

The landscape of Artificial Intelligence is undergoing a rapid and profound transformation. While data science has traditionally focused on extracting insights and building predictive models from data, a new paradigm is emerging: AI Agents. These are autonomous systems capable of perceiving their environment, making decisions, and taking actions to achieve specific goals. This evolution presents both an exciting opportunity and a learning curve for data scientists, requiring them to expand their skill sets beyond classical machine learning and statistical modeling. This article provides an in-depth exploration of the key competencies and technologies that bridge the gap between data science and the development of sophisticated AI Agents.
The Shifting Paradigm: Why AI Agents?
Traditional AI models, including those built by data scientists, often operate as passive predictors or classifiers. They take an input, process it, and produce an output. AI Agents, however, are designed to be proactive and interactive. They can engage in complex dialogues, utilize external tools, learn from interactions, and execute multi-step tasks. The rise of powerful Large Language Models (LLMs) has been a primary catalyst for this shift, providing the core reasoning and language understanding capabilities that make such agents feasible.
For a data scientist, this transition means moving from primarily analyzing data and building models to designing, building, and orchestrating intelligent systems that can act on their own behalf. It requires a blend of software engineering best practices, a deep understanding of LLM capabilities and limitations, and the ability to integrate various components into a cohesive and effective whole.
I. Foundational Python Knowledge for AI Agent Development
Python remains the lingua franca of AI development, and its importance is only amplified when building AI Agents. Beyond basic scripting and data manipulation with libraries like Pandas and NumPy, several advanced Python concepts and tools become critical.
A. FastAPI: Building Performant APIs for Agents
AI Agents often need to expose their functionalities via APIs or interact with other services. FastAPI has rapidly become a preferred framework for building high-performance, asynchronous APIs in Python.
What is FastAPI?
FastAPI is a modern, fast (high-performance) web framework for building APIs with Python 3.7+ based on standard Python type hints. Its key features include:
- Speed: FastAPI is built on top of Starlette (for the web parts) and Pydantic (for the data parts), making it one of the fastest Python frameworks available, comparable to NodeJS and Go. This is crucial for AI agents that require low-latency responses.
- Asynchronous Support: Native support for
asyncandawaitallows for concurrent handling of requests, essential for I/O-bound operations like calling LLMs or external tools without blocking the main thread. - Type Safety and Data Validation: Leveraging Pydantic, FastAPI provides automatic data validation, serialization, and deserialization based on Python type hints. This significantly reduces errors and improves code robustness.
- Automatic Documentation: It automatically generates interactive API documentation (using Swagger UI and ReDoc), which is invaluable for testing, debugging, and collaboration.
- Developer Experience: FastAPI is designed to be easy to use and learn, with excellent editor support (autocompletion, type checking) thanks to its reliance on type hints.
Why FastAPI for AI Agents?
- Serving Agent Capabilities: If your AI agent needs to be accessible as a service (e.g., a chatbot API, a task automation endpoint), FastAPI allows you to quickly build robust and scalable endpoints.
- Internal Microservices: Complex agents might be composed of multiple microservices (e.g., a service for RAG, another for tool execution). FastAPI is well-suited for building these internal communication layers.
- Tool Integration: Agents often use tools that are exposed as APIs. While the agent consumes these, you might also build helper APIs or shims using FastAPI to interface with legacy systems or custom logic.
- Real-time Interactions: For agents requiring real-time communication (e.g., via WebSockets for live chat or streaming responses), FastAPI (through Starlette) provides excellent support.
Example Scenario:
Imagine an AI agent that provides customer support. FastAPI could be used to create an endpoint where user queries are received. The agent processes the query (potentially calling an LLM and a RAG system), and FastAPI returns the agent’s response. The asynchronous nature ensures that the server can handle many concurrent users efficiently.
# Conceptual FastAPI example for an agent endpoint
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class QueryRequest(BaseModel):
user_id: str
text: str
class AgentResponse(BaseModel):
response_text: str
confidence: float
# This would be your agent's core logic
async def process_query_with_agent(query: QueryRequest) -> AgentResponse:
# Simulate agent processing (e.g., LLM call, RAG)
await asyncio.sleep(1) # Represents I/O-bound work
return AgentResponse(response_text=f"Agent processed: {query.text}", confidence=0.9)
@app.post("/query_agent/", response_model=AgentResponse)
async def handle_agent_query(request: QueryRequest):
agent_reply = await process_query_with_agent(request)
return agent_reply
B. Asynchronous Programming (async/await)
AI Agents are inherently I/O-bound. They spend a significant amount of time waiting for responses from LLMs, databases, external APIs (tools), or user inputs. Synchronous programming would lead to an agent freezing while waiting, unable to handle other tasks or requests. Asynchronous programming with Python’s asyncio library and the async/await syntax is therefore indispensable.
Core Concepts:
- Coroutines: These are special functions defined with
async def. When called, they return a coroutine object, which is a type of awaitable. await: This keyword is used inside anasync deffunction to pause its execution until the awaited coroutine (or other awaitable) completes. While paused, the event loop can run other tasks.- Event Loop:
asynciouses an event loop to manage and execute multiple coroutines concurrently. It keeps track of which tasks are ready to run and which are waiting for I/O.
Benefits for AI Agents:
- Concurrency: Handle multiple operations simultaneously without threads. For example, an agent might query an LLM, fetch data from a vector database, and call a web search tool concurrently.
- Responsiveness: Keep the agent responsive, especially if it has a user interface or needs to handle multiple user requests.
- Efficiency: Reduce resource consumption compared to thread-based concurrency for I/O-bound tasks, as it avoids the overhead of creating and managing threads.
Challenges:
- Learning Curve: Asynchronous programming can be conceptually more complex than synchronous programming.
- Library Compatibility: Not all libraries are natively
async-compatible, though the ecosystem is rapidly improving. Wrappers or thread pool executors might be needed.
Example Scenario:
An agent needs to gather information from three different web APIs before formulating a response. Using asyncio.gather, these API calls can be made concurrently:
import asyncio
import httpx # An async-friendly HTTP client
async def fetch_data(url: str):
async with httpx.AsyncClient() as client:
print(f"Starting to fetch {url}")
response = await client.get(url)
print(f"Finished fetching {url}")
return response.json() # Or response.text
async def main_agent_task():
urls = [
"https://api.example.com/data1",
"https://api.example.com/data2",
"https://api.example.com/data3",
]
# Gather runs multiple awaitables concurrently
results = await asyncio.gather(
fetch_data(urls[0]),
fetch_data(urls[1]),
fetch_data(urls[2])
)
# Process results...
print("All data fetched and processed.")
# asyncio.run(main_agent_task()) # To run the main task
C. Pydantic: Data Validation and Settings Management
Pydantic is a data validation and parsing library that uses Python type hints. It enforces data types and constraints at runtime, which is crucial for ensuring the reliability of AI agents that deal with diverse and potentially unpredictable inputs and outputs.
Key Features:
- Type Enforcement: Ensures that data conforms to the expected types (e.g.,
int,str,List[SomeModel]). - Data Coercion: Can intelligently coerce data into the correct types (e.g., converting a string “123” to an integer 123).
- Custom Validation: Allows for complex validation logic using validator decorators.
- Settings Management: Pydantic’s
BaseSettingsclass can load configuration from environment variables,.envfiles, or secret files, simplifying application configuration. - Serialization/Deserialization: Easily convert Pydantic models to and from dictionaries, JSON, etc.
Why Pydantic for AI Agents?
- Validating LLM Inputs/Outputs: LLMs can sometimes produce outputs that don’t strictly adhere to a desired format. Pydantic models can validate LLM responses or structure inputs to LLMs.
- Tool Input/Output Schemas: When an agent uses tools, Pydantic can define and validate the schemas for tool inputs and outputs, ensuring compatibility and preventing errors.
- Configuration Management: Agents often require various API keys, model identifiers, thresholds, etc. Pydantic makes managing these settings robust and straightforward.
- API Request/Response Models: As seen with FastAPI, Pydantic is integral for defining the structure of API requests and responses.
- State Management: The internal state of an agent can be represented and validated using Pydantic models.
Example Scenario:
An agent uses a tool that expects a location (city and country) and returns weather information. Pydantic can define these structures:
from pydantic import BaseModel, field_validator
from typing import Optional
class LocationInput(BaseModel):
city: str
country_code: str # e.g., "US", "GB"
@field_validator('country_code')
def validate_country_code(cls, value):
if len(value) != 2 or not value.isupper():
raise ValueError("Country code must be two uppercase letters.")
return value
class WeatherOutput(BaseModel):
temperature_celsius: float
description: str
humidity_percent: Optional[float] = None
# Usage:
try:
# Valid input
location = LocationInput(city="London", country_code="GB")
# Invalid input
# location_invalid = LocationInput(city="Paris", country_code="Fr")
except ValueError as e:
print(f"Validation Error: {e}")
# Simulating tool output
tool_response = {"temperature_celsius": 15.5, "description": "Cloudy"}
weather = WeatherOutput(**tool_response)
print(weather.model_dump_json())
D. API Management
While FastAPI helps build APIs, managing them effectively is a broader concern, especially if agents expose services or rely heavily on external APIs.
Key Aspects:
- Versioning: As agent capabilities evolve, API versioning (e.g.,
/v1/agent,/v2/agent) is crucial to avoid breaking existing integrations. - Authentication and Authorization: Secure your agent’s APIs. Common methods include API keys, OAuth2, JWT tokens. Ensure that only authorized users or services can access sensitive functionalities.
- Rate Limiting: Protect your agent and its underlying resources (like LLM API calls, which can be costly) from abuse or overload by implementing rate limiting.
- Documentation: Maintain clear, up-to-date API documentation (FastAPI helps, but broader context might be needed).
- Monitoring and Analytics: Track API usage, performance (latency, error rates), and other relevant metrics.
- API Gateways: For complex deployments, an API gateway (e.g., Amazon API Gateway, Kong, Apigee) can handle many of these concerns centrally.
Relevance to AI Agents:
- If an agent is offered as a product, robust API management is non-negotiable.
- Even for internal agents, good API practices improve maintainability and scalability.
- When agents consume external tool APIs, understanding these concepts helps in being a good API citizen (e.g., respecting rate limits).
E. Logging and Alerting
AI Agents can be complex, and their behavior, especially when involving LLMs, can sometimes be unpredictable. Comprehensive logging and proactive alerting are vital for debugging, monitoring, and maintaining reliability.
Logging Best Practices:
- Structured Logging: Use libraries like
structlogor configure Python’s built-inloggingmodule to output logs in a structured format (e.g., JSON). This makes logs easier to parse, search, and analyze. - Log Levels: Utilize different log levels (DEBUG, INFO, WARNING, ERROR, CRITICAL) appropriately.
- Contextual Information: Include relevant context in logs, such as user ID, session ID, agent state, LLM inputs/outputs (be mindful of PII and data privacy), and tool calls.
- Correlation IDs: Use correlation IDs to trace a single request or task execution across multiple services or components of the agent.
- Centralized Logging: Send logs to a centralized logging platform (e.g., ELK Stack, Splunk, Datadog, AWS CloudWatch Logs) for easier analysis and retention.
Alerting:
- Key Metrics: Set up alerts for critical metrics:
- Error rates (API errors, tool failures, LLM exceptions).
- High latency in agent responses.
- Resource utilization (CPU, memory, LLM token consumption).
- Unexpected agent behavior (e.g., loops, nonsensical outputs detected by heuristics).
- Integration with Monitoring Tools: Use monitoring platforms that support alerting (e.g., Prometheus with Alertmanager, Datadog, Grafana).
- Actionable Alerts: Ensure alerts are actionable and provide enough information to diagnose the issue.
Why Critical for Agents?
The “black box” nature of LLMs makes it essential to log the prompts sent and responses received. If an agent misbehaves, these logs are the first place to look. Alerting can notify developers of systemic issues before they impact many users.
F. Unit and Integration Testing
As AI agent systems grow in complexity, rigorous testing becomes paramount to ensure reliability and facilitate refactoring.
- Unit Tests:
- Focus on testing individual components or functions in isolation.
- For an agent, this could mean testing:
- A specific prompt generation function.
- A data parsing utility.
- The logic of a single state in a state machine (if using LangGraph).
- Mocking external dependencies (LLMs, databases, APIs) is crucial for unit tests to be fast and deterministic. Libraries like
unittest.mockorpytest-mockare essential.
- Integration Tests:
- Test how different parts of the agent work together.
- Examples:
- Testing the flow of a RAG pipeline (retrieval + generation).
- Testing the interaction between the agent’s core logic and a tool it uses.
- Testing the API endpoints with a live (but perhaps sandboxed) LLM or database.
- These tests are generally slower and more complex to set up than unit tests but provide more confidence in the overall system.
Testing LLM-based Components:
Testing components that rely on LLMs is challenging due to the non-deterministic nature of LLMs and the cost/latency of API calls. Strategies include:
- Snapshot Testing: Store “golden” LLM outputs for fixed inputs and compare against them. This can catch unintended changes due to prompt modifications or model updates.
- Evaluation Sets: Create a curated set of input prompts and desired output characteristics. Run these through the agent and evaluate the quality of responses (can be partially automated with metrics or even other LLMs for evaluation).
- Focus on the “Plumbing”: Even if the LLM output is variable, test that the data flows correctly to and from the LLM, that tools are called appropriately, and that errors are handled gracefully.
G. Database Management (e.g., SQLAlchemy)
Many AI agents require persistence – storing data that outlives a single interaction. This can include:
- Conversation History: Essential for context in ongoing dialogues.
- User Preferences: To personalize agent behavior.
- Agent State: For long-running tasks or resumable interactions.
- Knowledge Bases: While vector DBs handle embeddings, structured metadata or smaller knowledge graphs might reside in relational or NoSQL databases.
- Logging and Audit Trails: Storing detailed records of agent actions.
SQLAlchemy:
SQLAlchemy is a popular Object-Relational Mapper (ORM) for Python. It allows developers to interact with relational databases using Python objects and methods, abstracting away much of the raw SQL.
- Benefits:
- Database Agnostic: Supports multiple database backends (PostgreSQL, MySQL, SQLite, etc.).
- Pythonic Interface: Work with database tables and rows as Python classes and instances.
- Schema Management: Tools like Alembic (often used with SQLAlchemy) help manage database schema migrations.
- Reduces Boilerplate: Simplifies common database operations.
Alternatives:
- NoSQL Databases: For certain types of data (e.g., document-oriented like MongoDB for flexible schemas, or key-value stores like Redis for caching), NoSQL databases might be more appropriate.
- Direct SQL: For simple needs or performance-critical queries, writing raw SQL (e.g., using libraries like
psycopg2for PostgreSQL) is also an option.
Considerations for AI Agents:
- Scalability: Choose a database solution that can scale with the number of users and interactions.
- Data Modeling: Carefully design your database schemas to efficiently store and retrieve agent-related data.
- Asynchronous Access: If using
asyncio, ensure your database library or ORM supports asynchronous operations (e.g.,asyncpgfor PostgreSQL,aiosqlitefor SQLite, SQLAlchemy has async support).
II. RAG (Retrieval Augmented Generation): Grounding Agents in Knowledge
LLMs, while powerful, have limitations: their knowledge is frozen at the time of training (knowledge cutoff), and they can “hallucinate” or generate plausible but incorrect information. Retrieval Augmented Generation (RAG) is a technique that addresses these issues by providing the LLM with relevant, up-to-date information from external knowledge sources at inference time.
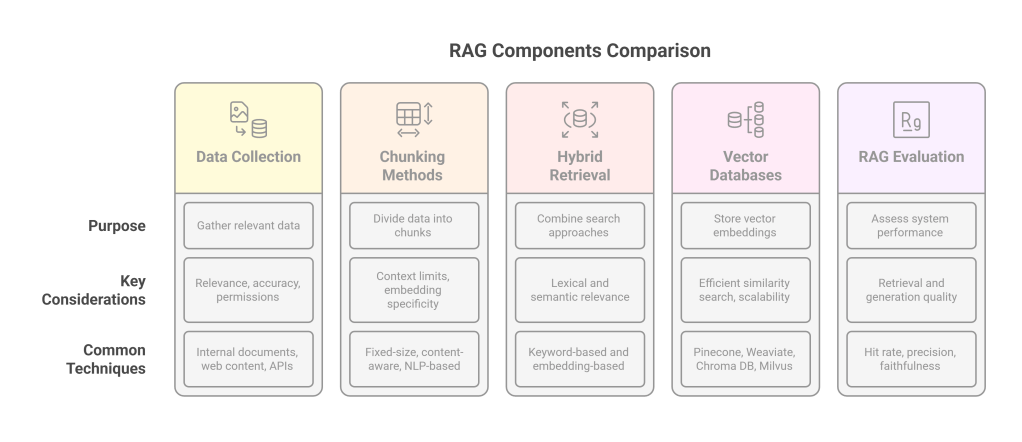
A. Data Collection for RAG
The effectiveness of a RAG system heavily depends on the quality, relevance, and comprehensiveness of the data it can retrieve.
Sources of Data:
- Internal Documents: PDFs, Word documents, Confluence pages, SharePoint sites, text files, code repositories.
- Databases: Structured data from SQL or NoSQL databases.
- Web Content: Public websites, articles, forums (requires web scraping and cleaning).
- User-Generated Content: Support tickets, chat logs (anonymized and with consent).
- APIs: Data accessible via third-party or internal APIs.
Key Considerations:
- Relevance: The data should be directly relevant to the topics the AI agent is expected to handle.
- Accuracy and Currency: Ensure the data is accurate and kept up-to-date. Stale or incorrect information will lead to poor RAG performance.
- Format and Structure: Data comes in various formats. Preprocessing is needed to extract clean text.
- Permissions and Access: Ensure you have the right to use the data and that access controls are respected.
- Data Cleaning: Remove noise, irrelevant sections (headers, footers, ads), and correct errors. This might involve HTML parsing, OCR for scanned documents, and text normalization.
- Incremental Updates: Develop a strategy for ingesting new or updated documents into the RAG system.
B. Chunking Methods
Once raw data is collected, it needs to be broken down into smaller, manageable “chunks” before being converted into embeddings. The way data is chunked significantly impacts retrieval quality.
Why Chunk?
- Context Window Limits: LLMs have finite context windows. Retrieved chunks need to fit alongside the prompt and generation space.
- Embedding Specificity: Embeddings of very long documents can lose specificity. Smaller chunks allow for more focused semantic representation.
- Retrieval Granularity: Chunking determines the granularity of the information retrieved.
Common Chunking Strategies:
- Fixed-Size Chunking:
- Split text into chunks of a fixed number of characters or tokens.
- Often with an overlap (e.g., 512 tokens per chunk, 64 tokens overlap) to ensure semantic continuity is not lost at chunk boundaries.
- Simple to implement but can awkwardly split sentences or ideas.
- Content-Aware Chunking (Semantic Chunking):
- Sentence Splitting: Split text by sentences. Each sentence or a small group of consecutive sentences becomes a chunk.
- Paragraph Splitting: Treat each paragraph as a chunk.
- Recursive Character Text Splitting: (Common in LangChain) Tries to split based on a hierarchy of separators (e.g.,
\n\n,\n, , “). It attempts to keep semantically related pieces of text together as much as possible. - Markdown/HTML Splitting: Use structural elements (headers, sections, list items in Markdown; tags in HTML) to guide chunking.
- NLP-based Chunking: More advanced methods might use NLP techniques to identify thematic breaks or coherent segments of text.
Choosing a Strategy:
- Depends on the nature of the data (prose, code, structured text).
- Experimentation is often needed.
- Consider the downstream LLM’s token limit and how much context it can effectively use.
C. Hybrid Retrieval: The Best of Both Worlds
Retrieval aims to find the most relevant chunks of text for a given query. There are two main approaches:
- Keyword-Based (Sparse Retrieval):
- Traditional search methods like TF-IDF (Term Frequency-Inverse Document Frequency) or BM25 (Best Matching 25).
- They match exact keywords or their variations (stemming, lemmatization).
- Pros: Good for queries with specific terms, acronyms, or codes that semantic search might miss. Computationally efficient.
- Cons: Can miss semantically similar content if different wording is used. Struggles with synonyms and conceptual queries.
- Embedding-Based (Dense/Semantic Retrieval):
- Converts text chunks and queries into dense vector embeddings using models like Sentence Transformers, OpenAI embeddings, or Cohere embeddings.
- Similarity is measured by the cosine distance (or dot product, Euclidean distance) between query and chunk embeddings.
- Pros: Captures semantic meaning, synonyms, and related concepts even if keywords don’t match. Excellent for conceptual queries.
- Cons: Can sometimes miss specific keyword matches if the semantic meaning is diluted. Requires more computational resources for embedding generation and similarity search.
Hybrid Retrieval:
Combines the strengths of both sparse and dense retrieval.
- Process:
- Retrieve a set of candidate documents using both keyword search and semantic search.
- Re-rank the combined results using a fusion algorithm (e.g., Reciprocal Rank Fusion – RRF) or a learned re-ranking model to produce the final set of chunks.
- Benefits: Often yields superior retrieval performance by capturing both lexical and semantic relevance. More robust to different types of queries.
D. Vector Databases
Vector databases are specialized databases designed to store, manage, and efficiently query large collections of vector embeddings.
Why Specialized Databases?
- Efficient Similarity Search: Traditional databases are not optimized for finding the “nearest neighbors” in high-dimensional vector spaces. Vector databases use specialized indexing algorithms (e.g., HNSW, IVFADC, LSH) to perform Approximate Nearest Neighbor (ANN) search quickly.
- Scalability: Can handle billions of embeddings.
- Metadata Filtering: Allow storing metadata alongside vectors and filtering search results based on this metadata (e.g., “find documents similar to X, but only from source Y published after date Z”).
- CRUD Operations: Support creating, reading, updating, and deleting vectors and their metadata.
Popular Vector Databases:
- Pinecone: Managed cloud service.
- Weaviate: Open-source, can be self-hosted or used as a managed service. Supports GraphQL.
- Chroma DB: Open-source, focuses on developer experience, often used for in-process or local development.
- Milvus: Open-source, highly scalable.
- Qdrant: Open-source, written in Rust for performance.
- Elasticsearch: While primarily a text search engine, it has added robust support for dense vector search.
- PostgreSQL with pgvector: An extension for PostgreSQL that adds vector similarity search capabilities.
Integration with RAG:
- Data chunks are embedded.
- Embeddings (and often the original text/metadata) are stored in the vector database.
- When a user queries the agent, the query is embedded.
- The query embedding is used to search the vector database for the most similar document chunk embeddings.
- The corresponding text chunks are retrieved and passed to the LLM.
E. RAG Evaluation
Evaluating the performance of a RAG system is crucial for iteration and improvement. It’s a multi-faceted problem, involving assessing both the retrieval and the generation components.
Key Metrics and Approaches:
- Retrieval Evaluation:
- Hit Rate: Does the retriever find at least one relevant document in its top-k results?
- Precision@k: Proportion of retrieved documents in the top-k that are relevant.
- Recall@k: Proportion of all relevant documents in the dataset that are retrieved in the top-k.
- Mean Reciprocal Rank (MRR): Average of the reciprocal ranks of the first relevant document. Good for when only one correct answer is expected.
- Normalized Discounted Cumulative Gain (nDCG): Considers the position and graded relevance of retrieved documents.
- Requires a “ground truth” dataset: A set of queries with manually labeled relevant documents.
- Generation Evaluation (Contextualized by Retrieved Docs):
- Faithfulness / Groundedness: Does the LLM’s answer stay true to the information in the retrieved documents? Does it avoid hallucinating facts not present in the context?
- Can be assessed manually or using other LLMs as evaluators (e.g., prompting an LLM to check if the answer is supported by the context).
- Answer Relevance: Is the generated answer relevant to the original user query (not just the retrieved context)?
- Information Integration: If multiple documents are retrieved, how well does the LLM synthesize information from them?
- Fluency and Coherence: Standard language quality metrics.
- Faithfulness / Groundedness: Does the LLM’s answer stay true to the information in the retrieved documents? Does it avoid hallucinating facts not present in the context?
- End-to-End Evaluation:
- Assess the overall quality of the RAG system’s final output.
- Often involves human evaluation on a diverse set of queries.
- Frameworks like RAGAs (RAG Assessment) provide tools and metrics for evaluating RAG pipelines.
Challenges:
- Creating good evaluation datasets is time-consuming.
- Automated metrics for generation quality are still an active area of research and may not always align with human judgment.
III. AI Agent Frameworks: Orchestrating Intelligence
As AI agents become more complex, involving multiple LLM calls, tool usage, and state management, frameworks are needed to orchestrate these components.
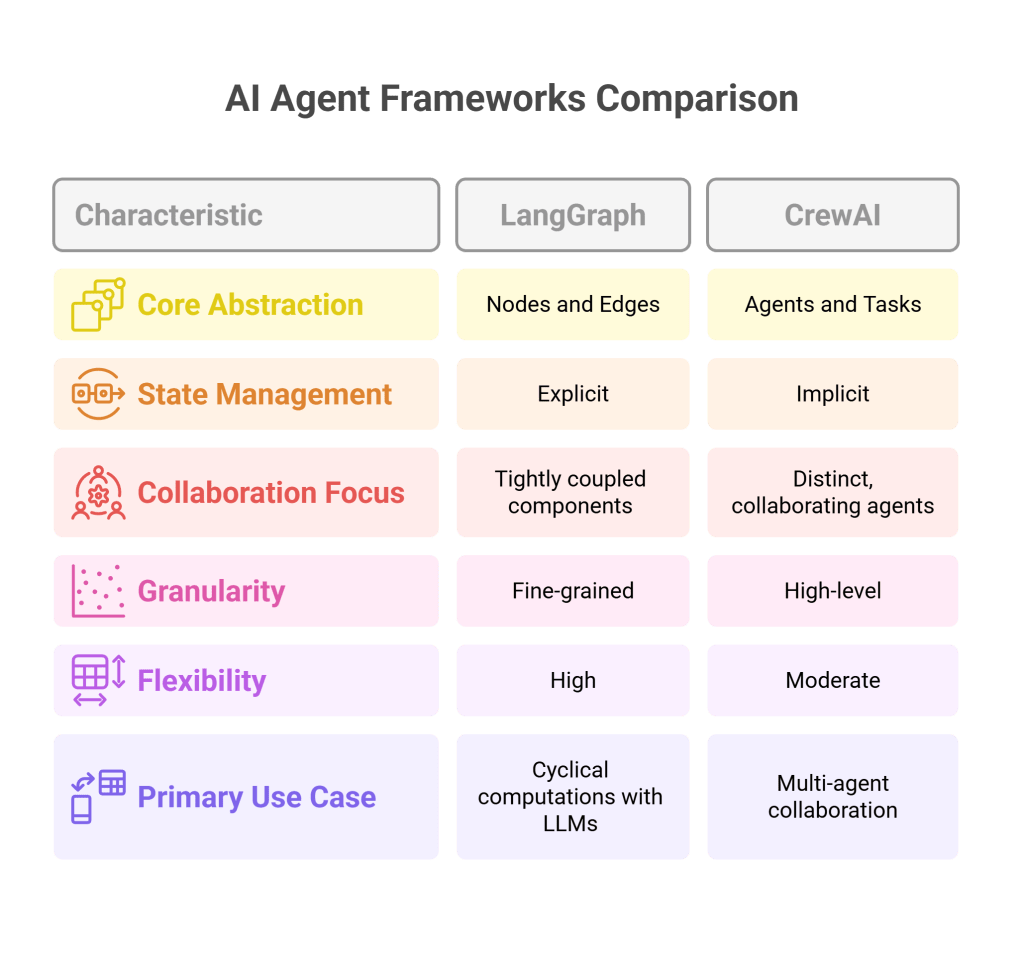
A. LangGraph (Preferred)
LangGraph is an extension of the popular LangChain library, designed for building stateful, multi-actor applications, including complex AI agents. It allows developers to define agent workflows as cyclical graphs.
Core Concepts of LangGraph:
- State: The central concept. The graph operates on a shared state object that is passed between nodes and updated by them. This state can include conversation history, intermediate results, scratchpad data, etc.
- Nodes: Represent units of computation (often Python functions or LangChain Runnables). A node takes the current state as input and returns an update to the state. Nodes can be LLM calls, tool executions, or custom logic.
- Edges: Define the flow of control between nodes.
- Conditional Edges: Based on the current state (e.g., the output of an LLM call), a conditional edge can route to different next nodes. This allows for dynamic, branching logic.
- Standard Edges: Always go from one node to another specific node.
- Cycles: LangGraph explicitly supports cycles, which are essential for iterative reasoning, re-prompting, tool use sequences, and human-in-the-loop interactions. This is a key differentiator from simpler, linear chains.
Why LangGraph for Complex Agents?
- Explicit State Management: Makes it easier to manage and reason about the agent’s internal state throughout complex interactions.
- Cyclical Computations: Naturally models agent behaviors like:
- LLM -> Tool -> LLM (ReAct-style loops)
- LLM -> Human Feedback -> LLM
- Iterative refinement of a plan or answer.
- Modularity: Encourages breaking down agent logic into smaller, manageable nodes.
- Visualization and Debugging: The graph structure can be visualized, aiding in understanding and debugging agent flow.
- Flexibility: Allows for building highly customized agent architectures.
Example Structure (Conceptual):
An agent that plans and executes tasks might have nodes for:
PLANNER_NODE: LLM call to break down a user request into a sequence of steps. Updates state with the plan.TOOL_EXECUTOR_NODE: Based on the current step in the plan, selects and executes a relevant tool. Updates state with tool output.RESPONSE_SYNTHESIZER_NODE: LLM call to synthesize a final response or report progress based on executed steps and tool outputs.CONDITIONAL_EDGE: AfterTOOL_EXECUTOR_NODE, decides whether to:- Go back to
TOOL_EXECUTOR_NODEif more steps in the plan. - Go to
RESPONSE_SYNTHESIZER_NODEif plan complete. - Go back to
PLANNER_NODEif replanning is needed (e.g., tool failed).
- Go back to
B. CrewAI
CrewAI is another framework for orchestrating role-playing, autonomous AI agents. It focuses on enabling agents to collaborate to achieve complex tasks.
Key Concepts of CrewAI:
- Agents: Define specialized agents with specific roles (e.g., “Researcher,” “Writer,” “QA Analyst”), goals, and backstories. Each agent is typically powered by an LLM.
- Tasks: Define the specific assignments for each agent. Tasks can have dependencies.
- Tools: Agents can be equipped with tools (similar to LangChain tools).
- Crews: A collection of agents that work together, following a defined process to accomplish a larger objective.
- Process: Defines how tasks are delegated and how agents collaborate (e.g., sequential, hierarchical).
Strengths of CrewAI:
- Multi-Agent Collaboration: Designed specifically for scenarios where multiple agents with different specializations need to work together.
- Role-Playing: The emphasis on roles and backstories can help in eliciting more specialized and focused behavior from LLMs.
- Simplified Abstraction: Provides a higher-level abstraction for defining collaborative agent workflows.
LangGraph vs. CrewAI:
- Granularity: LangGraph offers finer-grained control over the state and flow within a single (potentially very complex) agent or a system of tightly coupled components. CrewAI is more about orchestrating distinct, collaborating agents.
- Flexibility: LangGraph is generally more flexible for arbitrary graph structures and state manipulations.
- Focus: LangGraph is a general tool for cyclical computations with LLMs. CrewAI is specifically focused on the “crew of agents” metaphor.
They are not mutually exclusive; one could potentially use LangGraph to define the internal workings of a complex agent that then participates in a CrewAI setup.
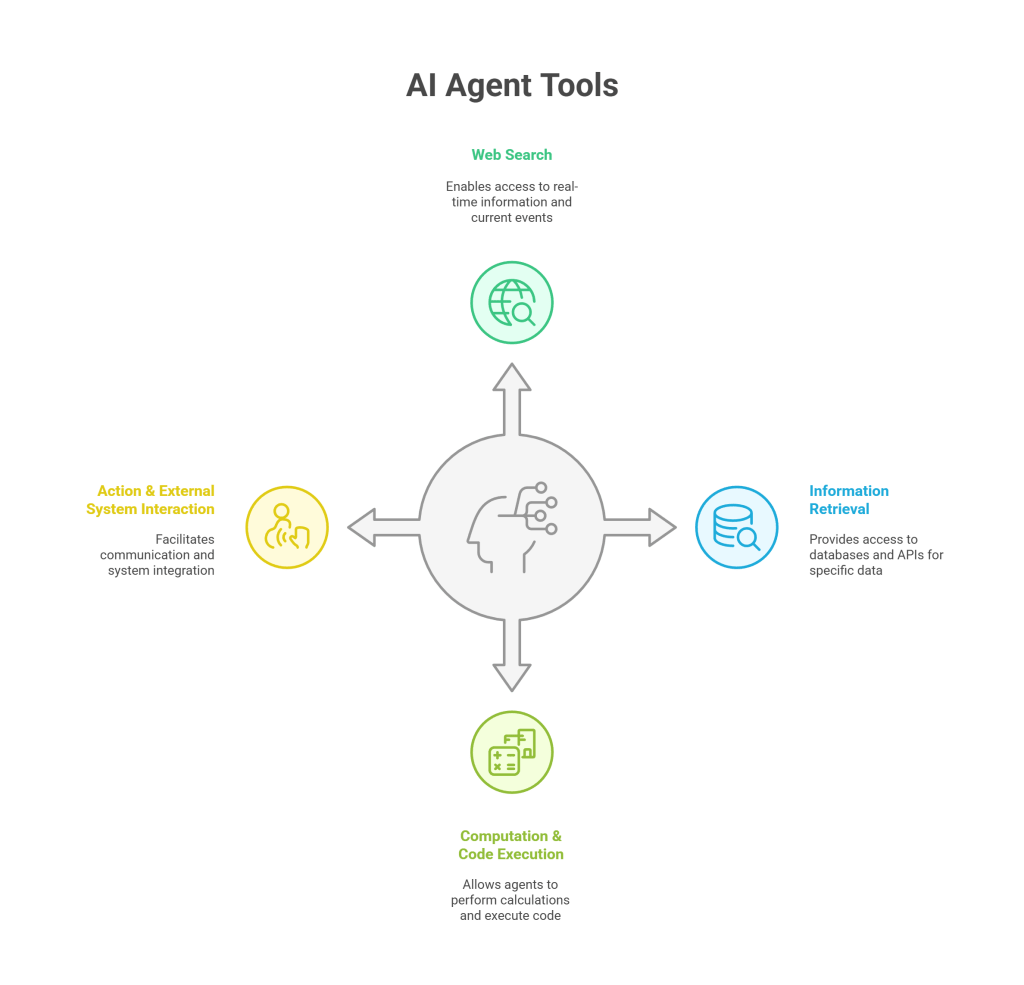
IV. AI Agent Tools: Extending Capabilities
For AI agents to be truly useful, they need to interact with the world beyond the LLM’s internal knowledge. Tools allow agents to access real-time information, perform calculations, execute code, and interact with other software systems.
A. Web Search
One of the most common and powerful tools for AI agents is the ability to search the web. This overcomes the LLM’s knowledge cutoff and allows it to access current events, specific facts, and a vast range of information.
How it Works:
- The agent determines it needs to perform a web search (based on the user query or its internal reasoning).
- It formulates a search query.
- It calls a web search tool, which is typically a wrapper around a search engine API.
- The tool executes the search and returns a list of search results (titles, snippets, URLs).
- Optionally, the agent (or the tool) might then “scrape” the content from one or more of the top result URLs to get more detailed information.
- This retrieved information is then passed back to the LLM as context to help generate the final answer.
Common Search APIs/Services:
- Google Custom Search JSON API: Allows programmatic access to Google Search.
- Bing Web Search API: Microsoft’s offering.
- SerpApi: Provides real-time, localized search results from various engines.
- Brave Search API: Privacy-focused search engine with an API.
- You.com API: Search engine with a focus on AI.
- Metaphor API (formerly Tavily): Designed for finding high-quality content by searching for links based on semantic similarity to a query, rather than just keywords. It can be very effective for RAG.
Considerations:
- Cost: Most search APIs have usage costs.
- Rate Limits: Be mindful of API rate limits.
- Quality of Results: The effectiveness of the search depends on the quality of the search query formulated by the agent and the relevance of the search engine’s results.
- Scraping: If scraping content from web pages, be respectful of
robots.txtand website terms of service. Use robust scraping libraries (e.g., BeautifulSoup, Scrapy).
B. Many Available Tools (The Ecosystem)
The range of tools an agent can use is virtually limitless and depends on its purpose. Agent frameworks like LangChain provide a rich ecosystem of pre-built tools and an easy way to define custom tools.
Categories of Tools:
- Information Retrieval:
- Web search (as above).
- Database query tools (SQL, NoSQL).
- API connectors for specific services (e.g., Wikipedia, weather APIs, stock market data).
- Vector store retrieval tools (for RAG).
- Computation & Code Execution:
- Python REPL/Code Interpreter: Allows the agent to write and execute Python code to perform calculations, data analysis, or other programmatic tasks. This is extremely powerful but requires careful sandboxing for security.
- Calculator: For basic arithmetic.
- Wolfram Alpha: For advanced mathematical computation, scientific knowledge, and data analysis.
- Action & External System Interaction:
- Email/Messaging Tools: Send emails or messages (e.g., Slack, Teams).
- Calendar Tools: Read or create calendar events.
- File System Tools: Read or write files (with appropriate permissions).
- Custom API Tools: Interact with any internal or third-party API relevant to the agent’s tasks (e.g., CRM, ERP, project management tools).
Defining Custom Tools:
Most frameworks allow you to define a custom tool by providing:
- A name for the tool.
- A clear description of what the tool does, what its inputs are, and what its outputs are. This description is crucial, as the LLM uses it to decide when and how to use the tool.
- The actual Python function that implements the tool’s logic.
- Optionally, a Pydantic model defining the input schema for the tool, which helps the LLM structure its requests correctly.
Example (Conceptual Custom Tool):
# In a LangChain-like setup
from langchain_core.tools import tool
from pydantic import BaseModel, Field
class JiraTicketInput(BaseModel):
project_key: str = Field(description="The JIRA project key, e.g., 'PROJ'.")
summary: str = Field(description="The summary or title of the JIRA ticket.")
description: str = Field(description="A detailed description of the issue for the JIRA ticket.")
@tool(args_schema=JiraTicketInput)
def create_jira_ticket(project_key: str, summary: str, description: str) -> str:
"""
Creates a new JIRA ticket in the specified project with the given summary and description.
Returns the ID of the newly created ticket or an error message.
"""
# ... actual JIRA API call logic here ...
# response = jira_client.create_issue(project=project_key, summary=summary, description=description)
# return f"Successfully created JIRA ticket: {response.key}"
return f"Simulated JIRA ticket creation for {project_key}: '{summary}'"
# The agent's LLM would see the tool name "create_jira_ticket" and its docstring.
# If it decides to use it, it would try to generate JSON matching JiraTicketInput.
V. Prompt Engineering: Guiding the Agent’s Mind
Prompt engineering is the art and science of designing effective prompts to elicit desired behaviors and outputs from LLMs. For AI agents, where the LLM is the core “brain,” prompt engineering is exceptionally critical.
Why “Very Important!”?
- Controls Behavior: The prompt dictates the agent’s persona, task, instructions, constraints, and how it should use tools or retrieved information.
- Maximizes Performance: Well-crafted prompts can significantly improve the accuracy, relevance, and coherence of the agent’s responses and actions.
- Reduces Errors and Hallucinations: Clear, specific prompts can help mitigate unwanted LLM behaviors.
- Enables Complex Reasoning: Techniques like Chain-of-Thought prompting guide the LLM to “think step-by-step,” improving its ability to handle complex problems.
Key Prompt Engineering Techniques for Agents:
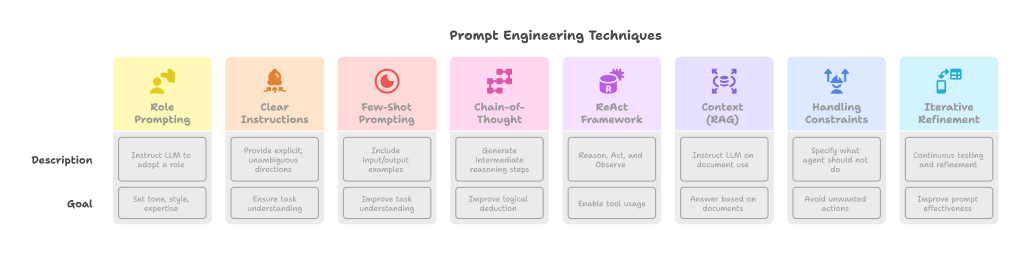
- Role Prompting / Persona:
- Instruct the LLM to adopt a specific role (e.g., “You are a helpful AI assistant specializing in financial advice,” “You are a meticulous software engineer debugging code”).
- This helps set the tone, style, and domain expertise of the agent.
- Clear Instructions:
- Provide explicit, unambiguous instructions for the task at hand.
- Break down complex tasks into smaller steps if necessary.
- Specify output formats if required (e.g., “Provide your answer in JSON format with keys ‘summary’ and ‘action_items'”).
- Few-Shot Prompting:
- Include a few examples (input/output pairs) of the desired behavior in the prompt. This helps the LLM understand the task and expected output format better than zero-shot (no examples) prompting.
- Chain-of-Thought (CoT) Prompting:
- Encourage the LLM to generate a series of intermediate reasoning steps before arriving at the final answer.
- Often triggered by adding phrases like “Let’s think step by step” or by providing few-shot examples that include reasoning steps.
- Improves performance on tasks requiring logical deduction or multi-step problem-solving.
- ReAct (Reason and Act) Framework:
- A powerful prompting pattern for agents that need to use tools.
- The LLM iterates through a cycle of:
- Thought: Reasons about the current situation and what to do next.
- Action: Decides to use a specific tool with certain inputs.
- Observation: Receives the output from the tool.
- This loop continues until the LLM believes it has enough information to answer the user’s query.
- The prompt needs to provide clear instructions on how to format Thoughts, Actions (tool name and input), and how to interpret Observations.
- Providing Context (RAG Integration):
- When using RAG, the prompt must instruct the LLM on how to use the retrieved documents (e.g., “Answer the user’s question based only on the provided context documents. If the answer is not in the documents, say you don’t know.”).
- Handling Constraints and Negative Constraints:
- Specify what the agent should not do (e.g., “Do not provide medical advice,” “Do not use offensive language”).
- Iterative Refinement:
- Prompt engineering is rarely a one-shot process. It involves continuous testing, analyzing LLM outputs, and refining the prompt based on observed behavior.
- Use evaluation sets to measure the impact of prompt changes.
Example Snippet (Conceptual ReAct-style prompt element):
You are a helpful assistant. To answer questions, you can use the following tools:
- WebSearch[query]: Searches the web for the given query.
- Calculator[expression]: Calculates the result of a mathematical expression.
Use the following format for your thought process and actions:
Thought: [Your reasoning and plan]
Action: [ToolName][ToolInput]
Observation: [Result from the tool]
... (this Thought/Action/Observation can repeat N times)
Thought: I now have enough information to answer the user's question.
Final Answer: [Your final answer to the user]
User Question: What was the weather like in London yesterday, and what is 25*3?
VI. AI Agent Monitoring: Keeping an Eye on Performance
Once an AI agent is deployed, continuous monitoring is essential to ensure it’s performing as expected, identify issues, and gather insights for improvement. Traditional software monitoring practices apply, but there are also LLM-specific considerations.
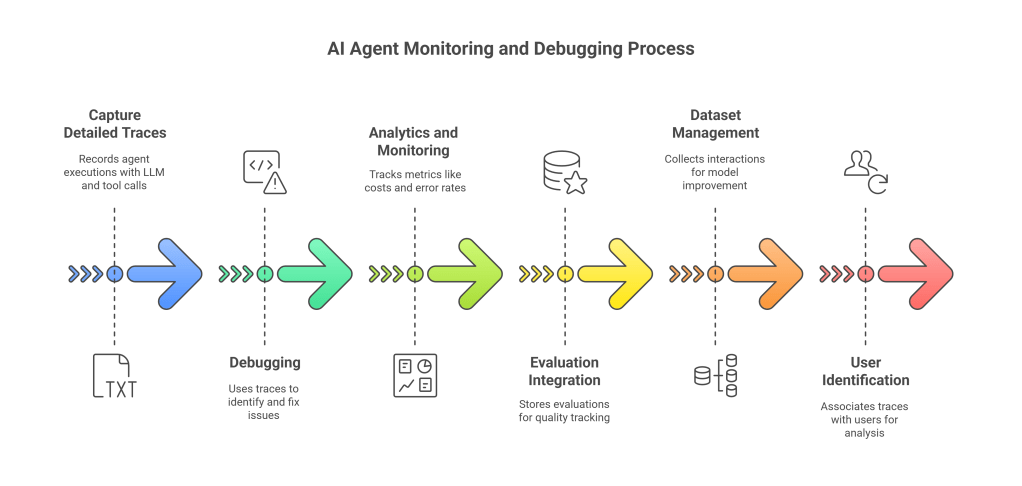
A. Langfuse
Langfuse is an open-source observability and analytics platform specifically designed for LLM applications, including AI agents.
Key Features and Benefits:
- Tracing: Captures detailed traces of agent executions, including:
- LLM calls (prompts, completions, model parameters, token usage, latency).
- Tool calls (inputs, outputs).
- Retrieval steps (queries, retrieved documents).
- Internal state changes (if using frameworks like LangGraph).
- This provides a granular view of how the agent processed a request, which is invaluable for debugging.
- Debugging: The detailed traces make it much easier to pinpoint why an agent produced a particular output or failed.
- Analytics and Monitoring:
- Track key metrics like LLM costs, latency, token usage per interaction.
- Monitor error rates and identify common failure patterns.
- Analyze user feedback (if collected) alongside traces.
- Evaluation Integration:
- Store human or model-based scores/evaluations for specific traces.
- Helps track quality over time and compare different versions of prompts or agent configurations.
- Dataset Management:
- Collect and manage interesting or problematic interactions to create datasets for fine-tuning models or improving prompts.
- User Identification:
- Associate traces with specific users to understand usage patterns and debug user-specific issues.
How it Works (Generally):
Langfuse typically provides SDKs (e.g., for Python) that you integrate into your agent’s code. These SDKs automatically capture relevant data or provide functions to explicitly log events, LLM calls, etc., to the Langfuse backend (which can be self-hosted or cloud-based).
B. Comet (Comet ML)
Comet ML is a broader MLOps platform for experiment tracking, model registry, and production model monitoring. While not exclusively for LLMs, its capabilities are highly relevant for AI agent development and operation. (The note “Opik” might be a typo or a specific internal project name; Comet ML is the widely known platform).
Relevant Comet ML Features for AI Agents:
- Experiment Tracking:
- Log prompt versions, model parameters, evaluation metrics, and agent configurations during development.
- Compare the performance of different agent designs or prompt strategies.
- Version datasets used for RAG or evaluation.
- Prompt Management:
- Comet has features for managing and versioning prompts (Prompt Playground).
- Track the history of prompt changes and link them to experiment results.
- Model Registry:
- If you are fine-tuning your own LLMs or other ML models used by the agent (e.g., re-rankers), Comet can manage these model versions.
- Production Monitoring:
- Monitor the performance of deployed agents in real-time.
- Track data drift (changes in input data distribution) and concept drift (changes in the relationship between inputs and outputs).
- Log predictions, operational metrics (latency, throughput, error rates), and custom metrics.
- Set up alerts for performance degradation or anomalies.
- Custom Dashboards and Reporting:
- Visualize key metrics and create reports on agent performance and usage.
Langfuse vs. Comet ML:
- Specialization: Langfuse is highly specialized for LLM observability, offering deep tracing capabilities tailored to LLM call chains and agent interactions.
- Scope: Comet ML is a more general MLOps platform covering the broader ML lifecycle, including traditional ML models. Its LLM features are an extension of its core platform.
- Complementary: They can be complementary. Langfuse might be used for detailed debugging and tracing of LLM interactions within the agent, while Comet ML could be used for higher-level experiment tracking, overall production monitoring, and managing any custom ML models the agent uses. Some teams might choose one over the other based on their primary needs and existing MLOps stack.
VII. Deployment: Bringing Agents to Life
Developing an AI agent is one thing; deploying it reliably and scalably is another. This involves packaging the agent, provisioning infrastructure, and setting up automation for updates.
A. AWS ECS (Elastic Container Service)
AWS ECS is a fully managed container orchestration service that makes it easy to deploy, manage, and scale containerized applications. It’s a popular choice for deploying AI agents.

Why Containers (e.g., Docker)?
- Consistency: Containers package the agent’s code, Python environment, dependencies, and configurations into a single, portable unit. This ensures it runs the same way in development, testing, and production.
- Isolation: Containers provide process isolation.
- Scalability: Easy to scale by running multiple instances of the container.
How ECS Works:
- Dockerize your Agent: Create a
Dockerfilethat defines how to build an image of your agent (e.g., based on a Python image, copying your code, installing dependencies). - Push to a Registry: Push the Docker image to a container registry (e.g., Amazon ECR – Elastic Container Registry, Docker Hub).
- Define a Task Definition: In ECS, a task definition is a blueprint for your application. It specifies the Docker image to use, CPU/memory requirements, environment variables, port mappings, logging configuration, etc.
- Create a Service: An ECS service maintains a specified number of instances of your task definition running. It can integrate with load balancers to distribute traffic and handle auto-scaling.
- Choose a Launch Type:
- Fargate: Serverless compute for containers. AWS manages the underlying infrastructure. You just define your application and resource needs. Simpler to manage.
- EC2: You manage a cluster of EC2 instances that ECS uses to run your containers. More control over the underlying instances but more operational overhead.
Benefits of ECS for AI Agents:
- Scalability: Easily scale the number of agent instances up or down based on demand.
- High Availability: Distribute tasks across multiple Availability Zones.
- Integration with AWS Ecosystem: Seamlessly integrates with other AWS services like ECR, CloudWatch (for logging/monitoring), IAM (for security), Application Load Balancers, VPCs.
- Managed Service: Reduces operational burden compared to managing your own orchestration (like Kubernetes, though EKS is an option if Kubernetes is preferred).
Alternatives:
- AWS Lambda: For stateless, event-driven agents or parts of agents with short execution times. Can be very cost-effective if traffic is sporadic. However, LLM cold starts and duration limits can be a challenge.
- AWS EKS (Elastic Kubernetes Service): If you prefer or already use Kubernetes.
- Other Cloud Providers: Google Cloud Run / GKE, Azure Container Instances / AKS.
- On-Premise/Self-Hosted: Using Docker Swarm or Kubernetes on your own infrastructure.
B. CI/CD (Continuous Integration / Continuous Deployment)
CI/CD is a set of practices and tools that automate the process of building, testing, and deploying software updates. It’s crucial for maintaining agility and reliability when developing AI agents.
Continuous Integration (CI):
- Developers frequently merge their code changes into a central repository (e.g., Git).
- Each merge triggers an automated build process.
- Automated tests (unit tests, integration tests, prompt evaluations) are run.
- Goals: Detect integration issues early, ensure code quality, provide rapid feedback.
Continuous Deployment (CD) / Continuous Delivery:
- Continuous Delivery: After CI passes, the application is automatically packaged and prepared for release, potentially deploying to a staging environment. A manual approval might be needed for production deployment.
- Continuous Deployment: Every change that passes all automated tests is automatically deployed to production.
- Goals: Automate the release process, enable frequent and reliable deployments, reduce manual effort and risk.
CI/CD Pipeline for an AI Agent:
A typical pipeline might look like this:
- Code Commit: Developer pushes changes (e.g., new feature, prompt update, bug fix) to a Git repository (e.g., GitHub, GitLab, AWS CodeCommit).
- Trigger: The commit triggers the CI/CD pipeline (e.g., using Jenkins, GitLab CI/CD, GitHub Actions, AWS CodePipeline).
- Build:
- Fetch code.
- Build the Docker image for the agent.
- Test:
- Run unit tests.
- Run integration tests (may involve spinning up dependent services like a test vector DB).
- Run RAG evaluation tests.
- Run prompt evaluation tests against a benchmark dataset.
- Push Artifacts:
- If tests pass, push the Docker image to a container registry (e.g., ECR).
- Deploy to Staging:
- Automatically deploy the new version to a staging environment that mirrors production.
- Run further automated tests (e.g., smoke tests, end-to-end tests) in staging.
- Manual Approval (Optional for Continuous Delivery):
- A QA team or product owner might review the staging deployment before approving production release.
- Deploy to Production:
- Automatically deploy to production using strategies like blue/green deployment or canary releases to minimize risk.
- Monitor:
- Continuously monitor the production deployment for errors or performance degradation.
Benefits for AI Agent Development:
- Faster Iteration: Quickly get new agent features, prompt improvements, and bug fixes into users’ hands.
- Improved Quality: Automated testing catches issues early.
- Reliability: Standardized and automated deployment process reduces human error.
- Focus on Development: Frees up developers from manual deployment tasks.
VIII. LLMs: The Core Engine – Performance vs. Costs & Token Estimation
The choice and usage of Large Language Models are central to AI agent design and operation. This involves a careful balancing act between capabilities, speed, and cost.
A. Performance vs. Costs
Different LLMs offer varying levels of performance (reasoning ability, knowledge, creativity, instruction following) at different price points.
Factors to Consider:
- Model Capability:
- State-of-the-Art (SOTA) Models: (e.g., OpenAI’s GPT-4 series, Anthropic’s Claude 3 Opus, Google’s Gemini Advanced/Ultra)
- Pros: Highest performance on complex reasoning, nuanced understanding, creative generation. Best for tasks requiring deep understanding or high-quality output.
- Cons: Most expensive per token, can have higher latency.
- Mid-Tier Models: (e.g., GPT-3.5-Turbo, Claude 3 Sonnet/Haiku, Gemini Pro, open-source models like Llama 3 70B)
- Pros: Good balance of performance and cost. Often much faster than SOTA models. Suitable for many agent tasks.
- Cons: May not handle extremely complex or nuanced tasks as well as SOTA models.
- Smaller/Specialized Models: (e.g., Llama 3 8B, Mistral 7B, Phi-3, fine-tuned models)
- Pros: Cheapest, fastest latency. Can be very effective for simpler, well-defined tasks (e.g., classification, simple Q&A, tool routing if prompts are well-designed). Can be fine-tuned for specific domains.
- Cons: Limited reasoning capabilities, smaller context windows.
- State-of-the-Art (SOTA) Models: (e.g., OpenAI’s GPT-4 series, Anthropic’s Claude 3 Opus, Google’s Gemini Advanced/Ultra)
- Latency:
- How quickly does the model return a response? High latency can lead to a poor user experience for interactive agents. Smaller models are generally faster.
- Streaming responses can improve perceived latency for longer generations.
- Context Window Size:
- The maximum number of tokens (input prompt + generated output) the model can handle. Larger context windows allow for more information (e.g., longer conversation history, more RAG documents) to be processed at once, but often come at a higher cost or slower speed.
- Cost Structure:
- Typically priced per 1,000 tokens (input and output tokens may be priced differently).
- Some models might have additional costs for features like fine-tuning or provisioned throughput.
- Open-Source vs. Proprietary Models:
- Proprietary (API-based):
- Pros: Easy to access, often SOTA performance, managed infrastructure.
- Cons: Ongoing API costs, data privacy concerns (data sent to third-party), less control/customization.
- Open-Source (Self-hosted or via platforms):
- Pros: More control, potential for fine-tuning, can be cheaper for very high volume if you manage infrastructure efficiently, data stays within your environment.
- Cons: Requires infrastructure and expertise to host and manage, performance may vary, keeping up with SOTA can be challenging.
- Proprietary (API-based):
Strategy for AI Agents:
- Task-Specific Model Selection: Not all parts of an agent need the most powerful (and expensive) model. Consider using a “router” or “orchestrator” LLM that is cheaper/faster to decide which specialized LLM (or tool) to use for a particular sub-task. For example, a simple classification task might use a small model, while complex reasoning might use a SOTA model.
- Caching: Cache LLM responses for identical (or very similar) inputs to reduce redundant calls and costs.
- Prompt Optimization: Shorter, more efficient prompts use fewer input tokens.
- Output Length Control: Limit the maximum number of tokens the LLM can generate if appropriate for the task.
B. Token Estimation
Understanding and estimating token usage is crucial for managing costs and staying within model context window limits.
What is a Token?
LLMs don’t see text as characters or words directly, but as “tokens.” A token can be a whole word, part of a word, punctuation, or a space. The exact tokenization scheme varies between models. Generally, for English text, 1 token is approximately 0.75 words.
Why Estimate Tokens?
- Cost Control: LLM API costs are directly tied to the number of input and output tokens.
- Context Window Management: Prompts (including instructions, history, RAG context) plus the expected generated output must fit within the model’s context window. Exceeding it will result in errors.
- Performance: Very long prompts can sometimes lead to increased latency or reduced attention to earlier parts of the prompt.
How to Estimate/Count Tokens:
- Tokenizer Libraries: Most LLM providers offer tokenizer libraries or endpoints.
- OpenAI:
tiktokenlibrary. - Hugging Face Transformers: Provides tokenizers for many open-source models.
- OpenAI:
- Rule of Thumb: For quick estimation, use the ~0.75 words/token heuristic for English, but always use the official tokenizer for accurate counts before sending to the API.
- API Responses: Many LLM APIs return token usage information in their responses. Log this data for monitoring.
Strategies for Managing Token Count:
- Summarization: Summarize long conversation histories or lengthy retrieved documents before including them in the prompt.
- Selective Context: Don’t just stuff all available information into the prompt. Develop strategies to select the most relevant pieces of context (e.g., more sophisticated RAG re-ranking, windowed history).
- Prompt Compression Techniques: (Advanced) Explore techniques that aim to convey the same information in fewer tokens.
- Output Length Limits: Use parameters like
max_tokensto cap the length of the LLM’s generation.
Example Scenario:
An agent with a RAG system needs to answer a user query.
- User Query: 50 tokens
- System Prompt (instructions, persona): 200 tokens
- Conversation History (summarized): 300 tokens
- Retrieved RAG Chunks (3 chunks, 200 tokens each): 600 tokens
- Total Input Tokens: 50 + 200 + 300 + 600 = 1150 tokensIf the LLM has a 4096-token context window, this leaves 4096 – 1150 = 2946 tokens for the generated output. If the agent is expected to generate a long report, this might be sufficient. If the context window is only 2048 tokens, the input is too long, and strategies to reduce it would be needed (e.g., fewer RAG chunks, shorter history).
IX. Conclusion: The Dawn of Agentic AI
The transition from data science to AI agent development represents a significant leap towards creating more autonomous, interactive, and capable AI systems. It builds upon the analytical and modeling skills of data scientists but demands a broader T-shaped profile encompassing robust software engineering practices (Python, APIs, testing, deployment), a nuanced understanding of LLM behavior (prompt engineering, RAG), and the ability to orchestrate complex workflows using modern agent frameworks.
The journey involves mastering asynchronous programming for responsiveness, leveraging Pydantic for data integrity, building performant APIs with FastAPI, and ensuring reliability through comprehensive logging, monitoring (with tools like Langfuse and Comet ML), and CI/CD pipelines. Grounding agents in factual, up-to-date knowledge through sophisticated RAG techniques—from data collection and chunking to hybrid retrieval and vector databases—is paramount. Frameworks like LangGraph and CrewAI provide the scaffolding to build complex, stateful, and collaborative agents, while a rich ecosystem of tools extends their capabilities into the digital and real world.
Ultimately, the success of an AI agent hinges on the careful orchestration of all these elements, with the LLM at its core, guided by meticulous prompt engineering and a constant awareness of the trade-offs between performance, cost, and token limitations. As this field continues its rapid evolution, the data scientists who embrace these new skills and technologies will be at the forefront of building the next generation of intelligent applications, transforming industries and reshaping how we interact with AI. The path is one of continuous learning and adaptation, but the potential to create truly impactful AI agents makes it an incredibly exciting and rewarding endeavor.
Discover more from SkillWisor
Subscribe to get the latest posts sent to your email.
