
A deep dive into the creation of a multimodal, vision-aware AI tutor for the Google Gemini Live Agent Challenge
Education is facing one of its most significant crossroads in history. For centuries, the classroom model has remained anchored to a 19th-century industrial design: one teacher at the front, thirty students in rows, a fixed pace, and a curriculum built for the average. We have known for decades that this is not the best way to learn. In 1984, educational psychologist Benjamin Bloom documented what he called the 2 Sigma Problem — students tutored one-on-one performed two full standard deviations better than those in a traditional classroom. The results were unambiguous. The problem was never the method. The problem was always the scale.
One-on-one tutoring is labor-intensive, prohibitively expensive, and inaccessible to most of the world’s students. Until now.
When Google announced the Gemini Live Agent Challenge, I realized the boundaries of what is possible had genuinely shifted. The technology to solve the 2 Sigma Problem at scale finally exists — not as another static chatbot or a simple text interface, but as a Living Multimodal Agent. This is the story of Shivy AI: an expert tutor that sees your textbook, hears your voice, corrects your handwriting, and guards your focus.
Moving Beyond the Chatbox
Before writing a single line of code, I spent weeks thinking carefully about what the tutoring experience actually is. If you sit down with a world-class human tutor, the interaction is almost never confined to text. You are not typing questions into a box. You are pointing at diagrams. You are expressing confusion through your face before you have even found the words for it. You are working on physical paper with a real pen.
A great tutor is perceptive in ways that go far beyond answering questions. They notice when you pause on a difficult paragraph. They see your eyes glaze over when a concept is too abstract. They look at your handwriting mid-problem and catch a carrying error before you have even finished the equation.
To build Shivy AI, I had to abandon the input-response paradigm entirely and design for something harder to define: a context-aware relationship. A tutor that lives alongside the student, not just in front of them.
Reimagining the Study Session
To understand what Shivy AI actually does, it helps to follow a student through a real session. Meet Alex — a visual learner studying Advanced Biology, easily overwhelmed by dense chapters and easily pulled away by notifications. Here is how the experience unfolds.
Alex opens Shivy AI and drags a 400-page PDF into the left panel. A traditional AI tutor would index the text for search. Shivy AI does something fundamentally different: it looks at the page alongside Alex. Using PDF.js and a custom canvas synchronization engine, the AI knows exactly what page Alex is on. As Alex navigates to the chapter on Cellular Respiration, Shivy speaks without waiting for a prompt. “Hi Alex! I see we’re diving into the mitochondria today. That diagram on the right showing the Electron Transport Chain is quite dense — should we break that down visually, or would you like to start with the glossary?”
Alex asks Shivy to read along. This is not a text-to-speech engine — it is a coach. Shivy reads a paragraph, stops, and probes for understanding. “The book mentions Active Transport here. That is a key concept for your upcoming quiz. Do you want to try a quick three-question MCQ, or should I explain it like you are five?” When Alex agrees, Shivy does not ask which tool to use. It simply decides, triggering the quiz generator autonomously. An interactive quiz slides onto the screen. Alex answers by voice. Shivy listens not just for the correct answer but for the confidence behind it, adjusting the next explanation based on what it hears.
Ten minutes in, Alex’s phone pings. Attention drifts. Most educational apps sit silent. Shivy AI, continuously receiving optimized webcam frames, notices within seconds. It does not scold. It encourages. “Hey Alex, I noticed your focus is slipping. Let’s finish this one diagram and then we can take a five-minute Brain Break — you are almost at 90% mastery for this chapter.” That gentle nudge, powered by real-time vision, is exactly what a human teacher would do.
The centerpiece feature, though, is what I call Dictation Homework. Shivy reads out complex vocabulary — Mitochondria, Adenosine Triphosphate, Cytokinesis — and Alex writes each word down on physical paper with a real pen. Then Shivy says, “Okay Alex, hold your paper up to the camera.” Alex does. Through the Gemini Live vision engine, Shivy reads the handwritten ink directly, understanding spelling errors rather than just scanning characters. “Great job on the first two. But look at Mitochondria — you wrote an ‘a’ instead of an ‘o’ in the middle. Common mistake. Go ahead and fix that on your paper.” That level of digital-physical integration was simply not possible twelve months ago.
Engineering the Agentic Engine
Building an application that manages high-fidelity audio, continuous video, and autonomous tool execution inside a single browser window is fundamentally an orchestration problem. Every architectural decision in the stack had to serve the conversation.
The foundation is the Gemini 2.5 Flash Native Audio model, and the word “native” is what makes the difference. Conventional voice AI is built on a pipeline: audio comes in, gets converted to text, the text goes to the model, a response comes back as text, and then text gets converted back to audio. That chain introduces latency at every link — often two to four seconds end to end — and it strips out everything that makes speech human: the tone, the pauses, the emotion. By connecting directly to the Gemini Live API using the Google GenAI SDK, I created a direct-to-Google audio loop. Audio goes in as raw PCM and comes back as raw PCM. The result is sub-100ms latency and true zero-latency barge-in: Alex can interrupt Shivy mid-sentence, and it stops, listens, and adjusts instantly.
The hardest technical challenge was what I started calling the WebSocket Clog. Streaming high-resolution webcam frames alongside a constant feed of high-fidelity audio in a single connection is a bandwidth competition, and the video was consistently winning — delaying audio packets and causing stuttering. The fix was a custom canvas-based vision pre-processor in the frontend. Every webcam frame is resized to 480 pixels and compressed to 25% JPEG quality, keeping each payload under 20KB. That one optimization was the make-or-break moment for the experience. The AI’s voice stays crystal clear even while the vision engine is actively reading handwriting from across the room.
The third challenge was tool execution. In a standard agentic system, calling a tool is a blocking operation — the AI waits for the backend to finish before it can keep talking, and the conversation freezes. I solved this with what I now call the Decoupled Tool Acknowledgment pattern. The moment Shivy decides to call a tool, the frontend immediately sends a success signal back to Gemini before the tool has even finished executing. This unblocks the AI’s conversational thread. It keeps talking — “Sure, let me draw that for you…” — while the backend handles the generation in parallel. The interaction never feels robotic.
Why Google Cloud
A great AI that cannot scale is just a demo. Shivy AI is built entirely on the Google Cloud stack for exactly that reason.
The backend is a FastAPI application hosted on Google Cloud Run, which handles sudden CPU bursts from image processing and tool execution while scaling to zero between sessions — keeping costs low without sacrificing performance. API keys and sensitive environment variables never touch the codebase; they are managed entirely through Google Secret Manager, protected by enterprise-grade encryption and IAM roles. And using Google Cloud Build with Artifact Registry, I set up a one-click deployment pipeline: every push to GitHub automatically builds the Docker container, scans it for vulnerabilities, and deploys to Cloud Run. During the hackathon, that pipeline let me iterate on problems in real time without slowing down.
Here is the section, written as clean prose:
The Architecture
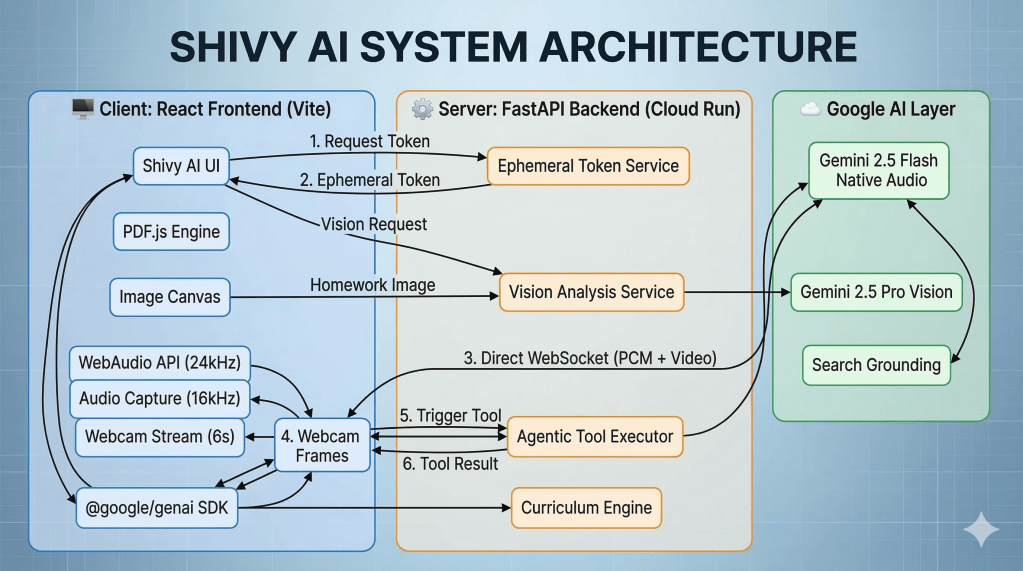
Shivy AI is built across three distinct layers that work in concert to deliver a seamless real-time experience: a React frontend, a FastAPI backend running on Google Cloud Run, and the Google AI layer that powers the intelligence.
Every session begins with a security handshake. The React frontend, built with Vite, makes its first call not to Gemini but to the Ephemeral Token Service running on Cloud Run. The backend generates a short-lived token and returns it to the client. This means a raw API key never touches the browser at any point — the token expires, the session closes, and nothing sensitive is ever exposed on the client side.
Once the token is in hand, the frontend establishes a direct WebSocket connection to Gemini 2.5 Flash Native Audio. From this point forward, two streams travel through that single pipe simultaneously: Audio Capture at 16kHz going in, and the WebAudio API playing back the response at 24kHz. Alongside the audio, the Webcam Stream sends compressed frames every six seconds, captured through a canvas-based pre-processor and kept under 20KB per frame so the video never competes with the audio for bandwidth.
The PDF.js Engine and Image Canvas sit alongside the audio pipeline in the frontend, handling the document layer. When Alex navigates to a new page in the textbook, the canvas sends the current page view as a Vision Request to the Vision Analysis Service on the backend. When Alex holds up handwritten homework, the Image Canvas captures that frame as a Homework Image and routes it through the same service. Both paths terminate at Gemini 2.5 Pro Vision, which handles the deeper visual reasoning — reading page layouts, understanding diagram structure, and correcting handwritten spelling errors.
When Gemini decides to call a tool mid-conversation — generating a quiz, pulling a diagram, or triggering a curriculum step — the signal flows from the Google AI layer to the Agentic Tool Executor on the backend. The executor runs the tool and returns the result to the frontend, while the Curriculum Engine maintains the state of the session: what has been covered, what mastery levels look like, and what comes next.
The third component in the Google AI layer is Search Grounding, which gives Shivy AI the ability to anchor its explanations in verified, current information rather than relying solely on the model’s training data — particularly useful when a student asks about something that extends beyond the textbook.
The entire backend — the Token Service, Vision Analysis Service, Agentic Tool Executor, and Curriculum Engine — runs on Google Cloud Run, which scales automatically with demand and drops to zero between sessions. API keys and environment secrets are managed through Google Secret Manager and never appear in the codebase. Deployments are handled through Google Cloud Build and Artifact Registry, so every push to GitHub builds, scans, and ships a fresh container without manual intervention.
What Comes Next
Shivy AI is a proof of concept, but the direction it points is clear. The next version will push further into affective computing — using the webcam to detect micro-fluctuations in skin tone through rPPG, measuring a student’s actual stress levels before they voice any frustration. A collaborative whiteboard where the student and Shivy AI draw on the same virtual surface in real time over WebSocket is on the roadmap. Further out, I want to explore peer-to-peer AI knowledge networks, where students’ agents connect and facilitate genuine collaborative study sessions.
The deeper shift is philosophical. We are living through a moment where the science fiction of our childhood is becoming the educational reality of our children. Shivy AI moves the AI tutor out of the chat window and into the physical environment. It sees what you see. It hears what you hear. It meets you in the room where you are actually studying.
I built this for the Gemini Live Agent Challenge to push the absolute limits of the Gemini Live API and Google Cloud. The future of school is not a classroom and it is not a lecture. It is a conversation — and that conversation is powered by Gemini.
Check out the Hackathon here : https://devpost.com/software/klassbookai
#GeminiLiveAgentChallenge
Discover more from SkillWisor
Subscribe to get the latest posts sent to your email.
