
Introduction
In the rapidly evolving landscape of natural language processing (NLP) and machine learning, annotation serves as the foundation upon which intelligent systems are built. The process of labeling data to train models has become increasingly sophisticated, yet it remains fraught with challenges that can significantly impact the performance and reliability of AI systems. Among these challenges, the annotation of nested entities presents one of the most complex and persistent problems facing data scientists, linguists, and machine learning engineers today.
Nested entities, such as “CEO of Apple” where both a title (CEO) and an organization (Apple) exist within a single phrase, represent a fundamental challenge in how we structure and understand language computationally. This article explores the multifaceted nature of annotation challenges, with particular emphasis on nested entities, while examining the broader implications for NLP applications, annotation methodologies, and the future of automated text processing.
Understanding Nested Entities
Definition and Scope
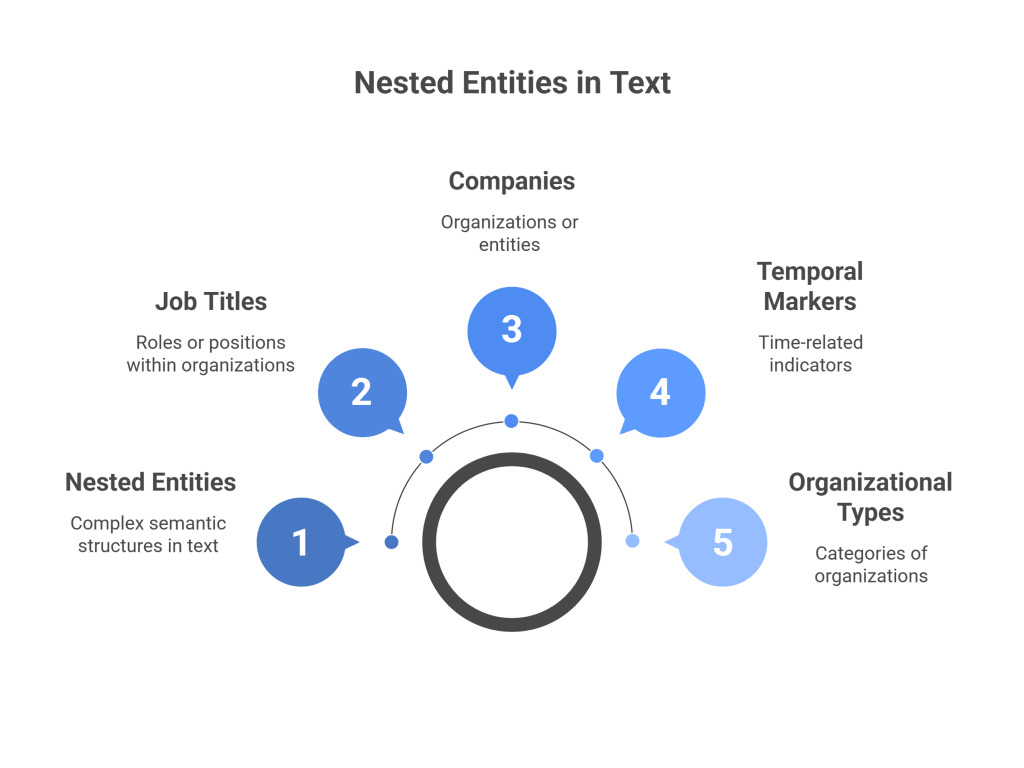
Nested entities occur when multiple distinct semantic units overlap or are contained within one another in natural language text. Unlike simple, non-overlapping entities that can be easily tagged in isolation, nested entities require annotators to recognize and mark multiple layers of meaning simultaneously. The example “CEO of Apple” illustrates this complexity: “CEO” represents a job title or position, while “Apple” denotes a company, and the entire phrase “CEO of Apple” might be considered a complete job description or professional role.
This nesting phenomenon extends far beyond simple title-company combinations. Consider the phrase “the former Microsoft engineer turned startup founder.” Here, we have temporal markers (“former”), company names (“Microsoft”), job titles (“engineer,” “founder”), and organizational types (“startup”) all interweaving to create a complex semantic structure that defies simple linear annotation.
Types of Nested Entities
The complexity of nested entities manifests in several distinct patterns. Hierarchical nesting occurs when entities exist at different levels of granularity, such as “New York City Mayor” where “New York City” is a location and “Mayor” is a political position, but together they form a specific governmental role. Overlapping entities present another challenge, as seen in “Apple iPhone sales” where “Apple” is a company, “iPhone” is a product, and “Apple iPhone” together represents a specific product line.
Sequential nesting adds another layer of complexity, particularly in longer phrases like “former Google AI researcher at Stanford University,” where temporal, organizational, professional, and institutional entities cascade through the text. Each word or phrase may belong to multiple entity categories simultaneously, requiring annotation systems to capture these multiple memberships without losing semantic precision.
The Annotation Challenge Landscape
Traditional Annotation Limitations
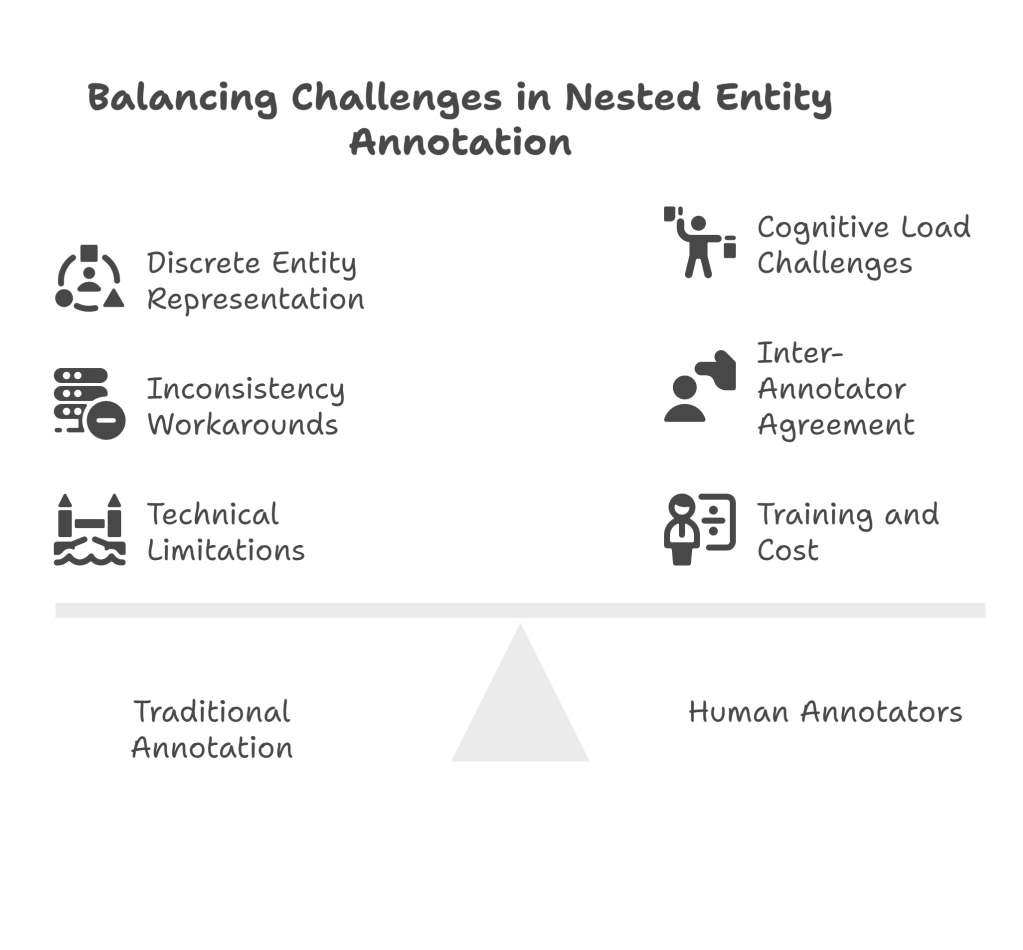
Conventional annotation approaches, particularly those based on the BIO (Begin-Inside-Outside) tagging scheme, struggle significantly with nested entities. The BIO format assumes that entities are discrete, non-overlapping segments of text, making it impossible to represent situations where a single token belongs to multiple entities simultaneously. This limitation has forced many annotation projects to either ignore nested structures or develop complex workarounds that often introduce inconsistencies and reduce annotation quality.
The challenge extends beyond technical limitations to fundamental questions about how we categorize and understand language. When annotating “CEO of Apple,” should annotators mark it as a single entity representing a job title, two separate entities, or multiple overlapping entities? The answer depends on the intended use case, the annotation schema, and the theoretical framework underlying the annotation project.
Human Annotator Challenges
Human annotators face unique difficulties when working with nested entities. The cognitive load of simultaneously tracking multiple entity types and their relationships can lead to annotation fatigue and increased error rates. Annotators must maintain awareness of overlapping categories while ensuring consistency across similar examples throughout large datasets.
Inter-annotator agreement, already challenging in standard annotation tasks, becomes particularly problematic with nested entities. Different annotators may have varying intuitions about where entity boundaries should be drawn and which entities should be prioritized when conflicts arise. This subjectivity can result in datasets with inconsistent labeling patterns that undermine model training effectiveness.
Training annotators to handle nested entities requires extensive guidelines and ongoing quality control measures. The complexity of decision-making processes involved in nested entity annotation often necessitates domain expertise, making the annotation process more expensive and time-consuming than traditional approaches.
Technical Approaches to Nested Entity Annotation
Advanced Tagging Schemes
Researchers have developed several sophisticated tagging schemes to address nested entity challenges. The BILOU (Begin-Inside-Last-Outside-Unit) scheme provides more granular control over entity boundaries, while nested BIO approaches attempt to encode multiple entity layers within single tags. However, these solutions often introduce their own complexities and may not scale well to deeply nested structures.
Graph-based annotation schemes represent another promising direction, where entities and their relationships are modeled as nodes and edges in a semantic network. This approach allows for more flexible representation of nested structures but requires specialized tools and significantly more complex annotation interfaces.
Machine Learning Adaptations
Modern machine learning approaches have begun to address nested entity challenges through architectural innovations. Sequence-to-sequence models with attention mechanisms can potentially capture overlapping entity structures, while graph neural networks offer promising avenues for modeling complex entity relationships directly.
Multi-task learning frameworks allow models to simultaneously predict multiple entity types and their relationships, potentially improving performance on nested entity recognition tasks. However, these approaches require carefully designed loss functions and training procedures to balance competing objectives effectively.
Domain-Specific Challenges
Biomedical Text Processing
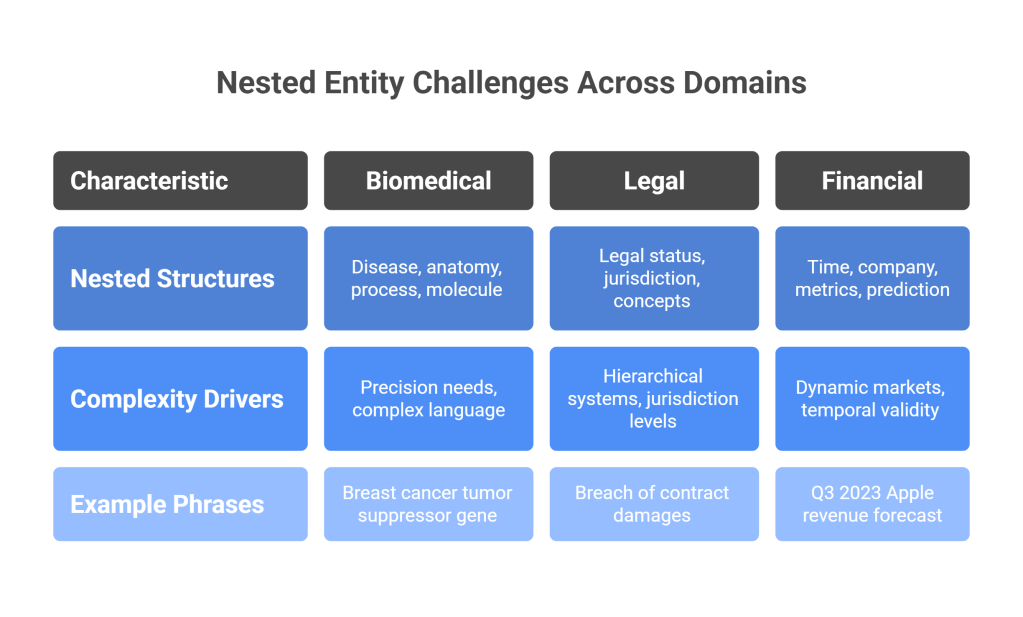
The biomedical domain presents particularly complex nested entity challenges. Medical texts frequently contain nested structures like “breast cancer tumor suppressor gene,” where disease (“breast cancer”), anatomy (“tumor”), biological process (“suppressor”), and molecular entity (“gene”) categories all overlap. The precision required in medical applications makes annotation errors particularly costly, yet the complexity of biomedical language makes perfect annotation extremely difficult.
Pharmaceutical research documents often contain nested drug-condition-dosage relationships that require careful annotation to support drug discovery and safety monitoring systems. The temporal aspects of medical treatments add another layer of complexity, as treatments, conditions, and outcomes may be nested within temporal expressions.
Legal Document Analysis
Legal texts present unique nested entity challenges, particularly in contract analysis and case law processing. Legal entities like “Delaware corporation” involve both legal status (“corporation”) and jurisdiction (“Delaware”), while phrases like “breach of contract damages” nest legal concepts (“breach of contract”) with consequences (“damages”).
The hierarchical nature of legal systems creates additional complexity, as legal entities may exist at multiple jurisdictional levels simultaneously. A “federal district court judge” involves federal jurisdiction, court type, and professional role, all of which may be relevant for different legal analysis tasks.
Financial Text Processing
Financial documents frequently contain nested entity structures that combine temporal, quantitative, and organizational information. Phrases like “Q3 2023 Apple revenue forecast” involve time periods, companies, financial metrics, and prediction types, all of which may be relevant for financial analysis applications.
The dynamic nature of financial markets adds complexity, as entity relationships may change rapidly, and annotation systems must account for temporal validity of nested entity structures. Merger and acquisition activities create particular challenges, as company names and organizational structures may be nested within transaction descriptions.
Quality Control and Consistency
Establishing Annotation Guidelines
Developing comprehensive annotation guidelines for nested entities requires careful consideration of edge cases and potential conflicts. Guidelines must address how to handle ambiguous cases, provide clear decision trees for complex scenarios, and establish precedents for consistent annotation across large datasets.
The guidelines must also consider the downstream applications of the annotated data. Different use cases may require different approaches to nested entity annotation, and guidelines should reflect these application-specific requirements while maintaining internal consistency.
Measuring Annotation Quality
Traditional inter-annotator agreement metrics may not adequately capture the complexity of nested entity annotation quality. New metrics that account for partial overlaps, hierarchical relationships, and multiple valid interpretations are needed to properly evaluate annotation consistency.
Quality control processes must also adapt to the increased complexity of nested entity annotation. Regular calibration exercises, continuous training programs, and sophisticated quality monitoring systems become essential for maintaining annotation standards across large projects.
Technological Solutions and Tools
Annotation Interfaces
Modern annotation tools have begun incorporating features specifically designed for nested entity annotation. Multi-layer annotation interfaces allow annotators to work with different entity types simultaneously, while hierarchical visualization tools help annotators understand complex nested structures.
Active learning approaches can help prioritize the most challenging or informative examples for human annotation, potentially reducing the overall annotation burden while improving model performance on nested entity recognition tasks.
Automated Assistance
Semi-automated annotation systems can provide suggestions for nested entity structures, allowing human annotators to focus on verification and correction rather than initial identification. These systems can leverage pre-trained models and rule-based approaches to propose candidate nested entity structures.
However, automated assistance systems must be carefully designed to avoid introducing systematic biases or reinforcing incorrect annotation patterns. The complexity of nested entity annotation makes it particularly susceptible to automation bias, where annotators may over-rely on automated suggestions.
Impact on Model Performance
Training Complexity
Models trained on nested entity data face unique challenges in balancing competing objectives and learning complex relationship patterns. The increased complexity of nested entity annotation can lead to sparser training signals and more difficult optimization landscapes.
Data augmentation techniques specifically designed for nested entities can help address training data limitations, but these approaches must carefully preserve the semantic relationships that make nested entities meaningful.
Evaluation Challenges
Evaluating model performance on nested entity recognition tasks requires sophisticated metrics that account for partial matches, hierarchical relationships, and multiple valid interpretations. Traditional precision and recall metrics may not adequately capture model performance on complex nested structures.
The development of standardized evaluation frameworks for nested entity recognition remains an active area of research, with different approaches emphasizing different aspects of nested entity understanding.
Future Directions and Innovations
Emerging Technologies
Large language models and transformer architectures show promise for handling nested entity recognition tasks, potentially learning complex entity relationships from context without explicit structural annotation. However, these approaches require careful evaluation to ensure they capture meaningful semantic relationships rather than superficial patterns.
Few-shot and zero-shot learning approaches may help address the annotation bottleneck for nested entities, allowing models to recognize new entity types and relationships with minimal training data.
Standardization Efforts
The development of standardized annotation schemas and evaluation frameworks for nested entities could help accelerate progress in this area. Community-driven initiatives to establish best practices and shared resources would benefit the entire field.
Cross-domain transfer learning approaches may help leverage annotation efforts across different domains, reducing the overall annotation burden for nested entity recognition systems.
Conclusion
The challenge of annotating nested entities represents a fundamental tension between the complexity of natural language and the structured requirements of machine learning systems. As NLP applications become more sophisticated and are applied to increasingly complex domains, the ability to accurately identify and represent nested entity structures becomes ever more critical.
The path forward requires continued innovation in annotation methodologies, tool development, and model architectures. Success in this area will depend on close collaboration between linguists, computer scientists, and domain experts to develop approaches that are both theoretically sound and practically effective.
The investment in solving nested entity annotation challenges will pay dividends across numerous applications, from improved information extraction systems to more sophisticated question-answering capabilities. As we continue to push the boundaries of what machines can understand about human language, the careful annotation of nested entities remains a crucial foundation for future breakthroughs in natural language processing.
The complexity of nested entity annotation reflects the broader challenge of teaching machines to understand the nuanced, layered nature of human communication. While the technical challenges are significant, the continued development of sophisticated annotation approaches, tools, and methodologies promises to unlock new capabilities in automated text understanding and processing.
Discover more from SkillWisor
Subscribe to get the latest posts sent to your email.
