

In the rapidly evolving landscape of Artificial Intelligence (AI) and Machine Learning (ML), models are increasingly moving beyond single-source data processing to interpret and understand information from multiple modalities simultaneously. This advanced capability is powered by Multi-Modal Data Annotation, a crucial process that labels and describes data combining various types such as text, images, video, and audio. This guide will delve into what multi-modal annotation entails, its diverse types, critical applications, and the significant risks associated with improper annotation.
What is Multi-Modal Data Annotation?
Multi-modal data annotation is the process of labeling and categorizing data that originates from two or more distinct modalities. Unlike traditional single-modal annotation, where only one type of input (e.g., just images or just text) is labeled, multi-modal annotation ensures that labels across different data formats are aligned, consistent, and interoperable. This integrated approach allows AI models to synthesize inputs for richer context and more accurate predictions, mimicking how humans perceive and interpret the world through various senses.
For instance, a human understands a conversation not just by the words spoken (text/audio) but also by facial expressions (image), body language (video), and the surrounding environment. Similarly, multi-modal AI aims to process and connect these diverse cues to gain a more comprehensive understanding.
Types of Multi-Modal Data Annotation
Data annotation techniques vary significantly depending on the modality and the specific AI task. Here’s a breakdown of common annotation types across text, image, and video:
1. Text Annotation

Text annotation involves labeling textual data to extract meaning, identify entities, or classify sentiment. This is foundational for Natural Language Processing (NLP) tasks.
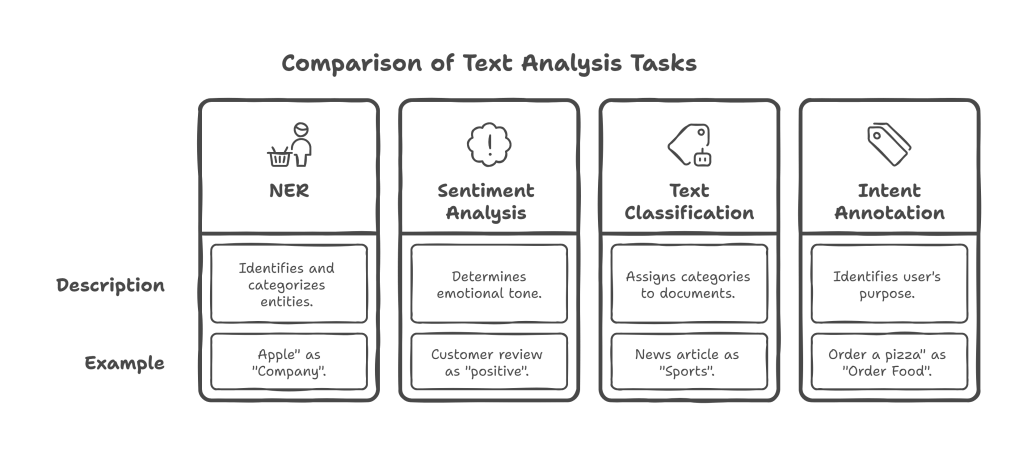
- Named Entity Recognition (NER): Identifying and categorizing key information (entities) in text, such as names of persons, organizations, locations, dates, or products.
- Example: Labeling “Apple” as a “Company” in the sentence “Apple released a new iPhone.”
- Sentiment Analysis: Determining the emotional tone or sentiment (positive, negative, neutral) expressed within a piece of text.
- Example: Labeling a customer review as “positive” or “negative.”
- Text Classification: Assigning predefined categories or tags to entire text documents based on their content.
- Example: Classifying news articles into “Sports,” “Politics,” or “Technology.”
- Linguistic Annotation: Focusing on grammatical structures, syntax, semantic roles, and relationships between words to help AI understand the nuances of language.
- Intent Annotation: Identifying the purpose or intention behind a user’s query or statement, crucial for chatbots and virtual assistants.
- Example: Labeling “Order a pizza” as an “Order Food” intent.
2. Image Annotation

Image annotation involves drawing specific labels on images to make them understandable for computer vision models.
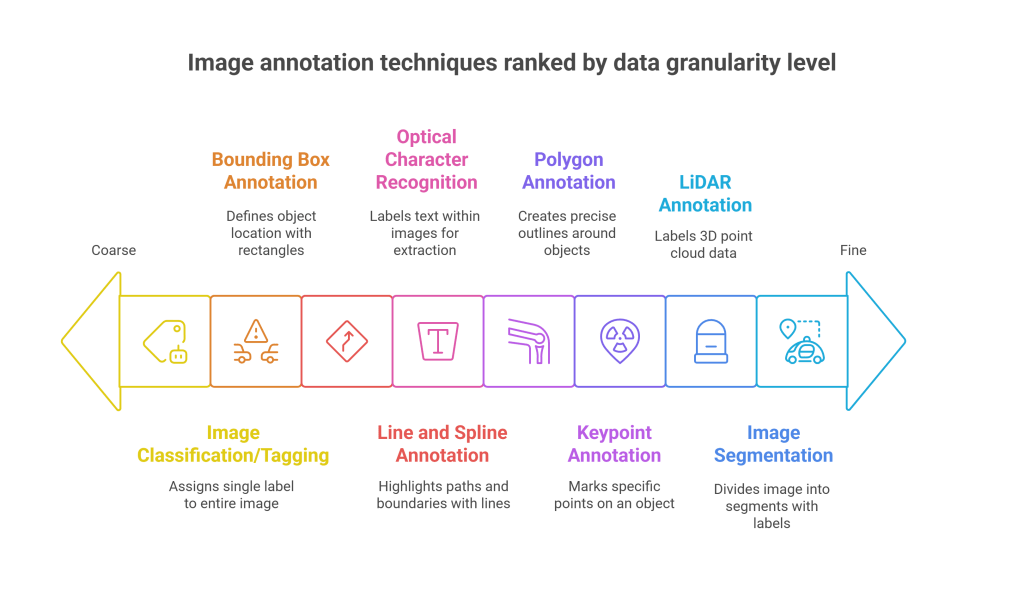
- Bounding Box Annotation: Drawing rectangular boxes around objects to define their location and size within an image.
- Use Cases: Object detection in autonomous vehicles (identifying cars, pedestrians, traffic signs), e-commerce product recognition.
- Polygon Annotation: Creating precise, irregular outlines around objects that are not rectangular, providing more accurate boundaries.
- Use Cases: Semantic segmentation, agricultural mapping (crop health), medical imaging (tumor identification).
- Image Segmentation: Dividing an image into multiple segments or individual pixels, each associated with a specific object or class.
- Semantic Segmentation: Assigning a class label to every pixel (e.g., all pixels belonging to “road” are labeled as such).
- Instance Segmentation: Differentiating between individual instances of the same class (e.g., distinguishing between “Car 1” and “Car 2” even if they are the same type of vehicle).
- Keypoint Annotation: Marking specific points on an object, often used for pose estimation or tracking anatomical landmarks.
- Use Cases: Human pose estimation in sports analytics, facial recognition (marking eyes, nose, mouth).
- Line and Spline Annotation: Drawing lines or curves to highlight paths, lanes, or boundaries.
- Use Cases: Lane detection in self-driving cars, road mapping.
- LiDAR Annotation (Point Cloud): Labeling 3D point cloud data generated by LiDAR sensors, identifying objects, distances, and surfaces in a 3D space.
- Use Cases: Autonomous driving for precise environmental understanding and obstacle detection.
- Image Classification/Tagging: Assigning a single label or tag to an entire image based on its overall content.
- Use Cases: Categorizing images in large datasets (e.g., “outdoor scene,” “animal”).
- Optical Character Recognition (OCR) Annotation: Labeling text within images, often by drawing bounding boxes around each character or word, to enable machines to read and extract text from documents or signs.
3. Video Annotation
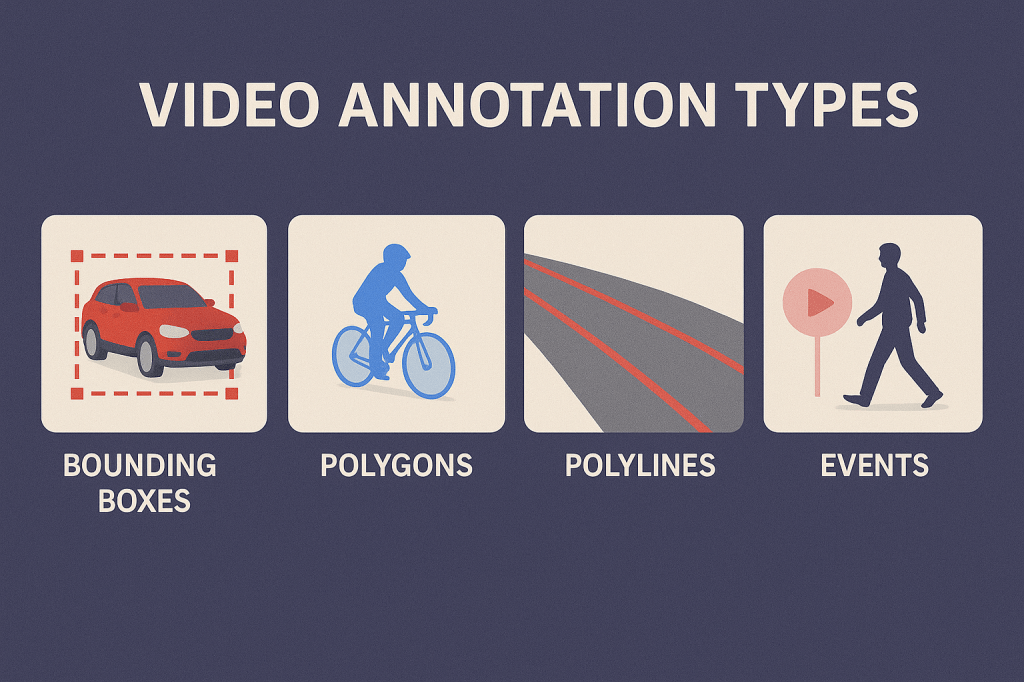
Video annotation extends image annotation by adding a temporal dimension, allowing AI to analyze motion, actions, and dynamic environments over time.

- Object Tracking: Labeling and tracking the movement of specific objects across multiple frames in a video.
- Use Cases: Surveillance systems (tracking suspicious activity), sports analytics (player movement).
- Action Labeling: Tagging specific actions or behaviors performed by objects or individuals within video frames.
- Example: Labeling “running,” “jumping,” “waving.”
- Scene Segmentation: Marking transitions between different scenes or environments within a video.
- Pose Estimation (Video): Tracking the joint positions of individuals across video frames to understand body movements.
- Event Detection: Identifying and marking specific events as they occur in a video stream.
- Spatio-temporal Annotation: Combining spatial (where an object is) and temporal (when an action occurs) information to provide a comprehensive understanding of dynamic scenes.
Uses of Multi-Modal Data Annotation
The integration of multiple data modalities through annotation opens up new frontiers for AI applications across various industries:
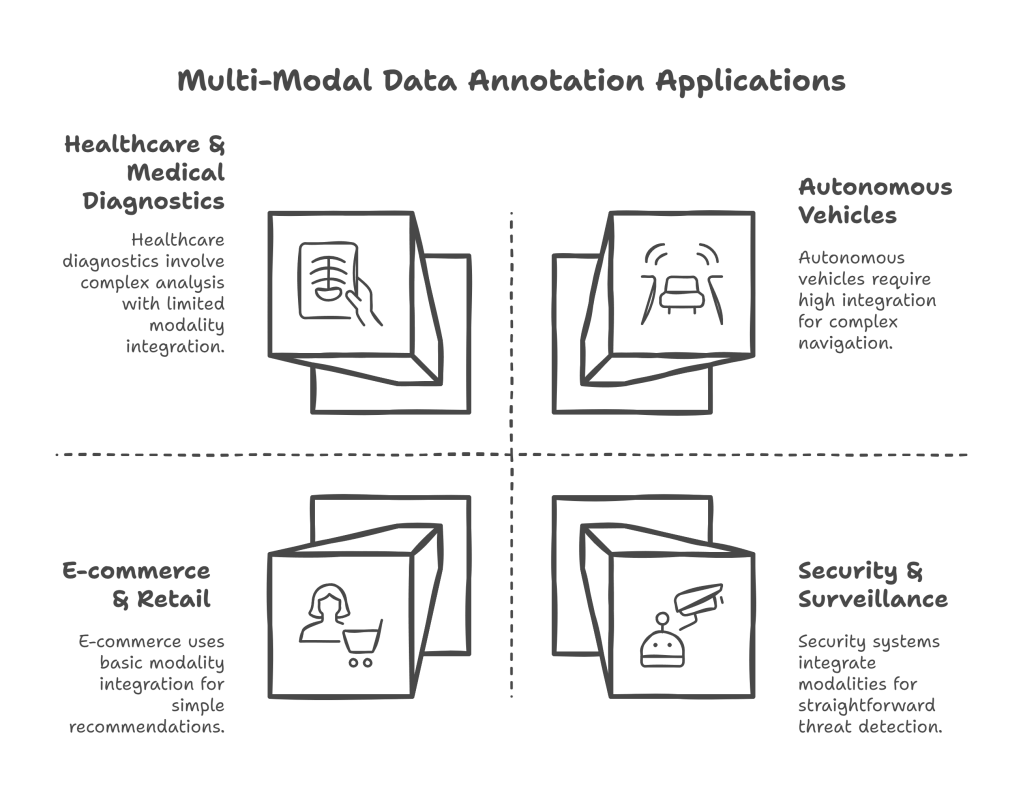
- Autonomous Vehicles: Combining visual data (cameras), depth data (LiDAR), radar, and GPS information to enable precise object detection (pedestrians, vehicles, traffic signs), lane keeping, and complex navigation in dynamic environments.
- Healthcare & Medical Diagnostics: Analyzing patient records (text), medical images (X-rays, MRIs, CT scans), and even audio from consultations to assist in more accurate and faster diagnoses, personalized treatment recommendations, and anomaly detection.
- E-commerce & Retail: Enhancing product recommendations by combining product images with textual descriptions, customer reviews, and browsing history. It also powers virtual try-on experiences and visual search functionalities.
- Security & Surveillance: Integrating facial recognition (image), voice authentication (audio), and behavioral analysis from video footage to detect anomalies, identify threats, and prevent fraud.
- Robotics & Industrial Automation: Enabling robots to understand their environment and perform complex tasks by fusing data from cameras, depth sensors, and tactile feedback.
- Content Recommendations: Providing more relevant content suggestions by analyzing viewing history, user interactions, textual descriptions, and visual/audio features of content.
- Social Media Analytics: Deepening sentiment analysis and trend prediction by analyzing not just text posts but also accompanying images, videos, and emojis.
- Education: Creating personalized learning experiences by analyzing text-based materials, video lessons, audio discussions, and tracking student engagement through facial expressions.
- Finance: Improving fraud detection and risk assessment by cross-referencing transaction records, textual communication, and voice interactions to spot unusual patterns.
- Augmented Reality (AR) & Virtual Reality (VR): Creating immersive and interactive experiences by accurately annotating real-world objects and environments for digital overlays and spatial understanding.
Risks of Not Annotating Properly
The quality of AI models is directly proportional to the quality of their training data. Poorly annotated multi-modal data can lead to severe consequences, undermining the effectiveness and reliability of AI systems.
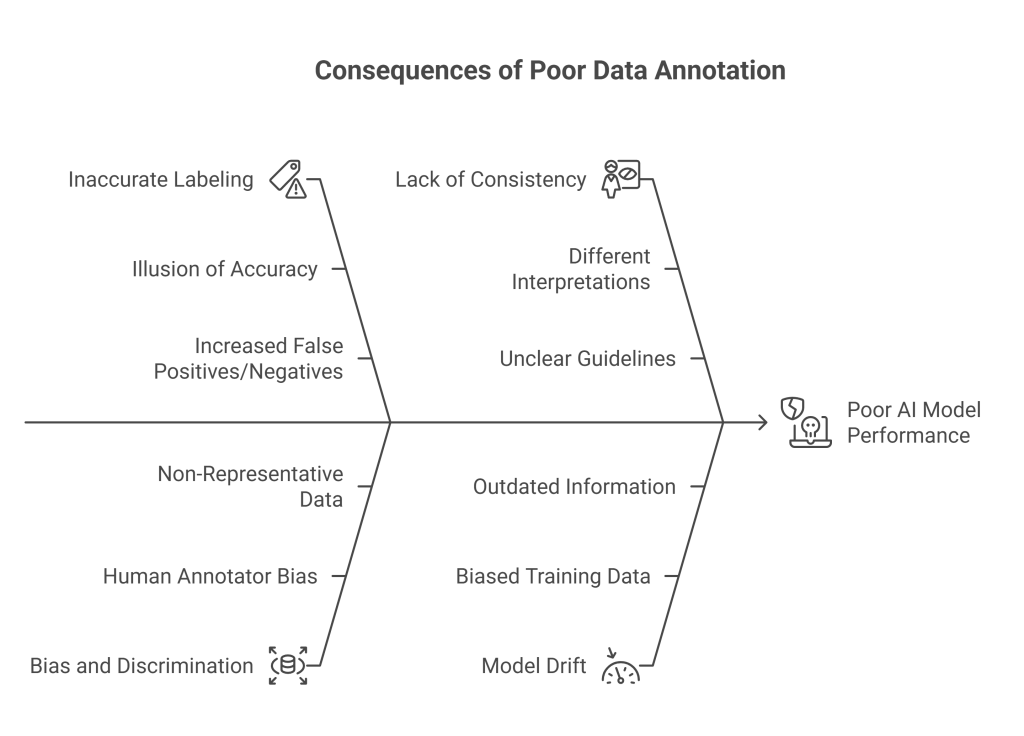
- Illusion of Accuracy: Incorrectly labeled, inconsistently tagged, or contextually inaccurate data can lead AI models to learn the wrong patterns. The model might appear functional initially, producing seemingly reasonable outputs, but will fail dramatically in real-world scenarios. This can be particularly dangerous in critical applications like healthcare or finance, where flawed decisions can have serious repercussions.
- Model Losing Accuracy Over Time (Model Drift): If the training data is biased, incomplete, or outdated, the model’s predictions can drift, leading to a gradual decline in performance without immediate detection. This necessitates costly and time-consuming re-annotation and retraining.
- Costly AI Rework and Delays: Fixing a poorly performing AI model post-deployment is significantly more expensive than getting the annotation right from the start. It involves extensive data cleaning, re-labeling, retraining algorithms, and re-deployment, leading to substantial time, effort, and financial waste.
- Increased False Positives or Negatives: Inaccurate labeling directly results in AI systems making incorrect classifications.
- False Positives: The model flags something harmless as a problem (e.g., a legitimate transaction as fraudulent).
- False Negatives: The model misses a real issue (e.g., failing to detect a cancerous tumor).These errors erode trust in the system and can have disastrous consequences depending on the application (e.g., cybersecurity, medical diagnostics).
- Bias and Discrimination: If the annotation process is influenced by the biases of human annotators or if the data used for labeling is not representative of the target population, the resulting AI models will inherit and perpetuate these biases. This can lead to unfair or discriminatory outcomes, especially in sensitive areas like loan approvals, hiring, or law enforcement.
- Lack of Consistency: Different annotators may interpret guidelines differently, leading to inconsistencies in labeling. This lack of uniformity makes it difficult for the AI model to learn robust patterns, leading to unpredictable and unreliable performance. Establishing clear guidelines and rigorous quality control measures (e.g., multi-expert annotation, consensus labeling) is crucial to mitigate this.
- Reduced Model Performance: Ultimately, poorly annotated data leads to lower model accuracy, precision, recall, and overall effectiveness. The “garbage in, garbage out” principle holds true: if the input data is of poor quality, the model’s output will also be compromised.
- Reputation and Trust Concerns: If an AI system deployed with poorly annotated data makes significant errors or exhibits bias, it can severely damage the reputation of the deploying organization and erode user trust.
Conclusion
Multi-modal data annotation is an indispensable cornerstone for developing advanced AI systems that can truly understand and interact with the complex real world. By meticulously labeling and synchronizing diverse data types, we equip AI models with the contextual richness necessary to achieve human-like perception and decision-making capabilities. However, this process is not without its challenges. Ensuring high-quality, consistent, and unbiased annotation is paramount. Investing in clear annotation guidelines, robust quality control processes, and skilled annotators is critical to harness the full potential of multi-modal AI and avoid the pitfalls that can lead to costly failures, reduced performance, and damaged trust. As AI continues to evolve, the demand for sophisticated multi-modal data annotation will only grow, solidifying its role as a key enabler for future intelligent applications.
Discover more from SkillWisor
Subscribe to get the latest posts sent to your email.
