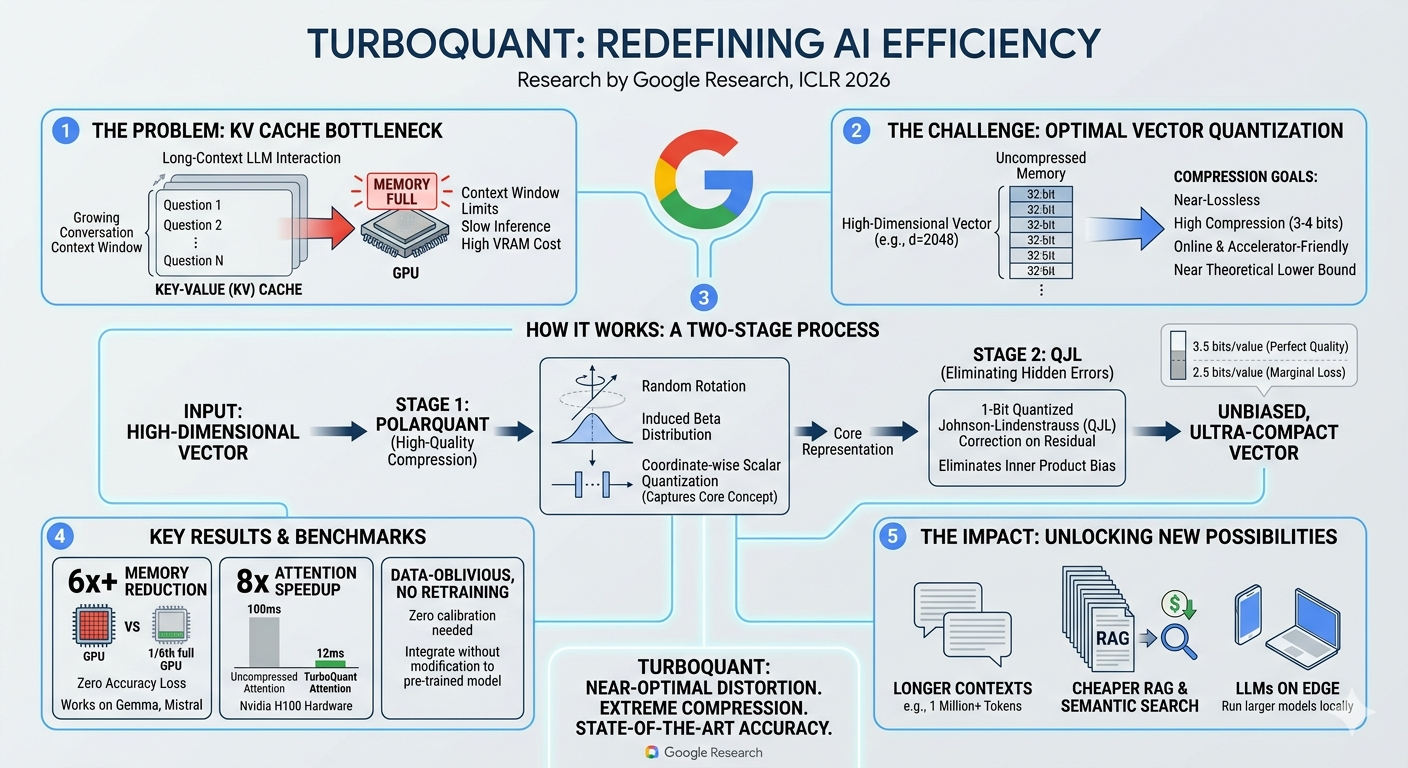
TinyLLM with Attention Residuals: Why Every Modern LLM Has a Hidden Flaw (And How to Fix It)
Every modern LLM you use today — GPT-4, Claude, Gemini, LLaMA — has something in common that almost nobody talks about.

They all use the same residual connection design that was introduced back in 2017.
And a brand-new paper published in March 2026 by the Kimi Team at Moonshot AI argues that this design has a fundamental flaw — and proposes a better way.

Subscribe to continue reading
Subscribe to get access to the rest of this post and other subscriber-only content.