
Introduction
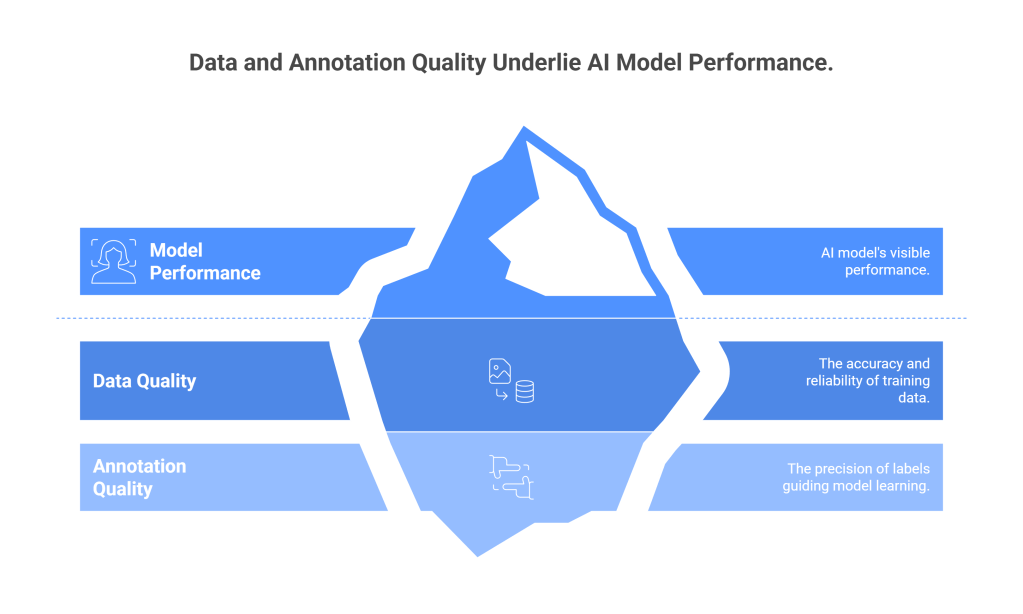
In the rapidly evolving landscape of artificial intelligence and machine learning, the pursuit of high-performing models has led organizations to focus intensively on algorithms, architectures, and computational resources. However, beneath the surface of these technical achievements lies a fundamental truth that often goes unrecognized: the quality of machine learning models is intrinsically linked to the quality of the data they consume and the annotations that guide their learning process. This relationship between data quality and annotation quality represents one of the most critical yet underexplored aspects of AI development.
The concept of “garbage in, garbage out” has never been more relevant than in today’s data-driven world. While organizations invest millions in cutting-edge hardware and sophisticated algorithms, many fail to recognize that their models’ performance ceiling is ultimately determined by the quality of their training data and the accuracy of their annotations. This hidden link between data quality and annotation quality creates a cascading effect that can either propel AI systems to unprecedented heights of performance or doom them to mediocrity regardless of their technical sophistication.
Understanding this relationship is crucial for anyone involved in AI development, from data scientists and machine learning engineers to project managers and executives making strategic decisions about AI initiatives. The challenges that arise from poor data quality and inadequate annotation practices are not merely technical hurdles—they represent fundamental barriers to achieving reliable, scalable, and trustworthy AI systems.
Understanding Data Quality: The Foundation of AI Success
Data quality encompasses multiple dimensions that collectively determine the reliability and usefulness of information for machine learning applications. At its core, data quality refers to the degree to which data meets the requirements for its intended use, but this simple definition masks a complex web of interconnected factors that influence AI model performance.

The accuracy dimension of data quality refers to how closely data values correspond to the true or correct values they represent. In the context of machine learning, inaccurate data can lead to models that learn incorrect patterns, resulting in poor predictions and unreliable outcomes. For instance, if a dataset used to train a medical diagnosis model contains incorrect diagnostic labels, the resulting model may perpetuate these errors at scale, potentially endangering patient safety.
Completeness represents another crucial aspect of data quality, referring to whether all required data elements are present and accounted for. Incomplete data can create blind spots in model training, leading to algorithms that perform well on available data but fail catastrophically when encountering scenarios not represented in the training set. This is particularly problematic in safety-critical applications where comprehensive coverage of potential scenarios is essential.
Consistency ensures that data values are uniform and free from contradictions across different sources, time periods, or data collection methods. Inconsistent data can confuse machine learning algorithms, leading to models that struggle to identify coherent patterns and make reliable predictions. The challenge of maintaining consistency becomes particularly acute when dealing with data collected from multiple sources or over extended periods.
Timeliness addresses whether data is current and relevant for the intended application. In rapidly changing environments, outdated data can render models obsolete before they even reach production. This temporal dimension of data quality is often overlooked but can be critical for applications in dynamic domains such as financial markets or social media analysis.
The validity dimension ensures that data conforms to defined formats, ranges, and business rules. Invalid data can cause model training to fail or produce models that behave unpredictably when encountering similar invalid inputs in production. This aspect of data quality is particularly important for ensuring robust model deployment and operation.
Annotation Quality: The Art and Science of Labeling
Annotation quality represents the precision, accuracy, and consistency with which human experts or automated systems assign labels, tags, or other metadata to raw data. This process serves as the bridge between unstructured information and the structured learning objectives of machine learning models. The quality of annotations directly influences a model’s ability to learn meaningful patterns and make accurate predictions.

The subjective nature of many annotation tasks introduces inherent challenges to maintaining high annotation quality. Unlike objective measurements that can be verified against physical standards, many annotation tasks require human judgment, interpretation, and domain expertise. This subjectivity can lead to inconsistencies between different annotators, temporal variations in the same annotator’s work, and systematic biases that reflect the annotator’s background and perspective.
Inter-annotator agreement represents a fundamental metric for assessing annotation quality. When multiple annotators label the same data, the degree of agreement between their annotations provides insight into the clarity of annotation guidelines, the difficulty of the task, and the overall reliability of the labeling process. Low inter-annotator agreement often indicates ambiguous guidelines, insufficient training, or inherently subjective tasks that may require additional structure or revised approaches.
The expertise and training of annotators significantly impact annotation quality. Domain-specific knowledge is often crucial for accurate labeling, particularly in specialized fields such as medical imaging, legal document analysis, or technical literature review. However, even expert annotators require comprehensive training on specific annotation guidelines, tools, and quality standards to ensure consistent and accurate work.
Annotation guidelines serve as the foundation for maintaining quality and consistency across the annotation process. Well-crafted guidelines provide clear definitions, examples, edge cases, and decision trees that help annotators navigate complex or ambiguous situations. However, developing comprehensive guidelines requires deep understanding of both the domain and the intended use of the annotated data, and guidelines must evolve as new challenges and edge cases emerge during the annotation process.
The scalability of annotation processes presents additional challenges to maintaining quality. As annotation requirements grow, organizations often face pressure to increase throughput, which can compromise quality if not managed carefully. Balancing speed and accuracy requires sophisticated quality control mechanisms, efficient annotation tools, and well-designed workflows that support both productivity and precision.
The Symbiotic Relationship: How Data and Annotation Quality Interact
The relationship between data quality and annotation quality is not merely additive—it is fundamentally symbiotic. Poor data quality can undermine even the most careful annotation efforts, while high-quality data can be rendered useless by inadequate annotation practices. Understanding this interaction is crucial for developing effective strategies to improve both dimensions simultaneously.
When data quality is poor, annotators face increased difficulty in making accurate judgments. Blurry images, incomplete text, corrupted files, or inconsistent formatting can make it challenging or impossible for annotators to provide reliable labels. This creates a situation where even skilled annotators working with excellent guidelines may produce inconsistent or inaccurate annotations simply because the underlying data does not support reliable judgment.
Conversely, high-quality data can amplify the impact of annotation quality issues. When data is clear, complete, and well-structured, differences in annotation quality become more pronounced and have greater impact on model performance. This means that investments in data quality are most valuable when accompanied by corresponding investments in annotation quality, and vice versa.
The feedback loop between data and annotation quality creates opportunities for continuous improvement. High-quality annotations can help identify data quality issues by revealing patterns in annotator uncertainty, disagreement, or error rates. Similarly, improving data quality can enhance annotation quality by making labeling tasks clearer and more consistent.
This symbiotic relationship also extends to the temporal dimension. As models trained on annotated data are deployed and generate new data, the quality of this new data depends partially on the quality of the original annotations. This creates a compounding effect where quality improvements (or degradations) in early stages of the data lifecycle can have magnified impacts on long-term system performance.
Common Challenges in Data Quality Management
Organizations face numerous challenges in maintaining high data quality throughout the machine learning pipeline. These challenges often compound each other, creating complex webs of quality issues that can be difficult to diagnose and resolve.
Data collection represents the first point where quality issues can emerge. Inconsistent collection methods, varying environmental conditions, equipment malfunctions, and human errors during data gathering can introduce systematic biases and quality problems that propagate throughout the entire pipeline. The distributed nature of modern data collection, often involving multiple teams, locations, and time periods, exacerbates these challenges.
Data integration poses another significant challenge, particularly when combining data from multiple sources with different formats, standards, and quality levels. The process of merging disparate datasets can introduce inconsistencies, duplications, and conflicts that compromise overall data quality. Organizations often underestimate the complexity of this integration process and the potential for quality degradation during data consolidation.
The sheer volume and velocity of modern data streams create challenges for traditional quality assurance approaches. Manual inspection and validation methods that might be feasible for smaller datasets become impractical when dealing with millions or billions of data points. This scale challenge requires automated quality monitoring systems, but these systems themselves can introduce new sources of error and may miss subtle quality issues that human reviewers would catch.
Data drift represents a temporal challenge where the statistical properties of data change over time, gradually degrading the quality and relevance of historical datasets. This phenomenon is particularly problematic in dynamic domains where underlying patterns shift due to changing user behavior, market conditions, or environmental factors. Detecting and adapting to data drift requires sophisticated monitoring systems and flexible data management strategies.
Privacy and security requirements add additional complexity to data quality management. Techniques such as data anonymization, differential privacy, and secure multi-party computation can introduce noise or artifacts that impact data quality. Balancing privacy protection with data utility requires careful consideration of the trade-offs between quality and confidentiality.
Annotation Quality Pitfalls and Solutions
The annotation process is fraught with potential pitfalls that can compromise quality despite best intentions and significant investments. Understanding these common failure modes is essential for developing robust annotation strategies.
Annotator fatigue represents one of the most pervasive challenges in maintaining annotation quality. As annotators work through large volumes of data, their attention and accuracy naturally decline, leading to increased error rates and reduced consistency. This fatigue effect is particularly pronounced in repetitive tasks or when dealing with complex, cognitively demanding annotation requirements.
Ambiguous or incomplete annotation guidelines create another major source of quality issues. When guidelines fail to address edge cases, provide clear decision criteria, or offer sufficient examples, annotators must make subjective judgments that may not align with project objectives or other annotators’ interpretations. This ambiguity can lead to systematic inconsistencies that undermine model training.
The annotation quality degradation that occurs when scaling up annotation efforts represents a significant challenge for growing AI projects. As organizations move from pilot projects with small, carefully managed annotation teams to large-scale operations involving dozens or hundreds of annotators, maintaining quality becomes increasingly difficult. The personal attention and intensive training possible with small teams becomes impractical at scale.
Bias in annotation represents a subtle but critical quality issue that can have far-reaching consequences. Annotators bring their own perspectives, experiences, and unconscious biases to the annotation process, which can systematically skew annotations in ways that reflect these biases rather than objective ground truth. This is particularly problematic in sensitive applications such as hiring, criminal justice, or healthcare where biased annotations can perpetuate or amplify existing societal inequalities.
Quality control mechanisms provide essential safeguards against these pitfalls, but implementing effective quality control requires careful planning and ongoing attention. Multiple annotation approaches, where each data point is labeled by several annotators, can help identify and resolve disagreements, but this increases costs and complexity. Automated quality checks can flag potential issues, but these systems require careful calibration to avoid false positives or negatives.
The Cost of Poor Quality: Real-World Consequences
The consequences of poor data and annotation quality extend far beyond technical performance metrics, impacting business outcomes, user experiences, and societal well-being in profound ways. Understanding these costs is crucial for making informed decisions about quality investments and priorities.

Model performance degradation represents the most immediate and measurable consequence of quality issues. Poor quality data and annotations lead to models that achieve lower accuracy, precision, and recall on test datasets, but these performance metrics often fail to capture the full extent of quality-related problems. Models trained on low-quality data may appear to perform well on similarly low-quality test data while failing catastrophically when deployed in real-world environments with different quality characteristics.
The financial impact of quality issues can be substantial, encompassing both direct costs and opportunity costs. Direct costs include the expenses associated with collecting additional data, re-annotating existing datasets, retraining models, and addressing quality-related failures in production systems. Opportunity costs represent the value lost when poor quality prevents organizations from achieving their AI objectives or delays time-to-market for AI-enabled products and services.
User trust and satisfaction suffer when AI systems produce unreliable or biased results due to quality issues. In consumer-facing applications, poor quality can lead to user frustration, negative reviews, and customer churn. In business-to-business contexts, quality issues can damage professional relationships and undermine confidence in AI solutions.
Regulatory and compliance risks associated with quality issues are becoming increasingly important as governments and industry bodies develop standards for AI systems. Poor quality data and annotations can lead to discriminatory outcomes, privacy violations, and other compliance failures that result in legal penalties, regulatory sanctions, and reputational damage.
The cascading effects of quality issues can amplify their impact over time. Poor quality in training data can lead to models that generate poor quality synthetic data, creating a downward spiral of degrading quality. Similarly, annotation errors can propagate through model generations, becoming increasingly difficult to identify and correct as they become embedded in system behavior.
Strategies for Improving Data Quality
Developing effective strategies for improving data quality requires a holistic approach that addresses quality throughout the entire data lifecycle. These strategies must be tailored to specific organizational contexts, technical requirements, and resource constraints while maintaining focus on long-term sustainability and scalability.
Proactive data quality management begins with establishing clear quality standards and metrics that align with business objectives and technical requirements. These standards should be specific, measurable, and relevant to the intended use of the data. Regular monitoring and measurement against these standards enables early detection of quality issues and provides a foundation for continuous improvement efforts.
Automated quality assessment tools can provide scalable solutions for monitoring data quality across large datasets. These tools can detect outliers, identify missing values, flag inconsistencies, and perform statistical checks that would be impractical to conduct manually. However, automated tools must be carefully configured and regularly updated to remain effective as data characteristics evolve.
Data lineage and provenance tracking provide crucial context for understanding and improving data quality. By maintaining detailed records of data sources, transformations, and processing steps, organizations can identify the root causes of quality issues and develop targeted interventions. This traceability also enables impact assessment when quality issues are discovered, helping prioritize remediation efforts.
Collaborative approaches to data quality improvement involve stakeholders from across the organization, including data producers, consumers, and governance teams. These collaborative efforts can identify quality requirements that might be overlooked by individual teams and ensure that quality improvements align with broader organizational objectives.
Investment in data infrastructure and tooling can provide long-term benefits for quality management. Modern data platforms offer sophisticated quality monitoring, automated validation, and self-healing capabilities that can prevent quality issues from propagating through data pipelines. However, these technological solutions must be complemented by appropriate processes and governance structures to be effective.
Best Practices for Annotation Quality
Achieving high annotation quality requires a comprehensive approach that addresses people, processes, and technology. The most effective annotation quality strategies recognize that annotation is both a technical and human endeavor that requires careful attention to cognitive, social, and organizational factors.
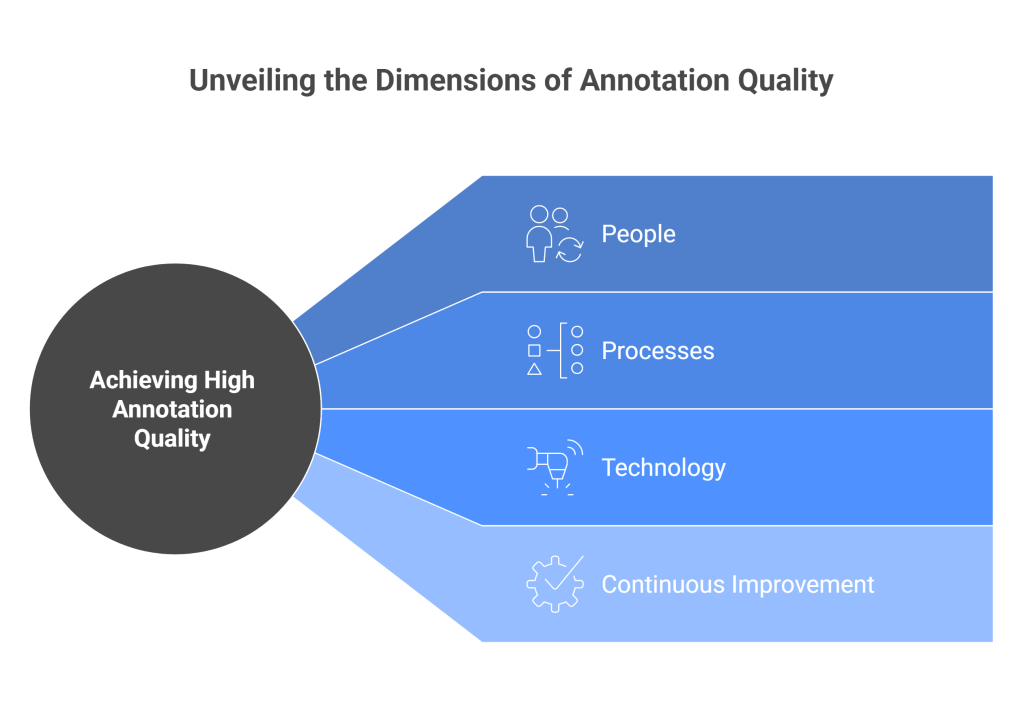
Comprehensive annotator training programs provide the foundation for quality annotation work. These programs should cover not only technical aspects of annotation tools and guidelines but also the broader context of the annotation task, including how annotations will be used, why quality matters, and how individual contributions fit into larger objectives. Ongoing training and refresher sessions help maintain quality as guidelines evolve and new challenges emerge.
Clear, comprehensive, and regularly updated annotation guidelines serve as the primary reference for maintaining consistency and accuracy. Effective guidelines include detailed definitions, numerous examples, decision trees for complex cases, and explicit instructions for handling edge cases and ambiguous situations. Guidelines should be developed collaboratively with input from domain experts, annotators, and model developers to ensure they address real-world needs and challenges.
Multi-tiered quality control processes provide multiple opportunities to identify and correct quality issues. These processes might include initial training and certification for annotators, regular quality audits, peer review mechanisms, and expert validation of complex or controversial annotations. The specific structure of quality control processes should be tailored to the complexity of the annotation task and the criticality of the application.
Technology solutions can enhance annotation quality through improved tools, automated quality checks, and intelligent task assignment. Modern annotation platforms offer features such as real-time quality feedback, automated consistency checking, and adaptive task routing that can improve both efficiency and quality. However, technology solutions must be carefully integrated with human processes to avoid creating new sources of error or frustration.
Continuous improvement methodologies provide frameworks for systematically enhancing annotation quality over time. These methodologies involve regular assessment of quality metrics, identification of improvement opportunities, implementation of targeted interventions, and measurement of results. Successful continuous improvement requires commitment from leadership, engagement from annotators, and willingness to adapt processes based on evidence and feedback.
Technology Solutions and Tools
The landscape of technology solutions for data and annotation quality management has evolved rapidly, offering organizations increasingly sophisticated options for automating quality assessment, monitoring, and improvement. These technological advances provide opportunities to scale quality management efforts while reducing costs and improving consistency.
Automated data quality monitoring platforms provide real-time visibility into data quality metrics across large-scale data pipelines. These platforms can detect anomalies, track quality trends, and alert stakeholders to potential issues before they impact downstream processes. Advanced platforms incorporate machine learning algorithms that can learn normal patterns in data quality metrics and identify subtle deviations that might indicate emerging problems.
Annotation management platforms have evolved to include sophisticated quality control features such as automated consistency checking, intelligent task assignment, and real-time performance feedback. These platforms can track annotator performance over time, identify patterns in annotation errors, and provide personalized training recommendations to improve individual and team performance.
Machine learning approaches to quality assessment represent an emerging area of innovation where AI systems are used to evaluate and improve the quality of data and annotations used to train other AI systems. These approaches can provide scalable solutions for quality assessment while reducing the burden on human reviewers.
Data lineage and governance platforms provide comprehensive tracking of data quality throughout complex data pipelines. These platforms enable organizations to understand the sources of quality issues, assess the impact of quality problems, and implement targeted improvements. Advanced platforms integrate with existing data infrastructure to provide seamless quality monitoring without disrupting operational workflows.
Cloud-based quality solutions offer scalable, cost-effective options for organizations that lack the resources to develop and maintain quality management infrastructure in-house. These solutions provide access to sophisticated quality management capabilities without requiring significant upfront investments in technology or expertise.
Measuring Success: Metrics and KPIs
Developing effective metrics and key performance indicators (KPIs) for data and annotation quality requires careful consideration of what aspects of quality are most important for specific applications and how these can be measured reliably and consistently. The most successful quality measurement programs balance comprehensiveness with practicality, ensuring that metrics provide actionable insights without creating excessive measurement overhead.
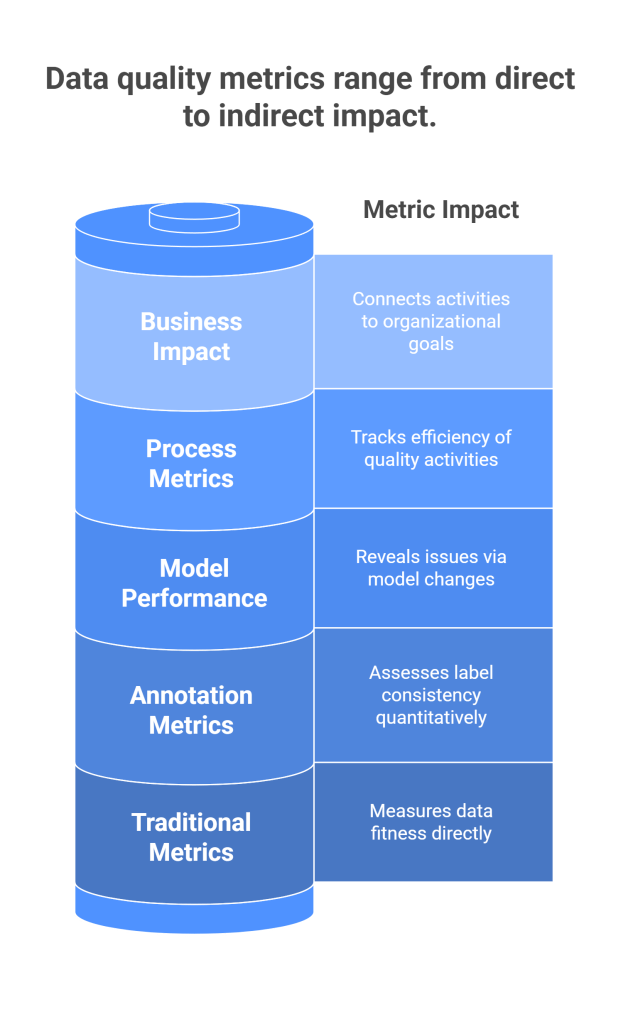
Traditional data quality metrics such as completeness, accuracy, consistency, and timeliness provide fundamental measures of data fitness for use. However, these metrics must be adapted to the specific context of machine learning applications, where the relationship between data characteristics and model performance may be complex and non-linear.
Annotation quality metrics focus on the reliability and accuracy of human-generated labels and annotations. Inter-annotator agreement measures such as Cohen’s kappa, Fleiss’ kappa, and intraclass correlation coefficients provide quantitative assessments of annotation consistency. However, these metrics must be interpreted carefully, as high agreement does not necessarily indicate high accuracy, and low agreement may reflect task difficulty rather than poor quality.
Model performance metrics provide indirect but important measures of data and annotation quality. Changes in model accuracy, precision, recall, and other performance indicators can reveal quality issues that might not be apparent from direct data assessment. However, model performance is influenced by many factors beyond data quality, so these metrics must be interpreted in context.
Process metrics track the efficiency and effectiveness of quality management activities themselves. These metrics might include the time required for quality assessment, the cost of quality control activities, the rate of quality issue detection and resolution, and the impact of quality improvement initiatives on overall system performance.
Business impact metrics connect quality management activities to organizational objectives and outcomes. These metrics might include customer satisfaction scores, revenue impact of quality issues, time-to-market for AI initiatives, and compliance with regulatory requirements. While these metrics may be influenced by many factors beyond data quality, they provide important context for prioritizing quality investments.
Building a Quality-Centric Culture
Creating a culture that prioritizes data and annotation quality requires sustained effort and commitment from leadership, but the benefits extend far beyond technical improvements to encompass organizational effectiveness, employee satisfaction, and long-term competitiveness. A quality-centric culture recognizes that quality is everyone’s responsibility and that small improvements in quality can have significant cumulative effects on organizational success.
Leadership commitment provides the foundation for building quality-centric cultures. When leaders consistently prioritize quality, allocate resources for quality initiatives, and recognize quality achievements, they signal to the organization that quality matters. This commitment must be demonstrated through actions, not just words, and must persist even when facing pressure to deliver quickly or reduce costs.
Training and education programs help build quality awareness and skills throughout the organization. These programs should address not only technical aspects of quality management but also the business rationale for quality investments and the role that each individual plays in maintaining quality. Effective training programs are tailored to different roles and responsibilities within the organization.
Quality advocacy and communication efforts help maintain focus on quality objectives and share success stories that demonstrate the value of quality investments. Regular communication about quality metrics, improvement initiatives, and lessons learned helps reinforce the importance of quality and provides opportunities for cross-functional learning and collaboration.
Recognition and incentive systems that reward quality contributions help align individual behaviors with organizational quality objectives. These systems should recognize both individual achievements and team efforts, and should balance quality recognition with other performance metrics to avoid creating perverse incentives.
Continuous learning and improvement mechanisms provide structured approaches for identifying quality improvement opportunities and implementing changes. These mechanisms might include regular quality reviews, post-project retrospectives, cross-functional quality teams, and systematic analysis of quality metrics and trends.
Future Directions and Emerging Trends
The field of data and annotation quality management continues to evolve rapidly, driven by advances in artificial intelligence, changing regulatory requirements, and growing recognition of quality’s importance for AI success. Understanding emerging trends and future directions can help organizations prepare for coming challenges and opportunities.
Artificial intelligence and machine learning are increasingly being applied to quality management itself, creating opportunities for more sophisticated, automated, and scalable quality solutions. These AI-powered quality tools can learn from historical quality patterns, predict potential quality issues, and recommend targeted interventions. However, the use of AI for quality management also raises new questions about the quality of AI systems used to assess quality.
Regulatory developments around AI governance and algorithmic accountability are creating new requirements for data and annotation quality documentation, monitoring, and reporting. Organizations must prepare for increasing scrutiny of their quality management practices and may need to implement more rigorous quality assurance processes to meet regulatory requirements.
The growing importance of explainable AI is creating new quality requirements focused on the interpretability and transparency of data and annotations. Quality management practices must evolve to address not only accuracy and consistency but also the ability to explain and justify quality assessments and decisions.
Federated learning and privacy-preserving AI techniques are creating new challenges for quality management, as traditional quality assessment approaches may not be applicable when data cannot be directly accessed or shared. New approaches to quality assessment and improvement that respect privacy constraints while maintaining quality standards are needed.
The democratization of AI and the growth of citizen data science are expanding the population of people involved in data and annotation quality management. This trend creates opportunities for distributed quality improvement but also challenges related to training, coordination, and consistency across diverse stakeholder groups.
Conclusion
The relationship between data quality and annotation quality represents one of the most critical yet underappreciated aspects of successful AI development. This hidden link creates a multiplicative effect where improvements in one area amplify the benefits of improvements in the other, while neglecting either dimension can undermine even the most sophisticated AI initiatives.
Organizations that recognize and address this relationship systematically position themselves for greater AI success, while those that focus exclusively on algorithms and infrastructure may find themselves limited by fundamental quality constraints. The challenges of managing data and annotation quality are significant, but the tools, techniques, and best practices for addressing these challenges continue to evolve and improve.
The future of AI depends not just on algorithmic advances and computational power, but on our ability to ensure that the data and annotations that fuel AI systems meet the highest standards of quality, reliability, and trustworthiness. By investing in quality management, organizations invest in the foundation of AI success and create sustainable competitive advantages in an increasingly AI-driven world.
The journey toward high-quality data and annotations is ongoing, requiring continuous attention, investment, and adaptation. However, organizations that commit to this journey and build quality-centric cultures will find themselves better positioned to realize the full potential of artificial intelligence while avoiding the pitfalls that can undermine AI initiatives. The hidden link between data quality and annotation quality, once understood and addressed, becomes a powerful driver of AI success and organizational transformation.
Discover more from SkillWisor
Subscribe to get the latest posts sent to your email.
