
Introduction: When JSON Becomes Too Expensive
For over two decades, JSON has reigned supreme as the go-to format for data exchange across the internet. Since Douglas Crockford introduced it in the early 2000s, it’s become the universal language that APIs speak. Human-readable, simple, and universally supported—JSON seemed perfect for the web era.
But we’re no longer just building for humans. We’re building for AI.
As artificial intelligence systems have become central to modern applications, a critical limitation of JSON has emerged: it’s incredibly token-hungry. In a world where every interaction with GPT, Claude, or Gemini costs money based on token count, JSON’s verbosity translates directly into higher operational costs and slower processing times.
Enter TOON—Token-Oriented Object Notation—a fresh approach to data serialization built specifically for the age of large language models.
Understanding the Token Problem
Before diving into TOON itself, it’s essential to understand why tokens matter so much in AI applications.
Large language models don’t process text the way humans do. They break everything down into tokens—small chunks that represent words, parts of words, or symbols. Every API call to an LLM charges based on how many tokens you send (input) and receive (output).
Here’s where JSON becomes problematic: all those curly braces, quotation marks, colons, and repeated key names? They all count as tokens. When you’re sending structured data to an AI model—perhaps a list of 300 products or a complex dataset for analysis—you might be burning through thousands of tokens just on formatting syntax.
That’s wasted money and wasted processing power.
What Makes TOON Different?
TOON takes a radically different approach. Instead of repeating structure for every data element, it declares the schema once and then presents the data in a streamlined, table-like format.
Consider this comparison:
Traditional JSON approach:
{
"users": [
{ "id": 1, "name": "Alice", "role": "admin" },
{ "id": 2, "name": "Bob", "role": "user" }
]
}
TOON’s approach:
users[2]{id,name,role}:
1,Alice,admin
2,Bob,user
The difference is striking. TOON eliminates quotation marks entirely, removes redundant braces and brackets, and declares the structure once in a header-like format. The actual data then flows cleanly underneath.
The schema declaration users[2]{id,name,role}: tells us everything we need to know: we have an array called “users” containing 2 items, each with three fields—id, name, and role. After that, it’s just pure data.
Real-World Token Savings
The efficiency gains aren’t theoretical. Depending on your data structure, TOON can reduce token consumption by 30 to 50 percent compared to equivalent JSON representations.
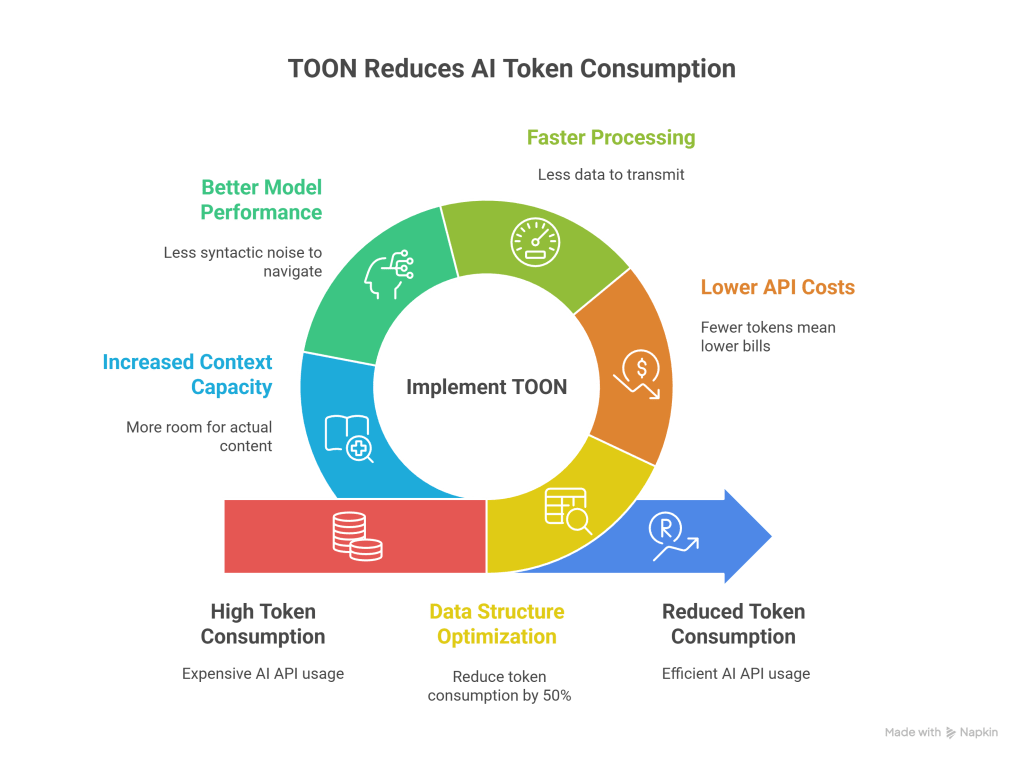
For businesses running AI applications at scale, this translates to:
- Lower API costs: Fewer tokens mean lower bills from OpenAI, Anthropic, or Google
- Faster processing: Less data to transmit and parse
- Better model performance: Less syntactic noise for the AI to navigate
- Increased context capacity: More room for actual content within token limits
TOON Syntax Patterns
Let’s explore how TOON handles common data structures:
Simple Objects
For flat key-value pairs, TOON uses a straightforward colon separator:
name: Alice
age: 30
city: Bengaluru
No braces, no commas between properties, no quotation marks.
Arrays of Primitives
When you have a simple list of values:
colors[3]: red,green,blue
The bracket notation indicates array size, and values are comma-separated.
Arrays of Objects (The Power Case)
This is where TOON really shines:
products[3]{id,name,price}:
101,Laptop,899.99
102,Mouse,24.99
103,Keyboard,79.99
One schema declaration, three data rows. Compare this to JSON’s repeated key names and nested structure.
Nested Structures
TOON handles nesting through indentation, similar to YAML:
user:
id: 1
name: Alice
profile:
age: 30
city: Bengaluru
Complex Nested Arrays
Even complex structures remain readable:
teams[1]:
- name: Team Alpha
members[2]{id,name}:
1,Alice
2,Bob
Implementing TOON in Your Projects
JavaScript and TypeScript Integration
The official TOON package for Node.js makes implementation straightforward:
npm install @toon-format/toon
Encoding JSON to TOON:
import { encode } from "@toon-format/toon";
const productData = {
products: [
{ id: 1, name: "Widget", price: 29.99 },
{ id: 2, name: "Gadget", price: 49.99 }
]
};
const toonFormat = encode(productData);
console.log(toonFormat);
Decoding TOON back to JSON:
import { decode } from "@toon-format/toon";
const toonData = `
products[2]{id,name,price}:
1,Widget,29.99
2,Gadget,49.99
`;
const jsonObject = decode(toonData);
Python Implementation
Python developers can leverage the python-toon package:
pip install python-toon
Converting to TOON:
from toon import encode
channel_info = {
"name": "TechChannel",
"subscribers": 50000,
"category": "education"
}
toon_output = encode(channel_info)
print(toon_output)
Parsing TOON data:
from toon import decode
toon_string = """
name: TechChannel
subscribers: 50000
category: education
"""
data_dict = decode(toon_string)
print(data_dict)
When to Use TOON (and When to Stick with JSON)
TOON isn’t a silver bullet. It excels in specific scenarios but isn’t appropriate everywhere.
Ideal TOON Use Cases:
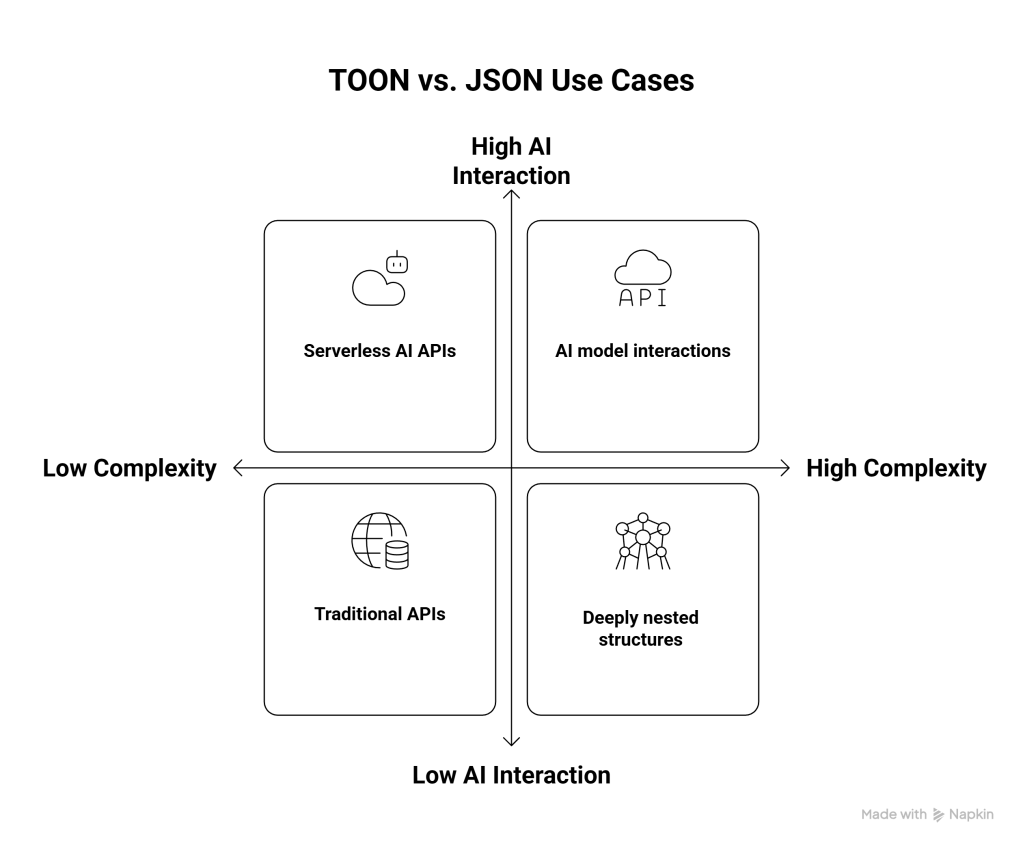
- AI model interactions: When sending structured data to or receiving it from LLMs
- Uniform datasets: Arrays of objects with consistent schemas
- Cost-sensitive applications: Where token efficiency directly impacts your budget
- Training data preparation: For fine-tuning models with large structured datasets
- Agent frameworks: Where AI agents exchange structured information
- Serverless AI APIs: Where every millisecond and token counts
Stick with JSON When:
- Deep nesting is common: JSON handles complex hierarchies more naturally
- Schema varies significantly: Irregular data structures work better in JSON
- Strict validation is required: JSON schema validation is mature and widespread
- Non-AI systems: Traditional APIs, databases, and web applications
- Interoperability is critical: JSON’s universal support remains unmatched
The smartest approach? Use both strategically. Keep JSON for your standard API communications, but convert to TOON when interacting with language models.
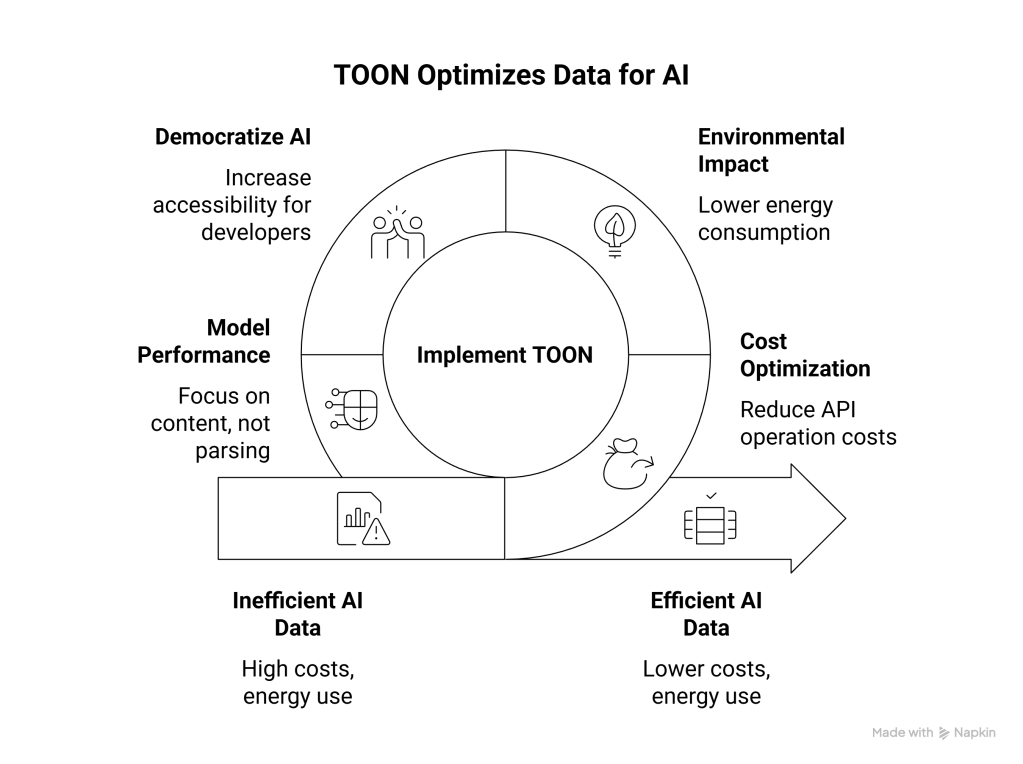
The Broader Impact on AI Development
TOON’s emergence signals a larger shift in how we think about data in the AI era. Just as JSON was optimized for human readability and web APIs, TOON is optimized for machine efficiency and AI workflows.
This matters for several reasons:
Cost optimization at scale: Companies running thousands of AI operations daily can save significant amounts on API costs through more efficient data formatting.
Environmental considerations: Fewer tokens mean less computational power required, which translates to reduced energy consumption across data centers.
Democratizing AI: Lower costs make AI applications more accessible to startups and individual developers who might be priced out by token-heavy architectures.
Model performance: By reducing syntactic clutter, LLMs can focus more on the actual content rather than parsing verbose formatting.
Current Adoption and Future Trajectory
While TOON is still relatively new, it’s gaining traction rapidly within the AI development community. Early adopters are exploring its potential across various domains:
- Fine-tuning LLMs with more compact training datasets
- Building efficient AI agent communication protocols
- Optimizing data flow in Model Context Protocol (MCP) implementations
- Reducing overhead in serverless AI architectures
The format has libraries available for major programming languages including JavaScript, TypeScript, Python, Go, and Rust—indicating serious community investment in its future.
Practical Tips for Getting Started
If you’re considering integrating TOON into your workflow:
- Start with analysis: Profile your current JSON payload sizes and calculate potential token savings
- Prototype with one endpoint: Choose a single AI interaction point to test TOON
- Measure real-world impact: Track actual cost and performance differences
- Build abstractions: Create conversion utilities so your team can switch between formats seamlessly
- Document schema conventions: Since TOON is newer, clear documentation helps team adoption
Conclusion: A Tool for the AI Era
TOON represents thoughtful innovation addressing a real problem in modern AI development. It’s not trying to replace JSON everywhere—that would be neither practical nor necessary. Instead, it’s carving out a specific niche where token efficiency matters most.
As AI continues to integrate deeper into our applications and workflows, having data formats optimized for machine consumption makes increasing sense. TOON may well become as standard for AI interactions as JSON became for web APIs.
The next time you’re building an LLM-powered feature, designing an AI agent system, or simply crafting a complex prompt with structured data, consider giving TOON a try. The tokens you save could translate to real value—both for your budget and your application’s performance.
The future of data serialization isn’t about choosing one format over another. It’s about having the right tool for each job. And for AI workloads, TOON is proving to be exactly that.
Discover more from SkillWisor
Subscribe to get the latest posts sent to your email.
