
Table of Contents
- Introduction to RAG (Retrieval Augmented Generation)
- What is RAG?
- Why is RAG Needed?
- Basic RAG Architecture
- Benefits of RAG
- Limitations of Traditional RAG
- The Semantic Bottleneck
- Ignoring Explicit Relationships
- Challenges in Multi-Hop Reasoning
- Contextual Gaps with Interconnected Data
- The Power of Connections: Graph Databases and Knowledge Graphs
- Understanding Graph Databases
- The Rise of Knowledge Graphs
- Why Graphs Excel at Representing Relationships
- Illustrative Graph Example: A Corporate Knowledge Graph
- Enter GraphRAG: The Next Evolution
- Defining GraphRAG
- Bridging the Gap: Graphs and LLMs
- Core Principle: Relationship-Aware Retrieval
- High-Level Architecture of GraphRAG
- Key Components and Mechanisms of GraphRAG
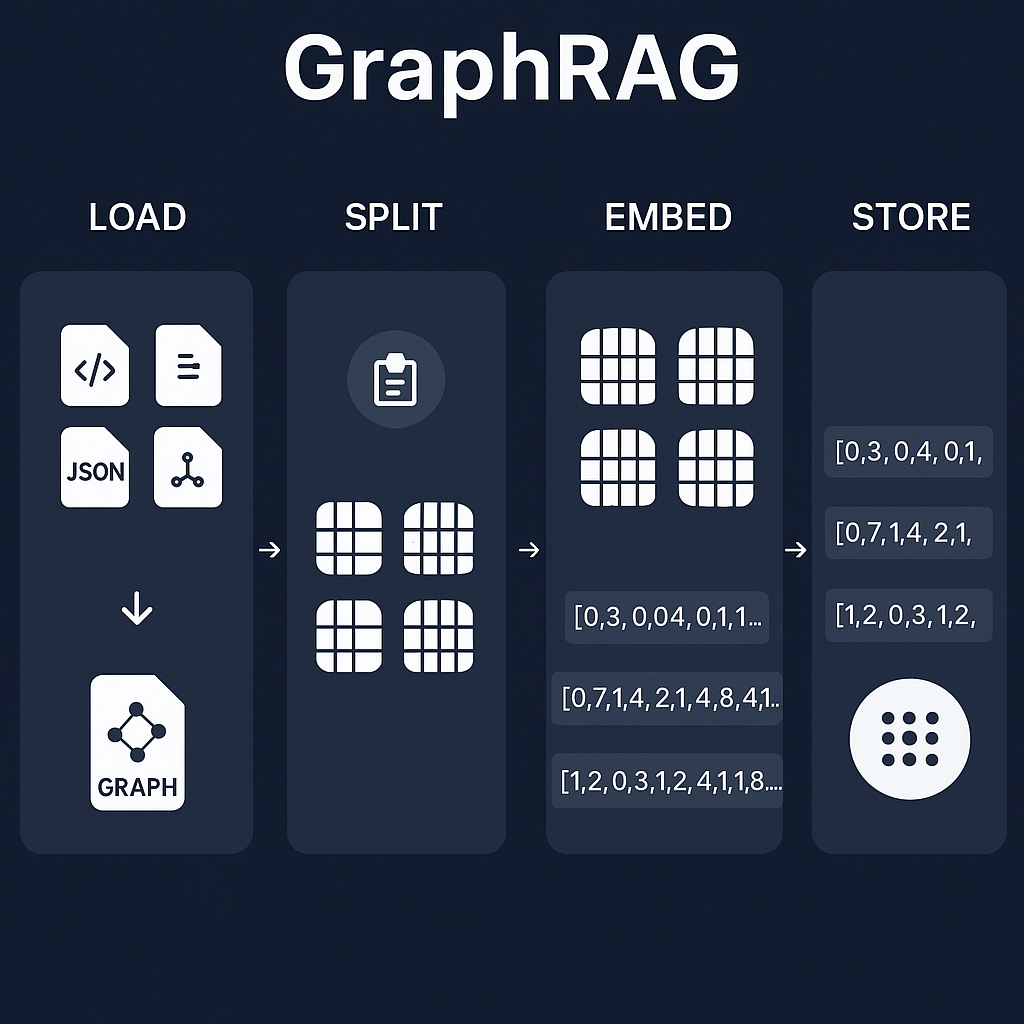
- Graph Construction and Ingestion
- Data Representation: Embeddings in Graphs
- Visual Table: Understanding Embeddings in GraphRAG
- Vector Storage and Indexing for Hybrid Power
- Visual Table: Vector Storage Options in GraphRAG
- Graph-Powered Retrieval Strategies
- Example Graph Queries
- Context Augmentation and Prompt Engineering with Graph Data
- LLM Generation: Synthesizing Knowledge
- How GraphRAG Overcomes Traditional RAG Limitations
- Superior Contextual Understanding
- Enabling Complex Multi-Hop Reasoning
- Reducing Hallucinations with Factual Grounding
- Answering Intricate, Relationship-Driven Queries
- Conceptual Steps to Building a GraphRAG System
- Phase 1: Data Foundation
- Phase 2: Knowledge Graph Construction
- Phase 3: Embedding and Indexing
- Phase 4: Retrieval Logic Development
- Phase 5: LLM Integration and Prompting
- Phase 6: Evaluation and Iteration
- Transformative Use Cases and Applications of GraphRAG
- Advanced Question Answering over Complex Archives
- Hyper-Personalized Recommendation Engines
- Accelerating Scientific Discovery (e.g., Drug Development)
- Sophisticated Fraud Detection and Anomaly Identification
- Intelligent Supply Chain Optimization and Risk Analysis
- Comprehensive Customer 360 and Relationship Intelligence
- Navigating the Frontiers: Challenges and Future Directions
- Scalability and Performance
- Complexity of Knowledge Graph Creation and Maintenance
- Handling Dynamic and Evolving Data
- Standardizing Evaluation Metrics
- Enhancing Explainability and Interpretability
- Optimizing Hybrid Retrieval Models
- Integrating Multimodal Knowledge
- GraphRAG in Context: Comparisons with Other RAG Approaches
- GraphRAG vs. Standard Vector RAG
- GraphRAG vs. RAG over Structured Data (e.g., SQL RAG)
- The GraphRAG Toolkit: Essential Technologies
- Graph Databases
- Vector Databases/Indexes
- LLM Orchestration Frameworks
- Natural Language Processing (NLP) Libraries
- Graph Machine Learning Libraries
- Conclusion: The Dawn of Relationship-Aware AI
- The Symbiotic Power of Graphs and LLMs
- Pioneering the Future of Information Access
1. Introduction to RAG (Retrieval Augmented Generation)
Large Language Models (LLMs) have demonstrated remarkable capabilities in understanding and generating human-like text. However, they are not without limitations. Their knowledge is typically frozen at the time of their last training run, making them unaware of events or information that have emerged since. Furthermore, they can sometimes “hallucinate” or generate plausible but incorrect information. Retrieval Augmented Generation (RAG) has emerged as a powerful paradigm to address these shortcomings.
What is RAG?
Retrieval Augmented Generation (RAG) is an architectural approach that enhances the capabilities of LLMs by dynamically integrating external knowledge before generating a response. Instead of relying solely on its pre-trained (parametric) knowledge, an LLM in a RAG system first retrieves relevant information from an external knowledge source and then uses this information to inform and ground its output.
Why is RAG Needed?
The necessity for RAG stems from several inherent limitations of standalone LLMs:

- Knowledge Cutoffs: LLMs have no knowledge of the world beyond their last training date. RAG allows them to access and utilize up-to-date information.
- Hallucinations: LLMs can generate factually incorrect or nonsensical statements. By grounding responses in retrieved, verifiable information, RAG significantly reduces the likelihood of hallucinations.
- Lack of Domain-Specificity: General-purpose LLMs may lack deep knowledge in specialized domains. RAG enables the integration of domain-specific knowledge bases, tailoring responses to particular contexts (e.g., medical, legal, financial).
- Transparency and Verifiability: RAG systems can often cite the sources of information used in their responses, providing a degree of transparency and allowing users to verify the information.
- Personalization: RAG can retrieve information specific to a user or context, leading to more personalized and relevant interactions.
Basic RAG Architecture
A typical RAG system comprises two core components:
- Retriever: This component is responsible for finding and fetching relevant information from an external knowledge source in response to a user query. The knowledge source is often a collection of documents, which are typically chunked, embedded (converted into numerical vector representations), and stored in a vector database for efficient similarity search. When a query comes in, it’s also embedded, and the retriever searches the vector database for chunks whose embeddings are most similar to the query embedding.
- Generator: This is typically an LLM. It receives the original user query along with the relevant context retrieved by the retriever. The LLM then uses this combined input to generate a comprehensive, informed, and contextually grounded response.
The process generally flows as follows:
User Query -> Embed Query -> Retriever (Search Vector DB) -> Retrieve Relevant Chunks -> Augment Prompt (Query + Chunks) -> Generator (LLM) -> Final Response.
Benefits of RAG
The adoption of RAG offers numerous advantages:
- Improved Accuracy: Responses are grounded in factual, retrieved data, leading to more accurate and reliable outputs.
- Access to Current Information: LLMs can provide information beyond their training data.
- Reduced Hallucinations: External grounding minimizes the chances of the LLM inventing information.
- Enhanced Trust and Transparency: Source attribution (when implemented) allows users to verify information.
- Cost-Effectiveness: Fine-tuning an LLM for every new piece of information or domain can be prohibitively expensive. RAG offers a more economical way to incorporate new knowledge by simply updating the external knowledge base.
- Customization and Control: Developers can curate and control the external knowledge sources, ensuring the LLM uses information aligned with specific requirements or organizational standards.
While RAG represents a significant step forward, the traditional approach, primarily relying on semantic similarity search over unstructured text chunks, has its own set of limitations, particularly when dealing with highly interconnected and complex information. This is where GraphRAG enters the picture.
2. Limitations of Traditional RAG
Traditional RAG, while transformative, often relies on a relatively simple model of knowledge: a collection of independent text chunks. The primary retrieval mechanism is semantic similarity, typically achieved by comparing the vector embedding of a query with the vector embeddings of these chunks. This approach, though effective for many use cases, encounters difficulties when the underlying knowledge is rich in relationships and requires nuanced understanding beyond mere topical relevance.

The Semantic Bottleneck
Vector-based semantic search excels at finding documents or passages that are “about” the same topics as the query. However, it can struggle with queries that require understanding the nature of relationships between entities or concepts. For example, a query like “What is the impact of Company A’s acquisition of Company B on Company C’s market share?” involves multiple entities and specific relationships (acquisition, market impact) that might not be adequately captured by simply retrieving chunks that mention Companies A, B, and C individually. The semantic similarity might surface documents discussing each company, but not necessarily the intricate causal or relational links between them.
Ignoring Explicit Relationships
Unstructured text contains a wealth of information, but the relationships between entities are often implicit. Traditional RAG systems, by chunking documents, can break these relational links or fail to prioritize them during retrieval. A document might describe a complex process or a series of interconnected events, but if the relevant pieces of information are scattered across different chunks, the LLM might not receive a coherent, connected context. The system might retrieve facts about entities but miss the crucial connections between them.
Challenges in Multi-Hop Reasoning
Many real-world questions require “multi-hop” reasoning – connecting disparate pieces of information through a series of intermediate relationships. For instance, answering “Which researchers collaborated with scientists who later won a Nobel Prize in Physics?” requires:
- Identifying Nobel laureates in Physics.
- Finding their collaborators.
- Identifying researchers who worked with those collaborators.
Traditional RAG might retrieve documents about Nobel laureates or various researchers, but piecing together this multi-step chain of connections from isolated text chunks is challenging for the retriever and places a heavy burden on the LLM to infer these links. The retrieved context might be noisy or incomplete for such complex inferential tasks.
Contextual Gaps with Interconnected Data
Consider knowledge domains like supply chains, organizational structures, regulatory frameworks, or biological pathways. These are inherently graph-like, defined by entities and their explicit, often typed, relationships. Traditional RAG, by flattening this structured information into text chunks, loses much of this relational richness. It might retrieve a component of a supply chain but fail to provide its upstream suppliers or downstream distributors in a connected manner. This can lead to answers that are factually correct at a superficial level but lack the depth and comprehensive understanding that comes from appreciating the interconnectedness of the data.
These limitations highlight the need for a RAG approach that can natively understand and leverage explicit relationships within data. This is precisely the gap that graph databases and knowledge graphs, and subsequently GraphRAG, aim to fill.
3. The Power of Connections: Graph Databases and Knowledge Graphs
To overcome the limitations of traditional RAG, we need a way to represent and query data that inherently captures relationships. This is where graph databases and knowledge graphs shine. They provide a powerful and intuitive paradigm for modeling, storing, and retrieving interconnected information.
Understanding Graph Databases
A graph database is a type of NoSQL database that uses graph structures for semantic queries with nodes, edges, and properties to represent and store data.
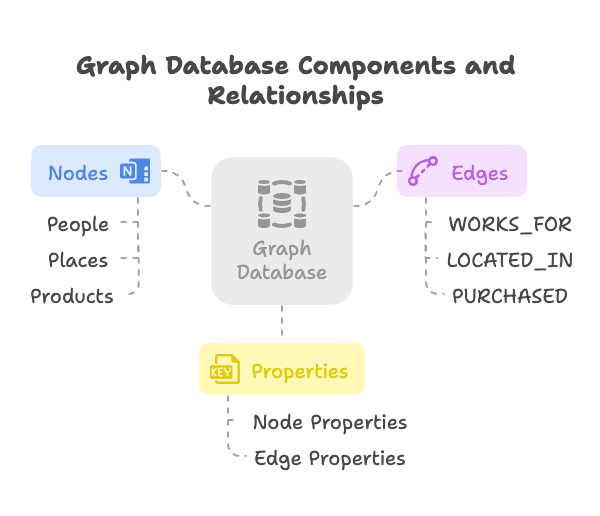
- Nodes (or Vertices): Represent entities or objects, such as people, places, products, concepts, or events. Nodes can have properties (key-value pairs) that describe their attributes (e.g., a
Personnode might have properties likename,age,occupation). - Edges (or Relationships): Represent connections or relationships between nodes. Edges are a key feature of graph databases, as they explicitly define how nodes are related. Edges are typically directed (pointing from one node to another), have a type (e.g.,
WORKS_FOR,LOCATED_IN,PURCHASED), and can also have properties (e.g., aPURCHASEDedge might have adateproperty). - Properties: Key-value pairs attached to nodes and edges, providing detailed attributes and metadata.
Unlike relational databases that store data in tables with predefined schemas and rely on joins (which can be computationally expensive for complex relationships), graph databases store connections alongside the data. This makes traversing relationships incredibly fast and efficient, especially for queries involving multiple levels of connections (multi-hop queries).
The Rise of Knowledge Graphs
A Knowledge Graph (KG) is an evolution of the graph database concept, focused on creating an interconnected web of knowledge. It’s a way of representing real-world entities, facts, and their relationships in a structured, graph-based format. KGs aim to capture not just data, but also the semantic meaning and context of that data.
Key characteristics of knowledge graphs include:

- Schema/Ontology: Often, KGs employ a schema or ontology that defines the types of entities (e.g.,
Person,Organization,Product) and the types of relationships (e.g.,worksFor,manufactures,isLocatedIn) that can exist in the graph. This provides a formal structure and shared understanding of the data. - Rich Relationships: KGs emphasize capturing diverse and meaningful relationships, going beyond simple links to include hierarchical, causal, temporal, and spatial connections.
- Inference Capabilities: Some KGs can infer new knowledge based on existing facts and defined rules or axioms (e.g., if A is a subclass of B, and X is an instance of A, then X is also an instance of B).
- Integration of Diverse Data: KGs are adept at integrating data from various sources, both structured (like databases) and unstructured (like text documents), into a unified representation.
Knowledge graphs are increasingly used by organizations to break down data silos, create a holistic view of their information assets, and power intelligent applications.
Why Graphs Excel at Representing Relationships
The inherent structure of graphs makes them exceptionally well-suited for representing and querying complex relationships:
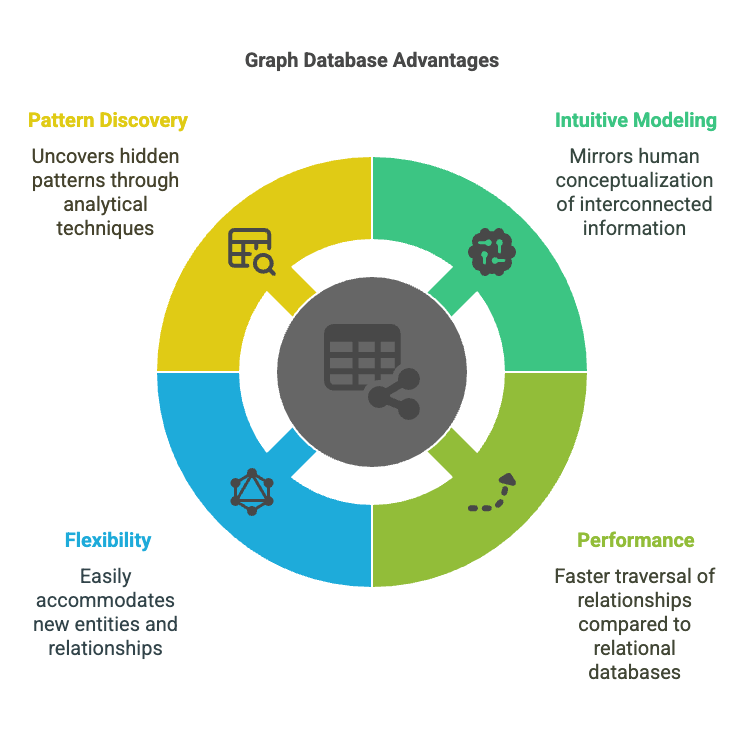
- Intuitive Modeling: The node-edge paradigm closely mirrors how humans conceptualize interconnected information.
- Performance for Connected Data: Traversing relationships is a fundamental operation in graph databases, making them significantly faster than relational databases for queries that follow connections (e.g., “find all friends of friends”).
- Flexibility: Graph schemas can be more flexible and evolve more easily than rigid relational schemas, accommodating new types of entities and relationships as understanding grows.
- Discovery of Patterns: Graph structures allow for powerful analytical techniques like pathfinding, centrality analysis (identifying important nodes), and community detection (finding clusters of related nodes), which can uncover hidden patterns and insights.
Illustrative Graph Example: A Corporate Knowledge Graph
Imagine a simplified corporate knowledge graph designed to help answer questions about expertise and projects within a company:
Node Types:

Employee(Properties:name,employeeId,email,jobTitle)Skill(Properties:skillName,skillCategory)Project(Properties:projectName,projectStatus,startDate,endDate)Department(Properties:departmentName,costCenter)Document(Properties:documentTitle,documentType,creationDate)
Relationship Types:
Employee-[:HAS_SKILL {proficiency: “expert”}]->SkillEmployee-[:WORKS_ON {role: “developer”}]->ProjectEmployee-[:MEMBER_OF]->DepartmentProject-[:MANAGED_BY]->DepartmentProject-[:GENERATED_DOCUMENT]->DocumentDocument-[:MENTIONS]->Skill
Visual Representation (Conceptual):
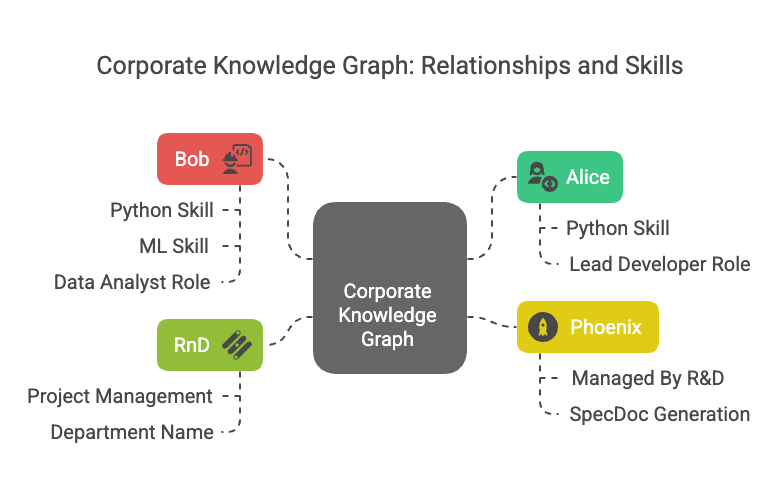
(Alice:Employee {name:"Alice Wonderland", jobTitle:"Software Engineer"})
-[:HAS_SKILL {proficiency:"expert"}]-> (Python:Skill {skillName:"Python"})
-[:WORKS_ON {role:"Lead Developer"}]-> (Phoenix:Project {projectName:"Project Phoenix"})
-[:MEMBER_OF]-> (RnD:Department {departmentName:"Research & Development"})
(Bob:Employee {name:"Bob The Builder", jobTitle:"Data Scientist"})
-[:HAS_SKILL {proficiency:"advanced"}]-> (Python:Skill {skillName:"Python"})
-[:HAS_SKILL {proficiency:"expert"}]-> (ML:Skill {skillName:"Machine Learning"})
-[:WORKS_ON {role:"Data Analyst"}]-> (Phoenix:Project {projectName:"Project Phoenix"})
-[:MEMBER_OF]-> (RnD:Department {departmentName:"Research & Development"})
(Phoenix:Project)-[:MANAGED_BY]->(RnD:Department)
(Phoenix:Project)-[:GENERATED_DOCUMENT]->(SpecDoc:Document {title:"Phoenix Spec v2"})
(SpecDoc)-[:MENTIONS]->(Python:Skill)
This simple graph already allows for complex queries like:
- “Find all employees in the ‘Research & Development’ department who are experts in ‘Python’ and are currently working on ‘Project Phoenix’.”
- “Which projects managed by the ‘Research & Development’ department have generated documents mentioning ‘Python’?”
This ability to model and query intricate webs of relationships is what makes graphs a cornerstone of the GraphRAG approach.
4. Enter GraphRAG: The Next Evolution
GraphRAG represents a significant advancement in the RAG paradigm, moving beyond simple semantic retrieval from disconnected text chunks to a more sophisticated approach that leverages the explicit relationships and structured knowledge inherent in graph databases and knowledge graphs. It aims to provide LLMs with richer, more contextually aware information, enabling them to generate more accurate, insightful, and nuanced responses, especially for complex queries.
Defining GraphRAG
GraphRAG is an architecture that enhances Large Language Models by retrieving relevant contextual information from a knowledge graph or graph database to inform the generation process. Instead of (or in addition to) fetching isolated text passages, GraphRAG taps into a structured representation of entities and their interconnections. This allows the retrieval mechanism to fetch not just individual pieces of information but also the surrounding context, related entities, and the pathways of relationships that connect them.
The core idea is that the explicit structure of a graph provides a superior way to navigate and understand complex information domains compared to relying solely on the implicit information scattered across unstructured text.
Bridging the Gap: Graphs and LLMs
LLMs excel at language understanding and generation but lack inherent mechanisms for deep relational reasoning or accessing specific, factual, and interconnected data in real-time. Knowledge graphs, on the other hand, are purpose-built for storing, managing, and querying such structured relational data.
GraphRAG acts as a bridge between these two powerful technologies:
- Knowledge Graphs provide the factual, interconnected grounding: They serve as the dynamic, verifiable knowledge base.
- LLMs provide the natural language interface and reasoning capabilities: They translate user queries, interpret the retrieved graph context, and synthesize human-readable answers.
By combining these strengths, GraphRAG aims to create AI systems that can “reason” over complex data and communicate their findings effectively.
Core Principle: Relationship-Aware Retrieval
The defining characteristic of GraphRAG is its relationship-aware retrieval strategy. This means that when a query is posed, the system doesn’t just look for nodes or text snippets that are semantically similar to the query terms. Instead, it actively explores the graph structure:
- It identifies key entities mentioned in the query.
- It traverses relationships connected to these entities.
- It extracts subgraphs (relevant portions of the larger graph) that capture the interconnected context around the query.
- It might combine graph traversal with semantic search on node properties or associated textual content.
This allows GraphRAG to retrieve a more holistic and structured context. For example, in response to “What are the potential side effects of drug X for patients with condition Y?”, GraphRAG could retrieve:
- The node for
Drug X. - The node for
Condition Y. - Relationships linking
Drug Xto knownSide Effectnodes. - Relationships linking
Drug XtoContraindicationnodes, especially those related toCondition Y. - Pathways showing interactions with other drugs commonly taken for
Condition Y.
This interconnected set of information is far richer than a collection of text snippets that merely mention “drug X” and “condition Y”.
High-Level Architecture of GraphRAG
While specific implementations can vary, a typical GraphRAG system includes several key stages:

- Query Input: The user poses a question or prompt in natural language.
- Query Understanding & Entity Linking: The system parses the query to identify key entities and concepts. These are then linked to corresponding nodes in the knowledge graph. This step might involve NLP techniques like Named Entity Recognition (NER).
- Graph Retrieval: This is the core of GraphRAG. Based on the identified entities and the nature of the query, the system executes one or more graph queries or traversals to fetch a relevant subgraph or a structured set of information (nodes, edges, paths) from the knowledge graph. This might also involve semantic search over node embeddings or textual properties.
- Context Serialization/Formatting: The retrieved graph-based information, which is inherently structured, needs to be converted into a format (often textual) that the LLM can easily process. This might involve summarizing paths, listing connected entities and their relationships, or creating a natural language description of the retrieved subgraph.
- Prompt Augmentation: The original query is combined with this serialized graph context to create an augmented prompt.
- LLM Generation: The LLM processes the augmented prompt and generates a response, now grounded in the specific, interconnected facts retrieved from the knowledge graph.
- Response Output: The final, context-aware answer is presented to the user.
This architecture allows GraphRAG to leverage the strengths of both structured knowledge representation (graphs) and flexible language processing (LLMs) to tackle complex information needs.
5. Key Components and Mechanisms of GraphRAG
A robust GraphRAG system integrates several critical components and employs sophisticated mechanisms to bridge the gap between raw data, structured knowledge graphs, and language models. Understanding these elements is key to appreciating how GraphRAG achieves its enhanced capabilities.
Graph Construction and Ingestion
The foundation of any GraphRAG system is a well-structured and comprehensive knowledge graph. This involves:
- Data Source Identification: Identifying relevant data sources, which can be structured (databases, APIs), semi-structured (JSON, XML, CSVs), or unstructured (text documents, web pages).
- Entity Extraction: Identifying key entities (e.g., people, organizations, locations, products, concepts) from the source data. For unstructured text, this often involves NLP techniques like Named Entity Recognition (NER).
- Relation Extraction: Identifying the relationships between these entities and their types (e.g., “Company A acquired Company B,” “Person X works for Organization Y”). This can also leverage NLP models, pattern matching, or rule-based systems.
- Schema Design (Optional but Recommended): Defining an ontology or schema for the graph, specifying the types of nodes and edges, their properties, and any constraints. This ensures consistency and facilitates querying.
- Data Transformation and Loading (ETL for Graphs): Transforming the extracted entities and relationships into the graph database’s format and loading them. This might involve disambiguation (ensuring “IBM” refers to the same entity across different sources) and reconciliation.
- Graph Enrichment: Potentially enriching the graph with external knowledge bases (e.g., Wikidata, DBpedia) or by inferring new relationships.
This process can be complex and iterative, often requiring a combination of automated tools and human curation.
Data Representation: Embeddings in Graphs
While graphs explicitly store relationships, embeddings add a powerful layer of semantic understanding. In GraphRAG, embeddings can be generated for various graph elements:

- Node Embeddings: Each node (entity) can be represented as a dense vector capturing its semantic meaning, attributes, and potentially its local graph neighborhood. Techniques include:
- Attribute-based: Using embeddings of textual descriptions or properties of nodes (e.g., averaging Word2Vec embeddings of a node’s description).
- Graph Neural Networks (GNNs): Models like Graph Convolutional Networks (GCN), GraphSAGE, or Graph Attention Networks (GAT) learn node embeddings by aggregating information from their neighbors, thus capturing graph structure.
- Knowledge Graph Embedding (KGE) Models: For KGs with typed relationships, models like TransE, TransR, DistMult, or ComplEx learn embeddings for both entities and relations, often by treating relations as translation or scoring functions in the embedding space.
- Edge/Relationship Embeddings: Some KGE models also produce embeddings for relationship types, capturing their semantic meaning.
- Subgraph Embeddings: Techniques can be used to generate embeddings for entire subgraphs, representing the collective meaning of a cluster of connected nodes and edges.
These embeddings enable semantic search directly on graph elements, allowing, for example, finding nodes semantically similar to a query even if the exact keywords don’t match.
Visual Table: Understanding Embeddings in GraphRAG
| Aspect | Description | Example in GraphRAG | Common Techniques Used |
| Node/Entity Embeddings | Dense numerical vector representing a node’s semantic meaning and context. | Vector for “ACME Corp” capturing its industry, size, and connections to partners. | GNNs (GraphSAGE, GCN, GAT), KGE models (TransE, DistMult), attribute-based embeddings. |
| Relationship Type Embeddings | Vector representing the semantic meaning of a specific type of edge. | Vector for the “SUPPLIES_TO” relationship, distinct from “COMPETES_WITH”. | KGE models (TransE, RotatE). |
| Subgraph Embeddings | Vector representing a coherent collection of interconnected nodes and edges. | Embedding of a “project team” including its members, their skills, and the project. | Graph pooling mechanisms, GNNs applied to subgraphs, averaging node embeddings. |
| Purpose in GraphRAG | Enable semantic search, similarity calculations, node clustering, link prediction. | Finding companies “similar” to ACME Corp based on their graph context, not just text. | Cosine similarity, dot product, Euclidean distance on embedding vectors. |
Vector Storage and Indexing for Hybrid Power
While the graph database itself stores the primary structure, embeddings (being high-dimensional vectors) are often stored and indexed in specialized vector databases or using vector index capabilities within graph databases for efficient Approximate Nearest Neighbor (ANN) search.
This allows for hybrid retrieval strategies:
- Use semantic search on embeddings to find initial relevant nodes.
- Then, use graph traversals from these seed nodes to explore their connections and expand the context.
Visual Table: Vector Storage Options in GraphRAG
| Storage Solution | Type | Key Features for GraphRAG | Example Use Case | Popular Options |
| Dedicated Vector Database | Specialized Vector Store | Highly optimized for ANN search, metadata filtering, scalability for billions of vectors, real-time updates. | Storing and rapidly querying embeddings of all nodes and potentially subgraphs in a large knowledge graph. | Pinecone, Weaviate, Milvus, Qdrant, ChromaDB |
| Graph Database with Vector Index | Hybrid (Graph + Vector) | Stores graph structure and vector embeddings natively; allows integrated graph pattern matching and vector similarity search. | Finding nodes semantically similar to a query concept and then immediately traversing their graph connections. | Neo4j (Vector Index), ArangoDB, TigerGraph |
| Search Engine with Vector Support | General-Purpose Search | Combines traditional text search (keyword, BM25) with vector search capabilities within a unified index. | Indexing node textual properties (e.g., descriptions) alongside their semantic embeddings for hybrid retrieval. | Elasticsearch (with KNN), OpenSearch (with k-NN) |
| In-Memory Library / Local Index | Software Library | Fast for smaller datasets, useful for prototyping, development, or applications with limited scale. | Storing and searching embeddings for a small, focused knowledge graph during R&D or for a desktop application. | FAISS, Annoy, ScaNN |
Graph-Powered Retrieval Strategies
This is where GraphRAG truly differentiates itself. Instead of just keyword or semantic similarity on isolated chunks, retrieval involves:

- Entity-driven Search: Identifying entities in the query and starting exploration from their corresponding nodes in the graph.
- Relationship Traversal: Following specific types of edges to find related information (e.g.,
employee -[:WORKS_IN]-> department -[:LOCATED_IN]-> city). - Pathfinding: Finding paths (sequences of nodes and edges) between two or more entities to understand how they are connected.
- Subgraph Extraction: Retrieving a relevant neighborhood or subgraph around one or more seed nodes. This subgraph provides a rich, interconnected context.
- Community Detection: Identifying clusters of densely connected nodes that might represent a coherent topic or group relevant to the query.
- Pattern Matching: Using graph query languages (like Cypher for Neo4j, GSQL for TigerGraph, or SPARQL for RDF graphs) to find specific patterns of nodes and relationships.
- Hybrid Approaches: Combining semantic search on node embeddings (to find starting points) with graph traversals (to expand and refine context). For example, find the 5 most semantically similar
ResearchPapernodes to a query, then retrieve theirauthors,cited_papers, andkeywords.
Example Graph Queries
Using Cypher (common in Neo4j) as an example for our Corporate Knowledge Graph:
- Find experts in Python in the R&D department:
MATCH (e:Employee)-[:MEMBER_OF]->(d:Department {departmentName: "Research & Development"}), (e)-[:HAS_SKILL {proficiency: "expert"}]->(s:Skill {skillName: "Python"}) RETURN e.name, e.jobTitle - Find projects Alice worked on and the skills she used for them:
MATCH (e:Employee {name: "Alice Wonderland"})-[:WORKS_ON]->(p:Project), (e)-[:HAS_SKILL]->(s:Skill) // Further logic might be needed to link specific skills to specific projects if not directly modeled RETURN p.projectName, collect(s.skillName) AS skillsUsedByAlice(A more precise model might haveUSED_SKILL_ON_PROJECTrelationships) - Retrieve a 2-hop neighborhood around “Project Phoenix”:
MATCH (p:Project {projectName: "Project Phoenix"})-[r1]-(n1)-[r2]-(n2) RETURN p, r1, n1, r2, n2 LIMIT 100 // To keep results manageable
These queries return structured data that is far more informative than isolated text chunks.
Context Augmentation and Prompt Engineering with Graph Data
The structured information retrieved from the graph (nodes, properties, relationships, paths) needs to be “linearized” or serialized into a format, typically text, that an LLM can understand and use within its context window. Strategies include:
- Templating: Using predefined templates to list entities, their attributes, and their connections. E.g., “Node A (type: X, property1: value1) is connected to Node B (type: Y) via relationship R.”
- Path Summarization: Describing a path as a sequence: “Alice works in R&D, which manages Project Phoenix.”
- Natural Language Generation (NLG) Snippets: Using smaller NLG models or rule-based systems to convert parts of the subgraph into fluent sentences.
- JSON or Markdown Formatting: Presenting the structured data in a clean, readable format that the LLM can parse.
- Token-Efficient Representations: Developing compact ways to represent graph structures to fit more information into the LLM’s limited context window.
Prompt Engineering is crucial. The prompt must guide the LLM on how to use the provided graph context effectively. This might involve:
- Explicit instructions: “Using the following information from our knowledge graph, answer the user’s query…”
- Role-playing: “You are an expert analyst with access to a corporate knowledge graph…”
- Few-shot examples: Providing examples of how to use similar graph context to answer questions.
LLM Generation: Synthesizing Knowledge
Finally, the LLM takes the original user query and the augmented prompt (containing the serialized graph context) to generate the final response. Because the LLM now has access to explicit, interconnected facts and relationships, it can:
- Provide more accurate and detailed answers.
- Perform implicit multi-hop reasoning by connecting information present in the retrieved subgraph.
- Reduce hallucinations by grounding its statements in the provided graph data.
- Explain its reasoning by referring back to the relationships and entities from the graph (if designed to do so).
The quality of the LLM’s output is highly dependent on the quality and relevance of the retrieved graph context and the clarity of the prompt.
6. How GraphRAG Overcomes Traditional RAG Limitations
The integration of knowledge graphs into the RAG pipeline directly addresses many of the shortcomings observed in traditional, vector-search-based RAG systems. By shifting from a model of isolated information chunks to one of interconnected entities and relationships, GraphRAG unlocks new levels of contextual understanding and reasoning.
Superior Contextual Understanding
Traditional RAG often retrieves text snippets that are semantically similar to the query but may lack the broader context of how those snippets relate to other pieces of information.
GraphRAG, by design, retrieves interconnected data. When it fetches a node (entity), it can also easily fetch its direct neighbors, specific types of relationships, or even entire relevant subgraphs. This provides the LLM with a much richer, more holistic understanding of the topic. For example, instead of just getting a document mentioning a “company merger,” GraphRAG can provide the acquiring company, the acquired company, the date of the merger, key personnel involved, affected products, and links to news articles discussing the implications – all as a connected structure. This allows the LLM to grasp the nuances and interdependencies that would be lost in a collection of disconnected text fragments.
Enabling Complex Multi-Hop Reasoning
Multi-hop reasoning – connecting information across several intermediate steps – is a significant challenge for traditional RAG. While an LLM might theoretically be able to piece together such inferences if all relevant chunks are retrieved, the retrieval process itself is often not optimized for this.
GraphRAG excels at multi-hop reasoning because graph traversal is a native capability. Queries like “Find researchers who published papers with authors who later advised Nobel laureates” can be explicitly translated into graph traversal patterns. The graph database can efficiently execute these multi-step queries, returning a precise set of entities and paths that satisfy the complex criteria. The LLM then receives this pre-computed chain of reasoning, making its task of generating an answer significantly easier and more accurate. It doesn’t have to “guess” the connections; they are explicitly provided.
Reducing Hallucinations with Factual Grounding
LLM hallucinations often occur when the model lacks specific knowledge or tries to fill gaps by generating plausible-sounding but incorrect information. While traditional RAG helps by providing external text, the LLM might still misinterpret or over-generalize from these snippets.
GraphRAG provides a stronger form of factual grounding because knowledge graphs are often curated to represent verified facts and their relationships. When the LLM’s context is augmented with precise data points from a KG (e.g., “Company X is headquartered in City Y,” “Drug A has a known interaction with Drug B”), the LLM is more constrained to adhere to these facts. If the graph is considered a source of truth, the LLM’s responses can be more directly tied to this verifiable information, leading to a significant reduction in factual errors and speculative statements. The structure itself guides the LLM towards factually consistent outputs.
Answering Intricate, Relationship-Driven Queries
Many complex questions are inherently about relationships: “How does a change in supplier A affect product B’s manufacturing cost, given that A supplies component C which is used in sub-assembly D of product B?” Traditional RAG would struggle to gather and synthesize all these specific relational links.
GraphRAG is ideally suited for such relationship-driven queries. The query can be decomposed into a series of graph traversals and property lookups. The system can retrieve the specific path through the supply chain, identify the relevant components and costs, and present this structured information to the LLM. The LLM can then articulate the impact, having been provided with the explicit chain of dependencies from the graph. This allows for answers that are not just relevant but also deeply explanatory of the underlying mechanisms and connections.
In essence, GraphRAG moves the RAG paradigm closer to how humans often reason: by identifying key entities and then exploring their connections and relationships to build a comprehensive understanding of a situation or answer a complex question.
7. Conceptual Steps to Building a GraphRAG System
Developing a GraphRAG system is a multi-faceted endeavor that combines data engineering, knowledge modeling, machine learning, and LLM integration. While specific implementations will vary based on the domain, data, and tools, the following conceptual steps outline a general lifecycle:
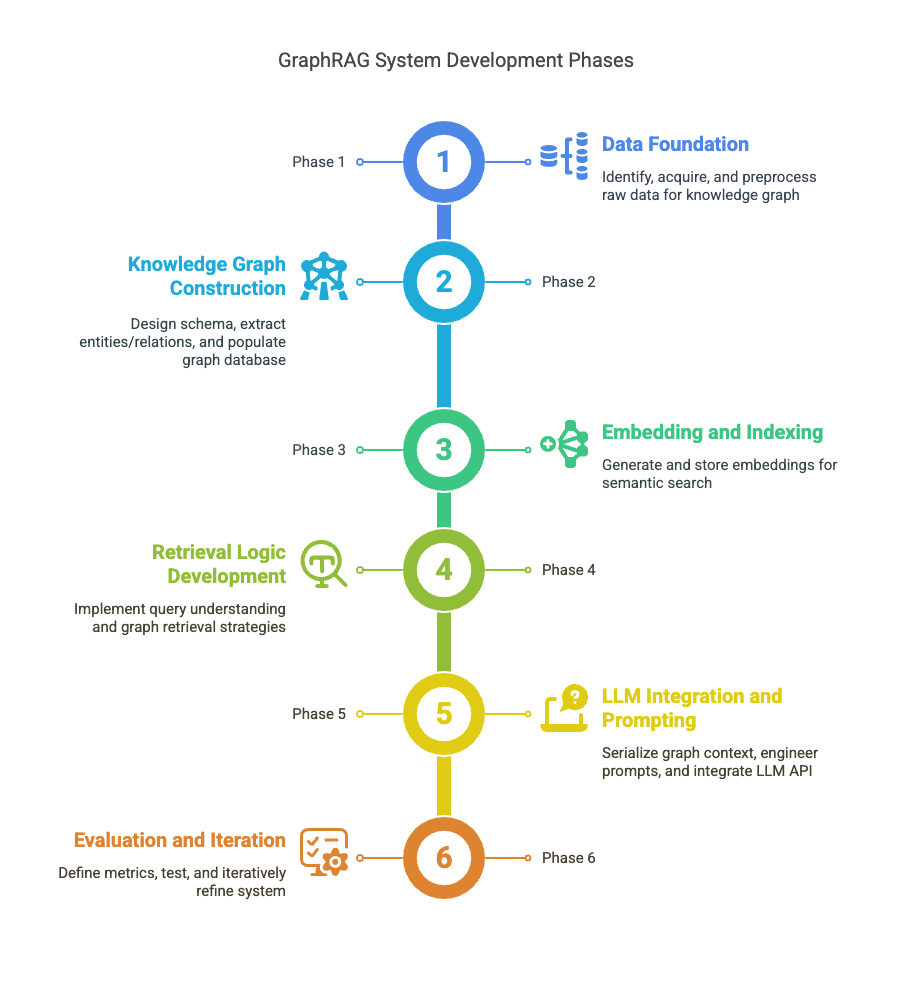
Phase 1: Data Foundation
- Identify Knowledge Sources: Determine the raw data that will populate the knowledge graph. This can include databases, APIs, documents (PDFs, Word, text files), spreadsheets, web pages, etc.
- Define Scope and Objectives: Clearly articulate what questions the GraphRAG system should answer and what level of detail is required in the knowledge graph. This helps in prioritizing data sources and modeling efforts.
- Data Acquisition and Preprocessing: Gather the identified data. Cleanse it by handling missing values, inconsistencies, and formatting issues. For unstructured text, this might involve OCR for scanned documents, text extraction, and initial normalization.
Phase 2: Knowledge Graph Construction
- Schema/Ontology Design (Highly Recommended):
- Define the main entity types (nodes) relevant to your domain (e.g.,
Person,Organization,Product,Event,Concept). - Define the relationship types (edges) that connect these entities and their semantic meaning (e.g.,
WORKS_FOR,INVESTED_IN,CAUSES,PART_OF). - Specify properties for each node and relationship type.
- Define the main entity types (nodes) relevant to your domain (e.g.,
- Entity Extraction:
- From structured sources: Map table rows/columns to nodes/properties.
- From unstructured text: Employ NLP techniques like Named Entity Recognition (NER) to identify mentions of your defined entity types.
- Relation Extraction:
- From structured sources: Foreign keys or join tables often indicate relationships.
- From unstructured text: Use NLP models (e.g., relation extraction classifiers, open information extraction) or rule-based patterns to identify relationships between extracted entities.
- Entity Linking and Disambiguation: Resolve mentions of the same real-world entity to a single node in the graph (e.g., ensuring “IBM,” “International Business Machines,” and “I.B.M.” all point to the same
Organizationnode). - Graph Population: Load the extracted entities and relationships into a chosen graph database (e.g., Neo4j, TigerGraph, Neptune).
- Graph Refinement and Validation: Iteratively review the graph for accuracy, consistency, and completeness. This may involve manual curation and automated consistency checks.
Phase 3: Embedding and Indexing
- Generate Embeddings (Optional but often beneficial):
- Node Embeddings: Create vector representations for nodes, capturing their semantic meaning based on their properties and/or graph structure (using GNNs or KGE models).
- Textual Content Embeddings: If nodes have associated long-form text (e.g., document content linked to a
Documentnode), create embeddings for this text.
- Store and Index Embeddings:
- Load these embeddings into a vector database or use the vector indexing capabilities of your graph database. This enables efficient semantic search.
Phase 4: Retrieval Logic Development
- Query Understanding Module: Develop a component to parse user queries in natural language.
- Identify key entities mentioned in the query.
- Link these entities to nodes in the knowledge graph (entity linking against the graph).
- Determine the intent of the query (e.g., seeking a specific fact, asking for an explanation, requesting a comparison).
- Graph Retrieval Strategies Implementation:
- Implement functions for various graph traversal patterns (e.g., finding neighbors, paths between nodes, k-hop neighborhoods).
- Develop methods to execute complex graph queries (e.g., using Cypher, SPARQL, GSQL).
- Integrate semantic search capabilities using the indexed embeddings (e.g., find nodes semantically similar to a query phrase).
- Design hybrid retrieval logic that combines graph traversals with semantic search for optimal results. For example, use semantic search to find initial seed nodes, then use graph traversals to expand context.
- Contextualization Logic: Determine how much of the graph (e.g., depth of traversal, number of neighbors) to retrieve to provide sufficient context without overwhelming the LLM.
Phase 5: LLM Integration and Prompting
- Context Serialization: Develop methods to convert the retrieved graph data (nodes, edges, paths, subgraphs) into a textual format that the LLM can process. This could be structured (like JSON snippets), semi-structured (lists of facts), or more narrative.
- Prompt Engineering: Design effective prompts that:
- Clearly present the user’s original query.
- Incorporate the serialized graph context.
- Instruct the LLM on how to use the graph context to formulate its answer.
- Potentially include examples (few-shot prompting) to guide the LLM’s response style and accuracy.
- LLM Selection and API Integration: Choose an appropriate LLM (e.g., GPT series, Llama series, Claude) and integrate with its API.
- Response Post-processing: Optionally, process the LLM’s output to format it, extract structured information, or add citations back to the graph data.
Phase 6: Evaluation and Iteration
- Define Evaluation Metrics: Establish metrics to assess the performance of the GraphRAG system. These could include:
- Retrieval Quality: Precision and recall of the retrieved graph context.
- Answer Accuracy: Factual correctness of the LLM’s responses.
- Completeness: How comprehensively the answer addresses the query.
- Faithfulness/Groundedness: How well the answer is supported by the retrieved graph context.
- Absence of Hallucinations.
- Develop Test Sets: Create a diverse set of questions and expected outcomes to test the system.
- Iterative Refinement: Continuously evaluate the system, identify weaknesses (e.g., gaps in the knowledge graph, suboptimal retrieval strategies, ineffective prompts), and iterate on all phases – from graph construction to prompt engineering – to improve performance. This is an ongoing process.
Building a GraphRAG system is an iterative journey. Starting with a focused use case and a core set of data, and then gradually expanding the graph’s richness and the sophistication of the retrieval and generation components, is often a practical approach.
8. Transformative Use Cases and Applications of GraphRAG
The ability of GraphRAG to understand and leverage complex relationships opens up a wide array of powerful applications across various industries. By grounding LLM responses in structured, interconnected knowledge, GraphRAG can deliver insights and answers that are significantly more nuanced, accurate, and actionable than those from traditional RAG or standalone LLMs.
Advanced Question Answering over Complex Archives
- Domain: Legal, scientific research, financial compliance, historical archives.
- Challenge: These domains involve vast collections of documents with intricate interdependencies, definitions, and precedents. Answering questions often requires synthesizing information from multiple sources and understanding subtle relationships.
- GraphRAG Solution:
- A knowledge graph can model legal cases and their citations, scientific papers and their methodologies/findings, financial regulations and their applicability, or historical events and their causal links.
- Example: “What were the precedents cited in Case X that involved intellectual property disputes with technology companies, and how did their outcomes influence the ruling in Case X?” GraphRAG can traverse citation links, filter by case type and party attributes, and provide the LLM with a structured context of relevant precedents and their connections to Case X.
- Impact: Faster and more accurate research, improved decision-making, and deeper understanding of complex information landscapes.
Hyper-Personalized Recommendation Engines
- Domain: E-commerce, content streaming, social media, travel.
- Challenge: Moving beyond simple collaborative filtering or content-based recommendations to understand the “why” behind user preferences and offer truly novel and relevant suggestions.
- GraphRAG Solution:
- A knowledge graph can represent users, items, content, their attributes, and diverse interactions (e.g.,
user -LIKES-> genre,user -PURCHASED-> product,product -COMPLEMENTARY_TO-> another_product,actor -STARRED_IN-> movie -DIRECTED_BY-> director). - Example: “I enjoyed movies A and B, which have strong female leads and intricate plots. What other movies or series, perhaps by the same screenwriter or featuring actors who have worked with these directors, would I like?” GraphRAG can explore these multi-hop connections to find surprising yet relevant recommendations, which the LLM can then present with explanations.
- A knowledge graph can represent users, items, content, their attributes, and diverse interactions (e.g.,
- Impact: Increased user engagement, higher conversion rates, and improved customer satisfaction through more insightful and diverse recommendations.
Accelerating Scientific Discovery (e.g., Drug Development)
- Domain: Pharmaceuticals, bioinformatics, materials science.
- Challenge: Scientists grapple with massive datasets of genes, proteins, diseases, chemical compounds, and research literature. Identifying novel connections and hypotheses is crucial but time-consuming.
- GraphRAG Solution:
- Knowledge graphs can integrate data on molecular interactions, gene-disease associations, drug targets, clinical trial results, and published research.
- Example: “Are there any existing compounds, not currently approved for Alzheimer’s, that target pathways known to be dysregulated in early-stage Alzheimer’s and have shown low toxicity in similar patient populations?” GraphRAG can query the KG for compounds, their targets, links to disease pathways, and associated clinical trial safety data, providing the LLM with a candidate list and supporting evidence.
- Impact: Faster hypothesis generation, identification of drug repurposing opportunities, and a more comprehensive understanding of complex biological systems.
Sophisticated Fraud Detection and Anomaly Identification
- Domain: Finance, insurance, e-commerce, cybersecurity.
- Challenge: Fraudsters often use complex networks of synthetic identities, shell companies, or collusive behaviors that are hard to detect by looking at individual transactions in isolation.
- GraphRAG Solution:
- Knowledge graphs can model relationships between accounts, individuals, organizations, transactions, IP addresses, devices, and known fraudulent patterns.
- Example: “Investigate this transaction: A new account, funded by a wire transfer from a high-risk jurisdiction, immediately made multiple purchases shipped to different addresses, some of which are linked to previously flagged accounts.” GraphRAG can highlight this suspicious pattern of connections, retrieve details of linked entities, and provide this context to an LLM to summarize the risk and suggest investigation steps.
- Impact: Improved detection of complex fraud rings, reduced financial losses, and enhanced security through a deeper understanding of relational patterns.
Intelligent Supply Chain Optimization and Risk Analysis
- Domain: Manufacturing, logistics, retail.
- Challenge: Modern supply chains are global and highly complex, with numerous interdependencies. Understanding risks (e.g., supplier failures, geopolitical events, natural disasters) and optimizing for resilience and efficiency is vital.
- GraphRAG Solution:
- A knowledge graph can map out suppliers, components, manufacturing plants, distribution centers, transportation routes, and their dependencies.
- Example: “If a major port in Southeast Asia is closed for a week, which of our products will be most affected, what are the alternative sourcing options for critical components, and what is the potential financial impact?” GraphRAG can trace dependencies from the port to components to products, identify bottlenecks, and retrieve information on alternative suppliers or routes.
- Impact: Enhanced supply chain visibility, proactive risk mitigation, improved resilience, and more efficient logistics planning.
Comprehensive Customer 360 and Relationship Intelligence
- Domain: Sales, marketing, customer service.
- Challenge: Customer data is often siloed across CRM, marketing automation, support tickets, and social media. Building a truly holistic view of a customer and their relationships is difficult.
- GraphRAG Solution:
- A knowledge graph can integrate all customer touchpoints, their interactions, their relationships with other customers or organizations (for B2B), and their product usage.
- Example: “Show me the key contacts at ACME Corp, their interaction history with our support and sales teams, any outstanding issues, and their connections to other companies in our portfolio that might present cross-selling opportunities.” GraphRAG can assemble this complex profile, allowing an LLM to generate a concise briefing for a sales executive.
- Impact: Deeper customer understanding, more effective and personalized engagement, improved customer retention, and identification of new sales opportunities.
These use cases illustrate the transformative potential of GraphRAG. By enabling LLMs to tap into the power of explicitly represented knowledge and relationships, GraphRAG paves the way for more intelligent, context-aware, and insightful AI applications.
9. Navigating the Frontiers: Challenges and Future Directions
While GraphRAG offers immense promise, its widespread adoption and continued advancement depend on addressing several key challenges and exploring exciting future research directions. The journey towards seamlessly integrating structured knowledge with the generative power of LLMs is ongoing.
Scalability and Performance
- Challenge: Real-world knowledge graphs can be enormous, containing billions of nodes and edges. Performing complex traversals, subgraph extractions, and GNN computations on such large graphs in real-time to serve LLM requests can be computationally intensive. Ensuring low latency for retrieval is critical for interactive applications.
- Future Directions:
- Development of more optimized graph database engines and distributed graph processing frameworks.
- Advanced graph indexing techniques tailored for RAG workloads.
- Graph partitioning and sampling methods to work with manageable subsets of large graphs.
- Hardware acceleration (e.g., GPUs, TPUs) for graph algorithms and GNNs.
Complexity of Knowledge Graph Creation and Maintenance
- Challenge: Building high-quality, comprehensive knowledge graphs is often a labor-intensive and complex process. Extracting entities and relations accurately from diverse, noisy, and unstructured sources remains a significant hurdle. Keeping the KG up-to-date as new information emerges is also crucial but challenging.
- Future Directions:
- Improved automated and semi-automated KG construction techniques leveraging advanced NLP, machine learning (including LLMs themselves for extraction tasks), and human-in-the-loop systems.
- Development of tools for schema evolution and KG versioning.
- Techniques for incremental KG updates and real-time ingestion pipelines.
- Crowdsourcing and collaborative KG building platforms.
Handling Dynamic and Evolving Data
- Challenge: Many knowledge domains are highly dynamic (e.g., news, social media, financial markets). The knowledge graph must reflect these changes in a timely manner for the GraphRAG system to provide current and relevant information.
- Future Directions:
- Research into temporal graph databases and models that can explicitly represent and reason about time-varying information and event sequences.
- Streaming graph algorithms and continuous learning methods for updating graph embeddings and structures.
- Mechanisms for detecting and resolving inconsistencies arising from new data.
Standardizing Evaluation Metrics
- Challenge: Evaluating the end-to-end performance of GraphRAG systems is complex. Metrics are needed not just for the LLM’s output (e.g., fluency, coherence) but also for the relevance and completeness of the retrieved graph context, the faithfulness of the answer to that context, and the system’s ability to perform multi-hop reasoning.
- Future Directions:
- Development of benchmark datasets and standardized evaluation protocols specifically designed for GraphRAG.
- Metrics that can assess the quality of retrieved subgraphs and paths.
- Techniques for automatically evaluating the factual consistency between the LLM’s response and the graph data.
Enhancing Explainability and Interpretability
- Challenge: While GraphRAG can provide more grounded answers, understanding why a particular piece of graph context was retrieved and how the LLM used it to arrive at an answer is important for trust and debugging.
- Future Directions:
- Methods for visualizing the retrieved subgraphs and the reasoning paths used.
- Techniques for the LLM to explicitly cite the nodes and relationships from the graph that support its assertions.
- Developing “graph-aware” attention mechanisms in LLMs that can highlight which parts of the graph context were most influential.
Optimizing Hybrid Retrieval Models
- Challenge: Finding the optimal balance and interplay between dense vector-based retrieval (for semantic similarity) and sparse graph-based retrieval (for explicit relationships) is an active area of research. How to best combine signals from both modalities for different types of queries is not always clear.
- Future Directions:
- Learnable hybrid retrieval models that can adaptively weigh graph-based and vector-based evidence.
- Unified models that can perform semantic search and graph traversal within a single framework.
- End-to-end training of the retriever and the LLM generator in GraphRAG systems.
Integrating Multimodal Knowledge
- Challenge: Knowledge is not just textual or relational; it can also be visual, auditory, or sensory. Current GraphRAG primarily focuses on textual and structured data.
- Future Directions:
- Extending knowledge graphs to include nodes representing images, videos, or audio clips, with relationships linking them to textual concepts and entities.
- Developing multimodal embedding techniques that can represent different data types in a shared semantic space.
- GraphRAG systems that can retrieve and synthesize information from diverse modalities to answer queries.
Addressing these challenges and pursuing these future directions will be crucial for unlocking the full potential of GraphRAG and paving the way for even more intelligent and contextually aware AI systems.
10. GraphRAG in Context: Comparisons with Other RAG Approaches
GraphRAG is not the only way to augment LLMs with external knowledge. Understanding its distinct advantages and when it’s most suitable requires comparing it to other prevalent RAG techniques, primarily standard vector RAG and RAG over structured data like SQL databases.
GraphRAG vs. Standard Vector RAG
Standard vector RAG, often the first type of RAG system developers encounter, primarily relies on retrieving text chunks from a document corpus based on semantic similarity between the query embedding and chunk embeddings.

Key Differentiator: The fundamental difference lies in how relationships are handled. Standard RAG infers relationships implicitly from text, while GraphRAG explicitly models and queries them. This makes GraphRAG significantly more powerful when the answer depends on understanding these connections.
GraphRAG vs. RAG over Structured Data (e.g., SQL RAG)
Another approach to RAG involves querying structured databases (like SQL databases) using an LLM that can translate natural language queries into formal database queries (e.g., NL-to-SQL).
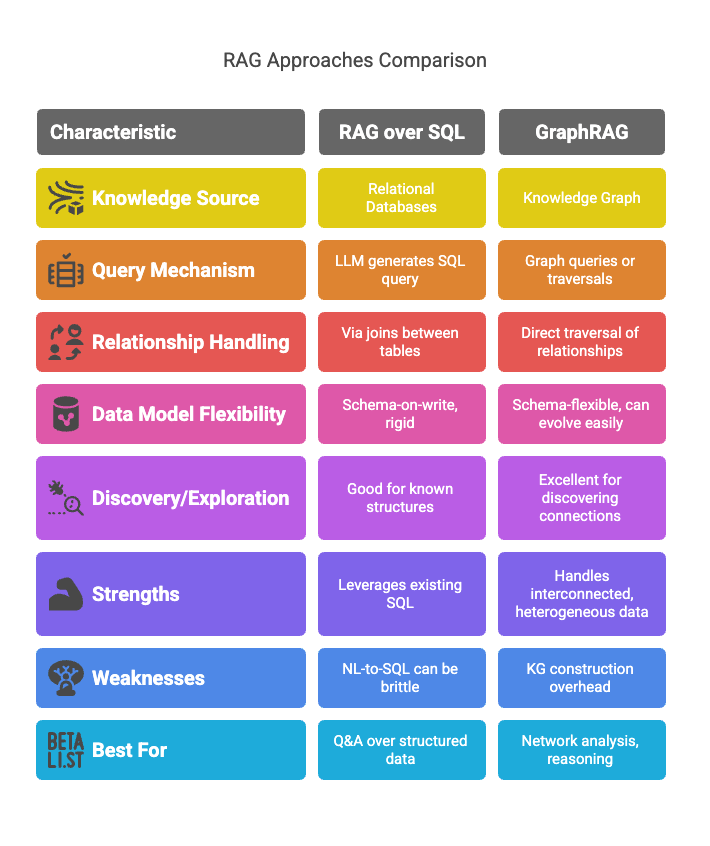
Key Differentiator: While both use structured data, graph databases are inherently optimized for traversing relationships and handling heterogeneous, interconnected data, which can be cumbersome with SQL’s join-intensive operations for deep relational queries. GraphRAG is often more suited for scenarios where the connections themselves are as important as the data points. Furthermore, KGs can integrate unstructured text with structured entities more seamlessly than a purely relational model.
Hybrid Approaches: It’s also important to note that these approaches are not mutually exclusive. A sophisticated RAG system might employ multiple strategies:
- Using vector search for initial document triage.
- Using GraphRAG for deep dives into interconnected entities mentioned in those documents.
- Using NL-to-SQL for querying specific transactional data stored in relational databases.
The choice of RAG technique depends heavily on the nature of the knowledge base, the types of queries expected, and the desired depth of understanding. GraphRAG offers a compelling solution when the information landscape is rich with relationships and the goal is to unlock insights from these connections.
11. The GraphRAG Toolkit: Essential Technologies
Building and deploying a GraphRAG system involves leveraging a stack of specialized tools and technologies. These components work together to enable the ingestion, storage, querying, and reasoning capabilities that define GraphRAG.
Graph Databases
These are the heart of a GraphRAG system, responsible for storing and managing the knowledge graph.
- Neo4j: A popular and mature native graph database that uses Cypher as its query language. Known for its performance in traversals, ACID compliance, and strong community support. Offers features like vector indexing for hybrid search.
- TigerGraph: A massively parallel processing (MPP) graph database designed for high performance and scalability on very large graphs. Uses GSQL, a powerful SQL-like query language for graphs.
- Amazon Neptune: A fully managed graph database service from AWS that supports both Property Graph (queried with Gremlin or openCypher) and RDF graphs (queried with SPARQL).
- ArangoDB: A multi-model database that supports graph, document, and key/value data models in a single core. Uses AQL (ArangoDB Query Language).
- Microsoft Azure Cosmos DB for Apache Gremlin: A globally distributed, multi-model database service that offers a Gremlin API for graph data.
- Knowledge Graph Platforms: Some platforms like Stardog or GraphDB (Ontotext) are specifically designed for RDF knowledge graphs and offer advanced features like OWL reasoning and SHACL validation.
Choice Factors: Scalability needs, query language preference, data model (Property Graph vs. RDF), cloud vs. on-premise deployment, existing ecosystem, and specific features like built-in machine learning or vector search.
Vector Databases/Indexes
Used for storing and efficiently searching embeddings of nodes, text, or subgraphs.
- Pinecone: A managed vector database service designed for high-performance similarity search at scale.
- Weaviate: An open-source vector database that can store data objects and their vector embeddings, offering GraphQL and RESTful APIs. Supports hybrid search.
- Milvus: An open-source vector database built for similarity search and AI applications, supporting various ANN index types.
- ChromaDB: An open-source embedding database focused on simplicity and developer experience, often used with LangChain.
- FAISS (Facebook AI Similarity Search): A library for efficient similarity search and clustering of dense vectors. Often used as a building block or for smaller-scale applications.
- Vector Indexing within Graph Databases: As mentioned, some graph databases (e.g., Neo4j) are incorporating native vector indexing capabilities.
Choice Factors: Scalability, query latency requirements, managed vs. self-hosted, integration with other tools, specific indexing algorithms needed.
LLM Orchestration Frameworks
These frameworks simplify the development of LLM-powered applications, including RAG systems, by providing tools for chaining calls, managing prompts, interacting with various models, and connecting to data sources.
- LangChain: A widely adopted open-source framework for building applications with LLMs. It has extensive support for various data loaders, text splitters, embedding models, vector stores, and RAG pipelines, including components for graph-based RAG.
- LlamaIndex (formerly GPT Index): Another popular open-source framework focused on connecting LLMs to external data. It offers sophisticated indexing and retrieval strategies, including support for knowledge graphs and graph RAG patterns.
- Haystack (by deepset): An open-source NLP framework that allows you to build production-ready LLM applications, including question answering and semantic search systems. It supports various retrievers and readers.
Choice Factors: Programming language preference (Python is dominant), ease of use, community support, available integrations, and specific features for graph data handling.
Natural Language Processing (NLP) Libraries
Essential for preprocessing text data, extracting entities and relationships, and understanding user queries.
- spaCy: An industrial-strength NLP library in Python, known for its speed, efficiency, and pre-trained models for tasks like NER, part-of-speech tagging, and dependency parsing.
- NLTK (Natural Language Toolkit): A comprehensive Python library for NLP, offering a wide range of tools and resources, though sometimes considered more academic than spaCy.
- Stanford CoreNLP: A suite of NLP tools from Stanford University, providing robust capabilities in various languages.
- Hugging Face Transformers: Provides access to thousands of pre-trained models (including many for NER and relation extraction) and tools for fine-tuning them.
Choice Factors: Language support, performance requirements, ease of customization, availability of pre-trained models for specific tasks.
Graph Machine Learning Libraries
Used for generating graph embeddings (e.g., node embeddings using GNNs) and performing other graph analytics tasks.
- PyTorch Geometric (PyG): A library for deep learning on graphs and other irregular structures, built on PyTorch. Offers implementations of many GNN layers and models.
- Deep Graph Library (DGL): Another popular Python package for deep learning on graphs, supporting multiple deep learning frameworks (PyTorch, TensorFlow, MXNet).
- Graph Nets (by DeepMind): A library in TensorFlow and JAX for building graph neural networks.
- Libraries within Graph Databases: Some graph databases (e.g., Neo4j with its Graph Data Science library) provide built-in functionalities for running GNNs and other graph algorithms.
Choice Factors: Deep learning framework preference, scalability, variety of GNN models supported, ease of integration with graph databases.
The specific combination of these technologies will depend on the project’s requirements, existing infrastructure, and team expertise. However, a well-chosen toolkit is fundamental to building effective and scalable GraphRAG systems.
12. Conclusion: The Dawn of Relationship-Aware AI
The journey from basic language models to sophisticated, knowledge-grounded AI systems has been rapid and transformative. Retrieval Augmented Generation marked a pivotal step, allowing LLMs to break free from the confines of their training data. Now, GraphRAG represents the next frontier in this evolution, ushering in an era of relationship-aware AI.
By explicitly modeling and leveraging the intricate connections within data, GraphRAG addresses fundamental limitations of earlier RAG approaches. It moves beyond mere semantic similarity of isolated text chunks to a deeper, more contextual understanding rooted in the explicit structure of knowledge graphs. This allows for unprecedented capabilities in multi-hop reasoning, a significant reduction in hallucinations through stronger factual grounding, and the ability to answer complex, relationship-driven queries with far greater precision and insight.
The Symbiotic Power of Graphs and LLMs
GraphRAG is a testament to the power of synergy. Knowledge graphs provide the structured, verifiable, and interconnected facts – the “bones” of knowledge. Large Language Models provide the intuitive natural language interface, the ability to understand nuanced queries, and the fluency to synthesize complex information into human-understandable narratives – the “voice” and “interpretive intelligence.”
Together, they create a system that is more than the sum of its parts: an AI that can not only retrieve information but also reason over it, connecting disparate pieces of data to uncover hidden patterns, explain complex phenomena, and provide truly insightful answers. This combination allows us to tackle problems that were previously intractable, moving from simple information retrieval to genuine knowledge discovery.
Pioneering the Future of Information Access
The applications of GraphRAG are vast and impactful, spanning scientific discovery, financial analysis, personalized medicine, fraud detection, supply chain optimization, and beyond. As organizations increasingly recognize that their most valuable asset is not just raw data but the relationships within that data, the demand for technologies like GraphRAG will only grow.
The challenges ahead – scalability, automated graph construction, dynamic data handling, and robust evaluation – are significant but not insurmountable. Ongoing research and development in graph databases, graph machine learning, NLP, and LLM orchestration are continuously pushing the boundaries of what’s possible.
GraphRAG is not just an incremental improvement; it’s a paradigm shift. It encourages us to think about knowledge not as a collection of isolated facts, but as a rich, interconnected web. By empowering LLMs with the ability to navigate and understand this web, we are taking a crucial step towards building AI systems that are not only more intelligent but also more reliable, transparent, and ultimately, more useful in solving real-world problems. The dawn of relationship-aware AI is here, and its potential is only beginning to be explored.
Discover more from SkillWisor
Subscribe to get the latest posts sent to your email.
