancements in data availability, computational power, and innovative algorithms. If you’re looking to enter this dynamic domain, whether for a career change, skill enhancement, or pure intellectual curiosity, learning Machine Learning from scratch might seem daunting. However, with a structured approach, dedication, and the right resources, it’s an achievable and incredibly rewarding endeavor.
This comprehensive guide will walk you through everything you need to know to begin your machine learning journey in 2025, from foundational prerequisites to advanced concepts, practical application, and staying ahead of the curve.
The Landscape of Machine Learning in 2025
Before diving into how to learn, it’s crucial to understand what the ML landscape looks like in 2025. This field is evolving at a rapid pace, and certain trends are defining its direction:

- Generative AI Continues to Dominate: Beyond just analysis, models are now capable of creating new content – text, images, audio, and even code. Large Language Models (LLMs) and diffusion models are at the forefront, revolutionizing how we interact with technology and driving new applications.
- Multimodal AI Systems: The future of AI is not limited to processing a single type of data. Multimodal AI, which can understand and generate content across various data types (text, images, video, audio) simultaneously, is gaining significant traction, leading to more human-like and versatile AI applications.
- Explainable AI (XAI) and Ethical AI: As ML models become more complex and are deployed in critical applications (e.g., healthcare, finance), the need to understand their decisions (explainability) and ensure fairness, transparency, and accountability (ethical AI) is paramount. Regulatory frameworks are also evolving, making XAI and ethical considerations crucial.
- Edge AI and Distributed Intelligence: Instead of solely relying on powerful cloud servers, AI processing is moving closer to the data source (edge devices like smartphones, IoT gadgets). This reduces latency, enhances privacy, and enables real-time decision-making in diverse environments. Federated learning, where models are trained on decentralized data without explicit data sharing, is a key enabler.
- Automated Machine Learning (AutoML): AutoML tools are making ML more accessible to non-experts by automating various stages of the machine learning pipeline, from data preprocessing and feature engineering to model selection and hyperparameter tuning.
- AI for Sustainability and Social Good: Machine learning is increasingly being applied to address global challenges such as climate change (optimizing energy usage, predicting weather patterns), healthcare (drug discovery, personalized medicine), and humanitarian efforts.
- Quantum Machine Learning (QML): While still in its nascent stages, quantum computing’s potential to solve complex ML problems faster than classical computers is being explored, promising breakthroughs in areas like drug discovery and financial modeling.
Understanding these trends will help you tailor your learning path and identify areas of specialization that align with future industry demands.
Phase 1: Building a Strong Foundation (Months 1-3)
Learning Machine Learning isn’t about memorizing algorithms; it’s about understanding the underlying principles. This requires a solid foundation in mathematics and programming.

1. Mathematics: The Language of Machine Learning
Many aspiring ML engineers skip the math, but it’s the bedrock upon which all algorithms are built. A strong grasp of these areas will enable you to understand why algorithms work, debug them effectively, and innovate.
- Linear Algebra:
- Concepts: Vectors, matrices, tensors, matrix operations (addition, multiplication, transpose, inverse), dot product, eigenvalues, eigenvectors, determinants, linear transformations.
- Why it’s important: Essential for representing and manipulating data (e.g., images, text embeddings), understanding dimensionality reduction techniques (PCA), and the mechanics of neural networks.
- Resources:
- Khan Academy: Linear Algebra
- “Essence of Linear Algebra” by 3Blue1Brown (YouTube series)
- Linear Algebra and Its Applications by Gilbert Strang
- Calculus:
- Concepts: Derivatives, gradients, partial derivatives, chain rule, integration, optimization techniques (gradient descent).
- Why it’s important: Crucial for understanding how machine learning models learn and optimize their parameters (e.g., backpropagation in neural networks, cost functions).
- Resources:
- Khan Academy: Multivariable Calculus
- “Essence of Calculus” by 3Blue1Brown (YouTube series)
- Probability and Statistics:
- Concepts: Descriptive statistics (mean, median, mode, standard deviation, variance), inferential statistics (hypothesis testing, confidence intervals), probability theory (Bayes’ theorem, conditional probability, probability distributions like Gaussian, Bernoulli, Binomial), random variables.
- Why it’s important: Fundamental for data analysis, understanding data distributions, hypothesis testing, model evaluation, and probabilistic models (e.g., Naive Bayes, Hidden Markov Models).
- Resources:
- Khan Academy: Statistics and Probability
- Think Stats by Allen B. Downey
- Coursera: “Probability and Statistics for Data Science with Python”
2. Programming: Your ML Toolkit
Python is the undisputed king of Machine Learning. Its extensive ecosystem of libraries and frameworks makes it the language of choice for development and research.
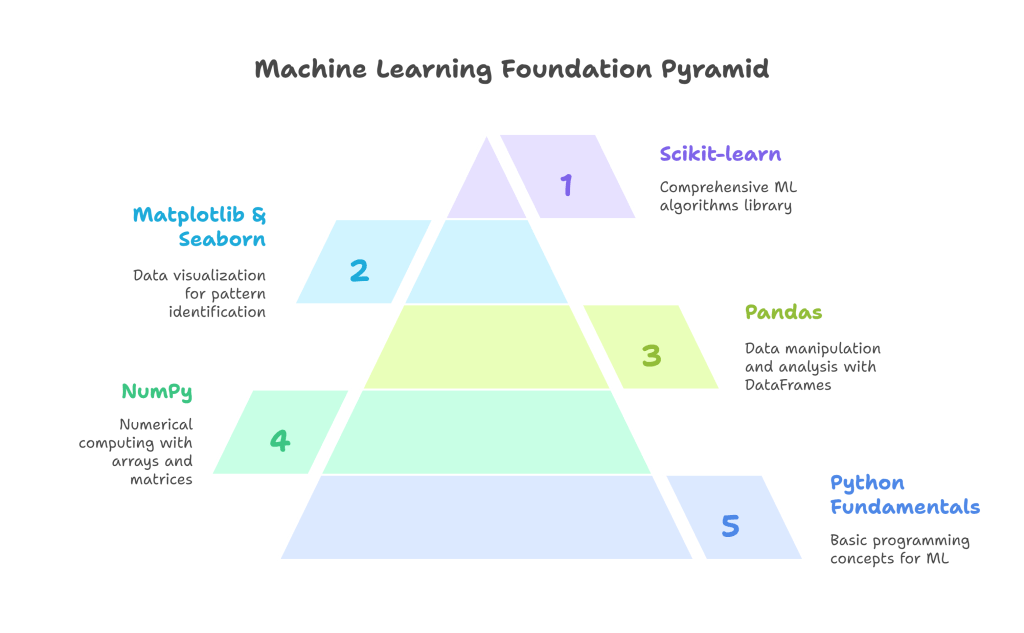
- Python Fundamentals:
- Concepts: Variables, data types (lists, dictionaries, sets, tuples), control flow (if/else, for loops, while loops), functions, classes and objects (basic OOP), error handling, modules, and packages.
- Why it’s important: You’ll be writing, debugging, and understanding ML code daily.
- Resources:
- Codecademy: Learn Python 3
- “Python for Everybody” by University of Michigan (Coursera)
- Automate the Boring Stuff with Python
- Essential Python Libraries for ML:
- NumPy: For numerical computing, especially with arrays and matrices. It’s the backbone of many other scientific libraries.
- Pandas: For data manipulation and analysis, offering powerful data structures like DataFrames. Essential for cleaning, transforming, and exploring datasets.
- Matplotlib & Seaborn: For data visualization. These libraries are crucial for understanding your data, identifying patterns, and presenting your findings.
- Scikit-learn: A comprehensive library for traditional machine learning algorithms (regression, classification, clustering, dimensionality reduction) with a consistent API.
- Official documentation for each library (excellent tutorials and examples).
- Kaggle micro-courses (e.g., Pandas, Matplotlib, Intro to ML).
Phase 2: Core Machine Learning Concepts and Algorithms (Months 4-7)
Once you have a strong foundation, you can dive into the heart of Machine Learning. This phase focuses on understanding different types of ML and their core algorithms.
1. Introduction to Machine Learning
- What is Machine Learning?
- Definition, distinction from traditional programming, and its various applications.
- Types of ML: Supervised, Unsupervised, Reinforcement Learning.
- Machine Learning Workflow:
- Problem definition, data collection, data preprocessing (cleaning, handling missing values, feature scaling), exploratory data analysis (EDA), feature engineering, model selection, training, evaluation, hyperparameter tuning, deployment, and monitoring.
2. Supervised Learning
Models learn from labeled data (input-output pairs) to make predictions.
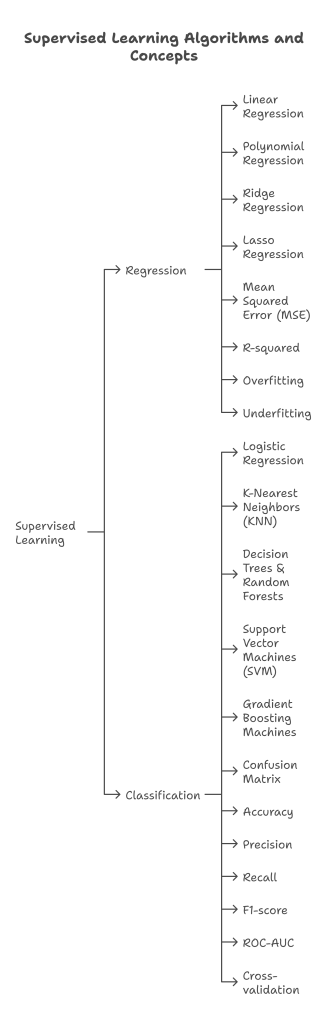
- Regression: Predicting continuous output values.
- Algorithms: Linear Regression, Polynomial Regression, Ridge Regression, Lasso Regression.
- Concepts: Mean Squared Error (MSE), R-squared, overfitting, underfitting.
- Classification: Predicting discrete class labels.
- Algorithms:
- Logistic Regression: Binary classification.
- K-Nearest Neighbors (KNN): Non-parametric, instance-based learning.
- Decision Trees & Random Forests: Tree-based ensemble methods, good for interpretability.
- Support Vector Machines (SVM): Finds the optimal hyperplane for classification.
- Gradient Boosting Machines (XGBoost, LightGBM, CatBoost): Powerful ensemble methods for high performance.
- Concepts: Confusion matrix, accuracy, precision, recall, F1-score, ROC-AUC, cross-validation.
- Algorithms:
3. Unsupervised Learning
Models learn from unlabeled data to find patterns or structures.
- Clustering: Grouping similar data points together.
- Algorithms: K-Means, Hierarchical Clustering, DBSCAN.
- Concepts: Elbow method, silhouette score.
- Dimensionality Reduction: Reducing the number of features while preserving important information.
- Algorithms: Principal Component Analysis (PCA), t-SNE (for visualization).
- Concepts: Variance explained.
- Association Rule Mining: Discovering relationships between variables in large databases (e.g., market basket analysis).
4. Deep Learning Fundamentals
A subset of Machine Learning inspired by the structure and function of the human brain.

- Neural Networks:
- Concepts: Neurons, activation functions (ReLU, Sigmoid, Tanh, Softmax), layers (input, hidden, output), weights, biases, forward propagation, backpropagation, loss functions.
- Architectures:
- Feedforward Neural Networks (FNNs) / Multi-Layer Perceptrons (MLPs): Basic neural networks.
- Convolutional Neural Networks (CNNs): Primarily for image data (computer vision tasks like image classification, object detection).
- Recurrent Neural Networks (RNNs) & LSTMs/GRUs: For sequential data (Natural Language Processing, time series forecasting).
- Transformers: Revolutionized NLP, enabling models like BERT and GPT.
- Deep Learning Frameworks:
- TensorFlow & Keras: Keras is a high-level API for building neural networks, making it user-friendly, while TensorFlow provides the low-level computations.
- PyTorch: A more “Pythonic” and flexible framework, favored by researchers.
5. Reinforcement Learning (Optional, but Recommended)
Training agents to make a sequence of decisions in an environment to maximize a cumulative reward.
- Concepts: Agent, environment, state, action, reward, policy, value function.
- Algorithms: Q-Learning, SARSA, Deep Q-Networks (DQN).
- Applications: Robotics, game playing (AlphaGo, Atari games), autonomous systems.
Phase 3: Applied Machine Learning and Specialization (Months 8-12)
Now that you understand the core concepts, it’s time to apply your knowledge and potentially specialize.
1. Data Collection and Preparation
This is often the most time-consuming part of an ML project but also the most critical.
- Sources: APIs, databases (SQL, NoSQL), public datasets (Kaggle, UCI Machine Learning Repository).
- Techniques: Data cleaning (handling missing values, outliers, inconsistencies), data transformation (normalization, standardization), feature engineering (creating new features from existing ones), data augmentation (for images/text).
2. Model Evaluation and Tuning
- Metrics: Beyond basic accuracy, understand appropriate metrics for different problems (e.g., F1-score for imbalanced classes, MAPE for regression forecasting).
- Hyperparameter Tuning: Techniques like Grid Search, Random Search, Bayesian Optimization to find the best model configurations.
- Cross-validation: Robust methods to assess model performance and prevent overfitting.
3. MLOps (Machine Learning Operations)
Bridging the gap between ML development and production deployment.
- Concepts: Version control (Git), experiment tracking, model serving (Flask, FastAPI), containerization (Docker), orchestration (Kubernetes), monitoring model performance in production, CI/CD for ML.
- Cloud Platforms: Familiarize yourself with ML services offered by major cloud providers:
- AWS: SageMaker, EC2, S3, Lambda
- Google Cloud Platform (GCP): Vertex AI, BigQuery ML, Compute Engine
- Azure Machine Learning: Azure ML Studio, Azure Kubernetes Service (AKS)
4. Specialization Areas (Choose one or two to deep dive)

- Natural Language Processing (NLP):
- Concepts: Text preprocessing, word embeddings (Word2Vec, GloVe), Recurrent Neural Networks (RNNs, LSTMs, GRUs), Transformers (BERT, GPT, T5), attention mechanisms.
- Tasks: Sentiment analysis, text classification, machine translation, named entity recognition, question answering, text summarization, generative text.
- Computer Vision (CV):
- Concepts: Image processing fundamentals, Convolutional Neural Networks (CNNs), transfer learning, object detection (YOLO, Faster R-CNN), image segmentation (U-Net, Mask R-CNN), Generative Adversarial Networks (GANs).
- Tasks: Image classification, object detection, facial recognition, image generation, style transfer.
- Time Series Analysis:
- Concepts: Stationarity, ARIMA, Prophet, LSTMs for time series.
- Tasks: Stock price prediction, demand forecasting, anomaly detection in time-series data.
- Recommendation Systems:
- Concepts: Collaborative filtering (user-based, item-based), content-based filtering, hybrid approaches, matrix factorization.
- Tasks: Recommending movies, products, or articles.
Phase 4: Hands-on Projects and Portfolio Building (Ongoing)
Theory alone is insufficient. Applied learning through projects is crucial.
1. Start Small, Build Progressively
- Beginner Projects: Use well-known datasets (Iris, MNIST, Titanic) to implement basic algorithms from scratch or using Scikit-learn. Focus on understanding the data, applying a simple model, and evaluating its performance.
- Intermediate Projects: Tackle more complex datasets, experiment with different algorithms, perform extensive feature engineering, and optimize hyperparameters. Explore problems in areas like sentiment analysis, image classification (using pre-trained CNNs), or house price prediction.
- Advanced Projects: Address real-world problems, work with unstructured data, combine multiple ML techniques, deploy models, and incorporate MLOps practices. Consider contributing to open-source projects.
2. Where to Find Projects and Datasets:
- Kaggle: An invaluable platform for datasets, code notebooks, and competitions. Participating in competitions provides structured problems and allows you to learn from top practitioners.
- UCI Machine Learning Repository: A vast collection of datasets for various ML tasks.
- GitHub: Explore public repositories for project ideas, code, and inspiration.
- Your own ideas: Identify problems in your daily life or industry that ML could solve.
3. Building a Strong Portfolio:
Your portfolio is your resume in the ML world. It showcases your skills and problem-solving abilities.
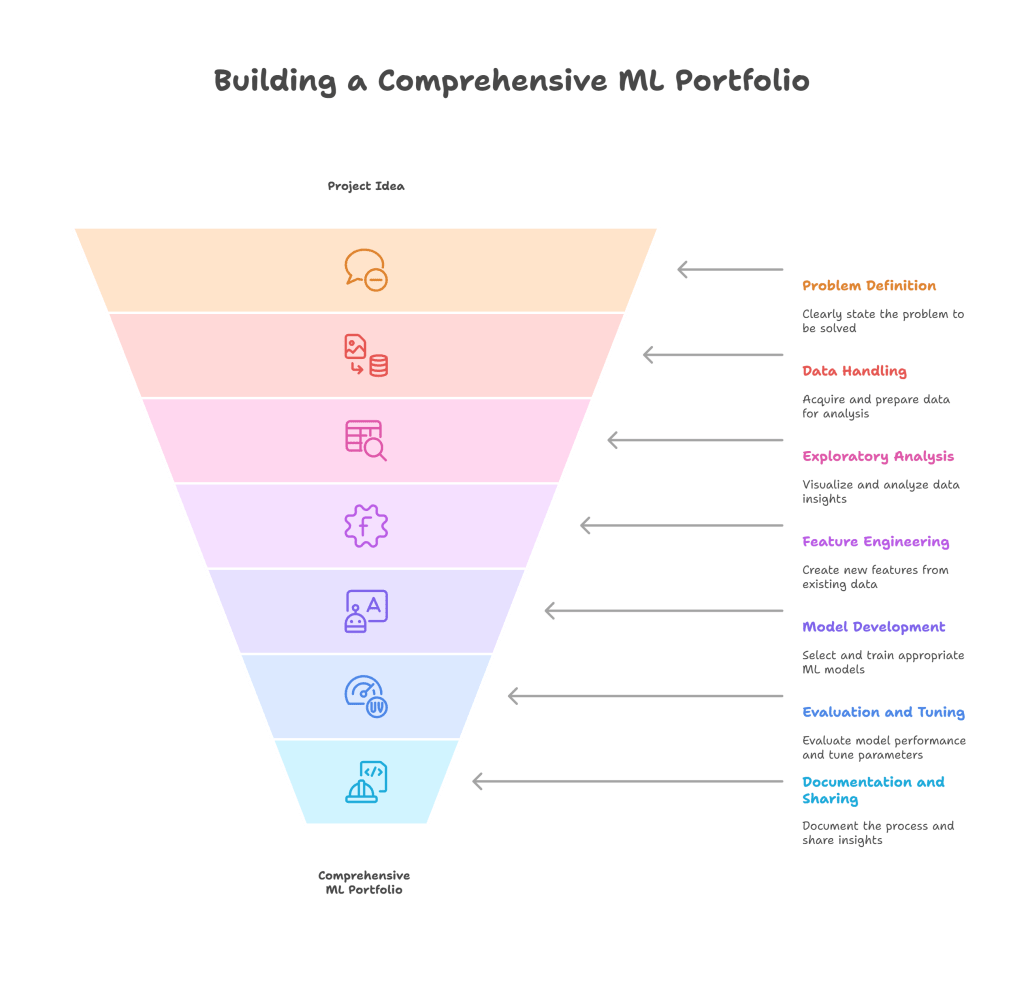
- Showcase Diversity: Include projects that demonstrate a range of ML techniques (supervised, unsupervised, deep learning) and applications (NLP, CV, tabular data).
- Focus on the Workflow: Don’t just show the final model. Document your entire process:
- Problem Statement: Clearly define what problem you’re solving.
- Data Acquisition & Cleaning: Explain how you got and prepared the data.
- Exploratory Data Analysis (EDA): Present your insights through visualizations.
- Feature Engineering: Describe how you created new features.
- Model Selection & Training: Justify your algorithm choices and training process.
- Evaluation & Tuning: Discuss metrics, hyperparameter tuning, and cross-validation.
- Results & Insights: Explain the model’s performance and what you learned.
- Deployment (if applicable): Show how you would put the model into production.
- Code Quality and Documentation: Your code should be clean, well-commented, and organized. Use README files extensively in your GitHub repositories to explain each project.
- Blog Posts/Articles: Write about your projects, challenges you faced, and solutions you found. This demonstrates your ability to communicate complex ideas and reinforces your understanding.
- Host Your Work: Use GitHub for code, and consider a personal website or platforms like Medium/Towards Data Science to host your explanations and visualizations.
Recommended Learning Resources in 2025
The internet is overflowing with ML resources. Here are some highly recommended ones:
Online Courses & Specializations:
- Coursera:
- “Machine Learning” by Andrew Ng (Stanford University / DeepLearning.AI): A classic and excellent starting point for traditional ML.
- “Deep Learning Specialization” by Andrew Ng (DeepLearning.AI): Comprehensive for deep learning fundamentals and applications.
- “Machine Learning Engineering for Production (MLOps)” Specialization (DeepLearning.AI): Crucial for understanding real-world deployment.
- “Mathematics for Machine Learning” (Imperial College London): Excellent for shoring up math foundations.
- edX:
- “Applied Data Science with Python” (University of Michigan): Covers Python, Pandas, Matplotlib, and ML with Scikit-learn.
- “HarvardX: Data Science Professional Certificate”: A broad curriculum covering statistics, R (though you can apply concepts to Python), and ML.
- fast.ai: “Practical Deep Learning for Coders”: A highly practical, top-down approach to deep learning, focusing on getting models working quickly.
- Google AI Education: “Machine Learning Crash Course”: A fast-paced, practical introduction with TensorFlow.
- Udacity: “Machine Learning Engineer Nanodegree”: A structured program that covers theory and hands-on projects.
Books:
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow by Aurélien Géron: Highly practical, covering fundamental concepts and advanced techniques.
- Deep Learning by Ian Goodfellow, Yoshua Bengio, and Aaron Courville: The academic bible for deep learning (more advanced).
- An Introduction to Statistical Learning by Gareth James et al.: Excellent for statistical concepts behind ML algorithms (available free online).
- Python for Data Analysis by Wes McKinney: The authoritative guide to Pandas.
Communities & Blogs:
- Kaggle Forums: Discuss solutions, learn from others.
- Towards Data Science (Medium): A popular publication with articles on various ML topics.
- Analytics Vidhya, KDnuggets: Offer tutorials, articles, and industry insights.
- Stack Overflow: For troubleshooting coding issues.
- Reddit: r/MachineLearning, r/datascience.
Staying Updated in 2025
Machine learning is a field of constant innovation. To remain relevant, continuous learning is non-negotiable.
- Follow Research: Keep an eye on new papers on arXiv (especially in areas like NLP, CV, Generative Models). Major conferences like NeurIPS, ICML, ICLR, ACL are key.
- Read Blogs & Newsletters: Subscribe to newsletters from leading AI labs (e.g., Google AI, OpenAI, DeepMind, Meta AI) and prominent ML researchers/practitioners.
- Experiment with New Tools & Frameworks: Be open to trying out new libraries, models, and cloud services as they emerge.
- Participate in Competitions: Kaggle and other platforms frequently host competitions that challenge you with cutting-edge problems and datasets.
- Network: Engage with the ML community online and at local meetups or conferences.
Common Pitfalls to Avoid
- Skipping the Math: It might seem tedious, but it will severely limit your understanding and ability to tackle complex problems.
- Tutorial Hell: Continuously following tutorials without building your own projects. You learn by doing.
- Ignoring Fundamentals: Jumping straight to deep learning without understanding basic supervised/unsupervised learning.
- Not Version Controlling: Always use Git and GitHub for your code.
- Neglecting Data Preprocessing: “Garbage in, garbage out” applies here. Clean and well-engineered data are critical.
- Overfitting to Benchmarks: Don’t just optimize for public leaderboards; understand the underlying problem and ensure your model generalizes well.
- Fear of Failure: ML is iterative. Models will fail, predictions will be off. Learn from mistakes and iterate.
Conclusion
Learning Machine Learning from scratch in 2025 is an ambitious but highly achievable goal. It demands a blend of mathematical understanding, programming prowess, and a relentless curiosity to explore and apply new concepts. By meticulously building your foundational knowledge, diving into core algorithms, specializing in areas that pique your interest, and consistently applying your skills through hands-on projects, you will not only gain a robust understanding of the field but also build a compelling portfolio that opens doors to exciting opportunities.
Embrace the journey, stay persistent, and remember that every line of code written, every error debugged, and every model built brings you closer to mastering this transformative technology. The future of AI is being written, and with this guide, you have the roadmap to be one of its authors. Good luck!
Discover more from SkillWisor
Subscribe to get the latest posts sent to your email.
