
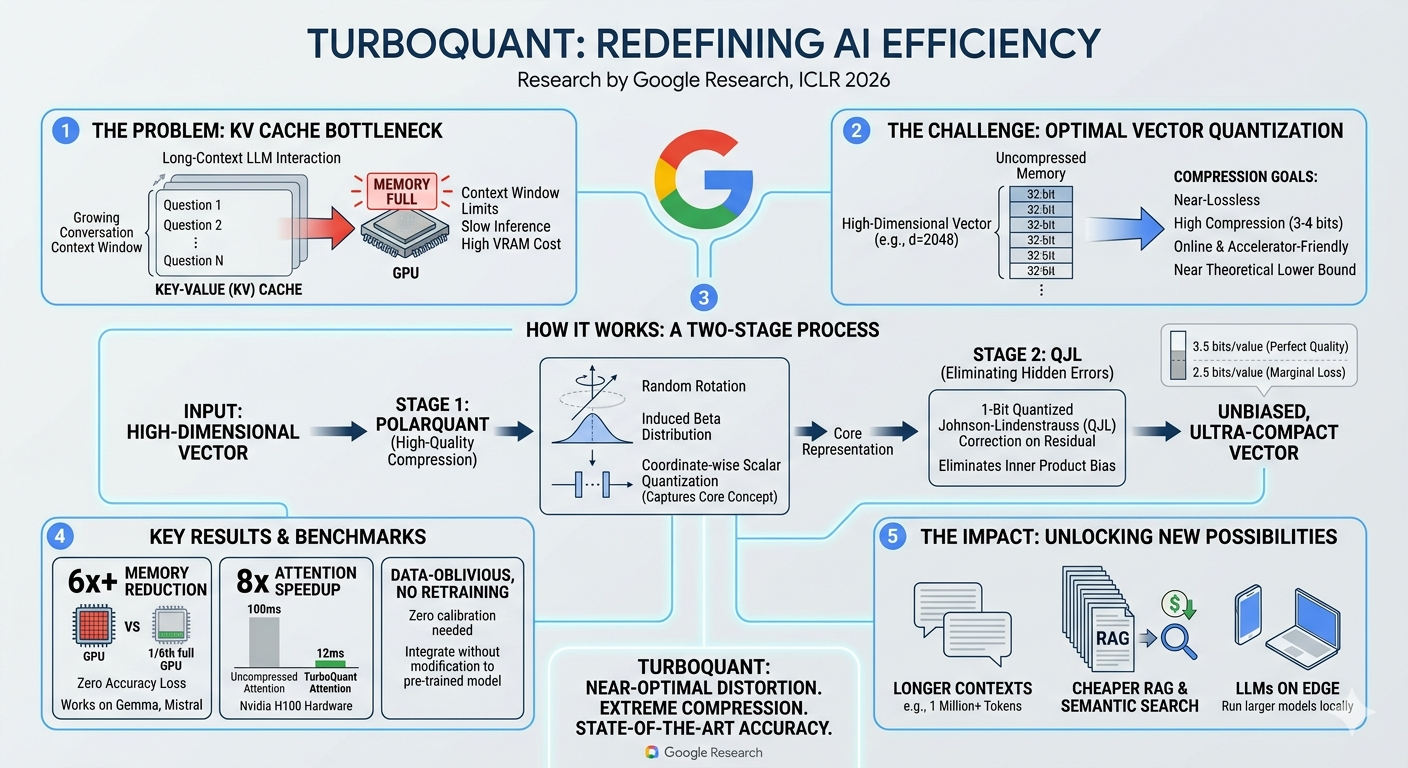

As Large Language Models (LLMs) continue to scale, developers are hitting a massive wall: the KV (Key-Value) cache bottleneck. We want our AI assistants to remember entire books, massive codebases, and months of conversation history. But as the context window grows, the memory required to store these high-dimensional vectors skyrockets, overwhelming GPU VRAM, throttling inference speeds, and driving up compute costs.
Enter TurboQuant, a groundbreaking new method from Google Research (presented at ICLR 2026) that redefines AI efficiency. By achieving near-optimal vector quantization, TurboQuant effectively neutralizes the KV cache bottleneck without sacrificing model accuracy or requiring costly retraining.
Here is a deep dive into how TurboQuant works and why it represents a paradigm shift in generative AI deployment.
The Problem: The Unrelenting KV Cache
During an LLM conversation, the model stores past tokens in the Key-Value (KV) cache to avoid recomputing them. As a conversation grows—say, toward a 1-million token context—this cache balloons.
For high-dimensional vectors (often d=2048 or higher) stored in uncompressed 32-bit formats, the GPU simply runs out of memory. The results are severe context window limits, sluggish response times, and exorbitant hardware costs. The challenge for researchers has been finding a way to compress these vectors to 3-4 bits (near the theoretical lower bound) online, while remaining friendly to hardware accelerators and preserving “near-lossless” quality.
How TurboQuant Works: A Two-Stage Masterclass
TurboQuant approaches this high-dimensional vector compression through a highly innovative, two-stage process that systematically captures the core concept of the data and then eliminates any residual mathematical errors.
Stage 1: PolarQuant (High-Quality Compression)
The first stage takes the input high-dimensional vector and applies PolarQuant.
- The Process: It applies a random rotation to the vector, inducing a predictable Beta distribution.
- The Quantization: It then performs coordinate-wise scalar quantization.
- The Result: This stage successfully captures the core representation of the vector, drastically reducing its size, but leaves behind minor mathematical distortions.
Stage 2: QJL (Eliminating Hidden Errors)
To achieve near-lossless quality, TurboQuant introduces a cleanup phase.
- The Process: It applies a 1-Bit Quantized Johnson-Lindenstrauss (QJL) correction on the residual data left over from Stage 1.
- The Result: This critical step eliminates inner product bias—the hidden errors that typically degrade the performance of compressed models.
The Output: An unbiased, ultra-compact vector. TurboQuant achieves perfect quality at just 3.5 bits per value, and marginal, acceptable loss at extreme compression rates of 2.5 bits per value.
The Benchmarks: State-of-the-Art Performance
The architectural elegance of TurboQuant translates into jaw-dropping real-world performance metrics:
- 6x+ Memory Reduction: TurboQuant cuts the required GPU memory footprint to just 1/6th of its original size with zero accuracy loss. It has been proven to work seamlessly on popular open weights like Gemma and Mistral.
- 8x Attention Speedup: On top-tier hardware like the Nvidia H100, uncompressed attention operations taking 100ms are slashed to a mere 12ms.
- Data-Oblivious & Plug-and-Play: Perhaps the most developer-friendly feature of TurboQuant is that it requires no retraining and zero calibration. It can be integrated directly into pre-trained models immediately, saving thousands of hours of compute time.
The Impact: Unlocking New AI Possibilities
By solving the KV cache bottleneck, TurboQuant doesn’t just make existing systems cheaper; it unlocks entirely new use cases:
- Massive Context Windows: Models can now realistically process 1 Million+ tokens interactively without requiring server farms of H100s.
- Cheaper RAG & Semantic Search: Retrieval-Augmented Generation relies heavily on vector storage and comparison. TurboQuant massively drives down the infrastructure costs of enterprise search and RAG pipelines.
- LLMs on the Edge: By drastically lowering the memory footprint, much larger and more capable LLMs can now be run locally on consumer hardware, laptops, and even mobile devices.
Conclusion
With near-optimal distortion and extreme compression, TurboQuant represents a massive leap forward in the quest to make AI highly capable, remarkably fast, and universally accessible. As we push toward multi-million token contexts and edge-native AI, Google’s two-stage quantization approach provides the exact structural foundation the industry needs.


Leave a Reply